





Логика и вероятность
Впервые опубликовано 7 марта 2013 года.
Логика и теория вероятностей являются двумя основными инструментами формального изучения мышления и плодотворно применяются в таких разнообразных областях, как философия, искусственный интеллект, когнитивные науки и математика. В этой статье рассматриваются основные предложения по объединению логики и теории вероятностей, а также делается попытка классификации различных подходов в этой быстро развивающейся области.
Совмещение логики и теории вероятностей
Сама идея объединения логики и теории вероятности на первый взгляд может показаться странной (Hájek 2001). В конце концов, логика имеет дело с абсолютно достоверными истинами и выводами, тогда как теория вероятностей имеет дело с неопределенностями. Вдобавок логика предлагает качественный (структурный) взгляд на вывод (дедуктивная валидность аргумента основана на его формальной структуре), тогда как вероятности имеют количественную (числовую) природу. Однако, как будет показано в следующем разделе, в некоторых смыслах теория вероятностей предполагает и расширяет классическую логику. Более того, с точки зрения истории некоторые выдающиеся теоретики, такие как де Морган (De Morgan 1847), Буль (Boole 1854), Рамсей (2003 [1926]), де Финетти (de Finetti 1937), Карнап (Carnap 1950), Джеффри (Jeffrey 1992) и Хоусон (Howson 2003, 2007, 2009), подчеркивали тесную связь между логикой и вероятностью или даже рассматривали свои работы на тему вероятности как часть самой логики.
Вероятностные логики, объединяя взаимодополняющие перспективы качественной логики и числовой теории вероятностей, способны предложить весьма выразительные теории вывода. Поэтому неудивительно, что они применялись во всех областях, изучающих механизмы рассуждения, таких как философия, искусственный интеллект, когнитивные науки и математика. Недостатком этой междисциплинарной популярности является то, что такие понятия, как «вероятностная логика», используются разными исследователями различными и неэквивалентными образами. Поэтому, прежде чем перейти к собственно обсуждению разных подходов, мы сначала обрисуем предмет этой статьи.
Самое важное различие — это различие между вероятностной логикой и индуктивной логикой. Традиционно аргумент (дедуктивно) валиден тогда и только тогда, когда невозможно, чтобы все посылки A были истинны, в то время как заключение ложно. Другими словами, дедуктивная валидность сводится к сохранению истины: в валидном аргументе истинность посылок гарантирует истинность заключения. Однако в некоторых аргументах истинность посылок не всегда гарантирует истинность заключения, но все же делает ее весьма вероятной. Типичным примером является аргумент с посылками «первый лебедь, которого я видел, белый», …, «1000-й лебедь, которого я видел, белый» и выводом «все лебеди белые». Такие аргументы изучаются в индуктивной логике, которая широко использует вероятностные понятия и поэтому рассматривается некоторыми авторами как имеющая отношение к вероятностной логике. Дискуссия о точном соотношении между индуктивной логикой и вероятностной логикой кратко изложена во введении Кибурга (Kyburg 1994). Главная позиция (защищаемая среди других Адамсом и Левиным (Adams and Levine 1975)), также принятая и в этой статье, заключается в том, что вероятностная логика целиком является частью дедуктивной логики и, следовательно, не должна быть связана с индуктивными рассуждениями. Тем не менее большая часть работ по индуктивной логике относится к подходу «сохранения вероятности» и, таким образом, тесно связана с системами, обсуждаемыми в разделе 2. Для получения дополнительной информации об индуктивной логике читатель может обратиться к работам Фительсона (Fitelson 2006), Ромейна (Romeijn 2011) и статья о проблеме индукции и индуктивной логике в настоящей энциклопедии.
Мы также будем избегать философских дискуссий о точной природе вероятности. Обсуждаемые здесь формальные системы совместимы со всеми общими интерпретациями вероятности, но очевидно, что в конкретных случаях некоторые интерпретации вероятности будут более естественны, чем другие. Например, модальные вероятностные логики, обсуждаемые в разделе 4, сами по себе нейтральны в отношении природы вероятности, но когда они используются для описания поведения системы в переходном состоянии, их вероятности обычно интерпретируются объективным образом, тогда как моделирование мультиагентных сценариев наиболее естественно сопровождается субъективной интерпретацией вероятностей (как степени убежденности субъекта). Эта тема подробно освещена в работах Гиллиса (Gillies 2000), Игла (Eagle 2010), а также в статье об интерпретациях вероятности в настоящей энциклопедии.
Наконец, хотя успех вероятностной логики в значительной степени обусловлен ее различными приложениями, мы не будем подробно их рассматривать. Например, мы не будем оценивать использование вероятности как формальной репрезентации убеждения в философии (байесовская эпистемология) или в области ИИ (репрезентация знания), а также ее преимущества и недостатки по отношению к альтернативным представлениям, таким как обобщенная теория вероятностей (для квантовой теории) и нечеткая логика. Для получения дополнительной информации об этих темах читатель может обратиться к работам Gerla 1994, Vennekens et al. 2009, Hájek and Hartmann 2010, Hartmann and Sprenger 2010 и статьям о формальных репрезентациях убеждений, байесовской эпистемологии, пересматриваемых рассуждениях, квантовой логике и теории вероятностей, а также нечеткой логике в настоящей энциклопедии.
Теперь, с учетом этих пояснений, мы готовы рассмотреть то, что будет обсуждаться в этой статье. Наиболее распространенная стратегия для получения конкретной системы вероятностной логики состоит в том, чтобы начать с классической (пропозициональной/модальной/etc) системы логики и «овероятностить» ее тем или иным образом, добавляя к ней вероятностные признаки. Существуют различные способы реализации подобной пробабилизации. Можно изучать вероятностную семантику для классических языков логики (которые не имеют эксплицитных вероятностных операторов), и в этом случае само отношение следствия приобретает вероятностный оттенок: дедуктивная валидность становится «сохранением вероятности», а не «сохранением истинности». Это направление будет обсуждаться в разделе 2. В качестве альтернативы можно добавить в синтаксис логики различные виды вероятностных операторов. В разделе 3 мы обсудим некоторые начальные, довольно простые примеры вероятностных операторов. Полная выразительность модальных вероятностных операторов будет рассмотрена в разделе 4. Наконец, языки с вероятностными операторами первого порядка будут рассмотрены в разделе 5.
Пропозициональная вероятностная логика
В этом разделе мы рассмотрим первое семейство вероятностных логик, которые используются для изучения вопросов «сохранения вероятности» (или же «распространения неопределенности»). В этих системах язык не расширяется какими-либо вероятностными операторами — скорее, они имеют дело с «классическим» пропозициональным языком L, который имеет счетное множество атомарных пропозиций и обычные истинностно-функциональные (булевы) связки.
Основная идея заключается в том, что посылки валидного аргумента могут быть неопределенными, и в этом случае (дедуктивная) валидность не накладывает никаких условий на (не)определенность заключения. Например, аргумент с посылками «если завтра пойдет дождь, я промокну» и «завтра пойдет дождь», и заключением «я промокну» валиден, но если его вторая посылка не определена, то и заключение, как правило, также будет неопределенным. Пропозициональные вероятностные логики представляют такие неопределенности как вероятности и изучают, как они «текут» от посылок к заключению; иными словами, в них изучается не сохранение истины, а скорее сохранение вероятности. В следующих трех подразделах обсуждаются системы, которые имеют дело со все более общими версиями этой проблемы.
Вероятностная семантика
Начнем с того, что вспомним понятие вероятностной функции для пропозиционального языка L. (В математике вероятностные функции обычно определяются для σ-алгебры подмножеств данного множества Ω и должны удовлетворять счетной аддитивности; ср. подраздел 4.3 настоящей статьи. Однако в логических контекстах часто более естественно определять вероятностные функции «непосредственно» для объектного языка логики (Williamson 2002). Поскольку этот язык является финитным — все его формулы имеют конечную длину — достаточно соответствия условию конечной аддитивности.) Вероятностная функция (для L) — это функция P : L→ ℝ, удовлетворяющая следующим ограничениям:
Неотрицательность
P(ϕ) ≥ 0 для любых ϕ ∈ L.
Тавтологии
Если ⊧ ϕ, то P (ϕ) = 1.
Конечная аддитивность
Если ⊧ ¬(ϕ ∧ ψ), то P(ϕ ∨ ψ) = P(ϕ) + P(ψ).
Во втором и третьем ограничениях символ ⊧ обозначает (семантическую) валидность в классической пропозициональной логике. Таким образом, определение вероятностных функций требует понятий из классической логики, и в этом смысле можно сказать, что теория вероятностей предполагает классическую логику (Adams 1998: 22). Можно легко показать, что если P удовлетворяет этим ограничениям, то P(ϕ) ∈ [0,1] для любых формул ϕ ∈ L и P(ϕ) = P(ψ) для любых формул ϕ, ψ ∈ L, которые логически эквивалентны (т.е. таких, что ⊧ ϕ ↔ ψ).
Теперь мы обратимся к вероятностной семантике, определенной в работе Лебланка (Leblanc 1983). Аргумент с посылками Γ и выводом ϕ — далее обозначаемый как (Γ, ϕ) — считается вероятностно валидным, записанным Γ ⊧p ϕ, тогда и только тогда, когда
для всех вероятностных функций P: L→ ℝ:
если P(γ) = 1 для любого γ ∈ Γ, тогда также P(ϕ) = 1.
Таким образом, вероятностная семантика заменяет означивания v : L→{0,1} классической пропозициональной логики вероятностными функциями P : L→ ℝ, принимающими значения в реальном единичном интервале [0,1]. Следовательно, классические истинностные значения истина (1) и ложь (0) можно рассматривать как конечные точки единичного интервала [0,1]; схожим образом оценки v : L→{0,1} можно рассматривать как вырожденные вероятностные функции P : L→ [0,1]. В этом смысле классическая логика является частным случаем вероятностной логики — или, что эквивалентно, вероятностная логика является расширением классической логики.
Можно показать, что классическая пропозициональная логика является (сильно) обоснованной (sound) и полной по отношению к вероятностной семантике:
Γ ⊧p ϕ тогда и только тогда, когда Γ ⊢ ϕ.
Некоторые авторы интерпретируют вероятности как обобщенные значения истинности (Reichenbach 1949; Leblanc 1983). Согласно этой точке зрения, вероятностная логика — это всего лишь особый вид многозначной логики, а вероятностная валидность сводится к «сохранению истины»: истина (вероятность 1) переносится от посылок к заключению. Другие логики, такие как Тарский (Tarski 1936) и Адамс (Adams 1998: 15), отмечали, что вероятности нельзя рассматривать как обобщенные значения истинности, поскольку функции вероятности не являются «экстенсиональными»; например, P(ϕ ∧ ψ) не может быть выражено как функция P(ϕ) и P(ψ). Более подробное обсуждение этой темы можно найти в Hailperin 1984.
Другая возможность заключается в интерпретации вероятности утверждения как меры его (не)определенности. Например, утверждение «Джонс сейчас находится в Испании» может иметь любую степень определенности от 0 (максимальная неопределенность) до 1 (максимальная определенность). (Обратите внимание, что 0 на самом деле является своего рода определенностью, а именно определенностью ложности, однако в этой записи мы следуем терминологии Адамса (Adams 1998: 31) и интерпретируем 0 как максимальную неопределенность.) Согласно этой интерпретации, из сильной обоснованности и полноты вероятностной семантики следует следующая теорема:
Теорема 1. Рассмотрим дедуктивно валидный аргумент (Γ, ϕ). Если все посылки в Γ имеют вероятность 1, то заключение ϕ также имеет вероятность 1.
Эту теорему можно рассматривать как первое, очень неполное разъяснение вопроса о сохранении вероятности (или распространении неопределенности). Она гласит, что если не существует никакой неопределенности относительно посылок, то не может быть никакой неопределенности и относительно заключения. В следующих двух подразделах мы рассмотрим более интересные случаи, когда у посылок существует ненулевая неопределенность, и спросим, как она переносится на заключение.
Наконец, следует отметить, что хотя в этом подразделе обсуждается только вероятностная семантика для классической пропозициональной логики, существуют также вероятностные семантики для множества других логик, таких как интуитивистская пропозициональная логика (van Fraassen 1981b; Morgan and Leblanc 1983), модальные логики (Morgan 1982a, b, 1983; Cross 1993), классическая логика первого порядка (Leblanc 1979, 1984; van Fraassen 1981b), релевантная логика (van Fraassen 1983) и немонотонная логика (Pearl 1991). Все эти системы имеют общую ключевую особенность: семантика логики вероятностна по своей природе, но вероятности не репрезентированы эксплицитно в объектном языке; следовательно, они гораздо ближе по своей природе к логике вероятностных утверждений, обсуждаемой здесь, чем к системам, представленным в последующих разделах.
Большинство этих систем основаны не на одноместных вероятностях P(Φ), а скорее на кондициональных вероятностях P (ϕ, ψ). Кондициональная вероятность P(ϕ, ψ) принимается как неразложимая (а не определяется как P(ϕ ∧ψ) / P(ψ), как это обычно делается), чтобы избежать проблем при P(ψ) = 0. Гусенс (Goosens 1979) приводит обзор различных аксиоматизаций теории вероятностей в терминах таких примитивных понятий кондициональной вероятности.
Вероятностная логика Адамса
В предыдущем подразделе мы обсуждали первый принцип сохранения вероятности, который гласит, что если все посылки имеют вероятность 1, то заключение также имеет вероятность 1. Конечно, когда посылки менее чем абсолютно определены, возникают более интересные случаи. Рассмотрим валидный аргумент с посылками p ∨ q и p → q, а также заключение q (символ → обозначает истинностно-условную материальную импликацию). Можно легко показать, что
P(q) = P(p ∨ q) + P(p → q) − 1.
Другими словами, если мы знаем вероятности посылок аргумента, то можем вычислить точную вероятность его заключения и тем самым дать полный ответ на вопрос о сохранении вероятности для данного конкретного аргумента (например, если P(p ∨ q) = 6/7 и P(p → q) = 5/7, то P(q) = 4/7). В общем случае, однако, невозможно вычислить точную вероятность заключения, учитывая вероятности посылок; скорее, лучшее, на что мы можем надеяться, — это (жесткая) верхняя и/или нижняя граница вероятности вывода. Теперь мы обсудим методы Адамса (Adams 1998) для вычисления таких границ.
Результаты Адамса легче сформулировать в терминах неопределенности, нежели определенности (вероятности). При функции вероятности P: L→ [0,1], соответствующая функция неопределенности UP определяется как
UP : L → [0,1] : ϕ ↦ UP(ϕ) := 1 − P(ϕ).
Если функция вероятности P ясна из контекста, мы часто просто пишем U вместо UP. В оставшейся части этого подраздела (и в следующем разделе) мы будем считать, что все аргументы имеют только конечное число посылок (что не является существенным ограничением, учитывая свойство компактности классической пропозициональной логики). Первый основной результат Адамса (который был первоначально установлен в Suppes 1966) теперь можно сформулировать следующим образом:
Теорема 2. Рассмотрим валидный аргумент (Γ, ϕ) и вероятностную функцию P. Тогда неопределенность заключения ϕ не может превышать суммы неопределенностей посылок γ ∈ Γ. Формально:
U(ϕ) ≤ ∑ γ∈Γ U(γ).
Прежде всего заметим, что теорема 1 становится частным случаем этой теоремы: если P(γ) = 1 для любых γ ∈ Γ, тогда U(γ) = 0 для любых γ ∈ Γ, поэтому U(ϕ) ≤ ∑ U(γ) = 0 и, следовательно, P(ϕ) = 1. Кроме того, заметим, что верхняя граница неопределенности вывода зависит от |Γ|, то есть от количества посылок. Если у валидного аргумента небольшое число посылок, каждая из которых имеет только малую неопределенность (высокую определенность), то его заключение также будет иметь достаточно малую неопределенность (достаточно высокую определенность). И наоборот, если у валидного аргумента имеются посылки с небольшими неопределенностями, то его заключение может быть весьма неопределенным только в том случае, если аргумент имеет большое число посылок (знаменитая иллюстрация этого обратного принципа — парадокс лотереи Кибурга (Kyburg 1965), который обсуждается в статье об эпистемических парадоксах). Чтобы поставить вопрос более конкретно, обратите внимание, что если у валидного аргумента три посылки, каждая из которых имеет неопределенность 1/11, то добавление посылки, которая также имеет неопределенность 1/11, не повлияет на валидность аргумента, но поднимет верхнюю границу неопределенности вывода с 3/11 до 4/11 — таким образом, позволяя выводу быть более неопределенным, чем до того. Наконец, верхняя граница, предусмотренная теоремой 2, является оптимальной в том смысле, что (при правильных условиях) неопределенность вывода может совпадать с его верхней границей ∑U (γ):
Теорема 3. Рассмотрим валидный аргумент (Γ, ϕ), и предположим, что множество посылок Γ непротиворечиво и что каждая посылка γ ∈ Γ релевантна (т.е. Γ −{γ}⊭ϕ). Тогда существует такая функция вероятности P : L→ [0,1], что
UP(ϕ) = ∑ γ∈Γ UP(γ).
Верхняя граница, предусмотренная теоремой 2, также может быть использована для определения вероятностного понятия валидности. Аргумент (Γ, ϕ) считается вероятностно верным по Адамсу, будучи записанным как Γ ⊧a ϕ, тогда и только тогда, когда
для любой вероятностной функции P : L→ ℝ: UP(ϕ) ≤ ∑ γ∈Γ UP(γ).
Вероятностная валидность по Адамсу имеет альтернативное, эквивалентное описание через вероятности, а не неопределенности. Это описание гласит, что (Γ, ϕ) является вероятностно валидным тогда и только тогда, когда вероятность заключения может стать сколь угодно близка к 1, если вероятности посылок достаточно высоки. Формально: Γ ⊧a ϕ тогда и только тогда, когда
для любого ϵ > 0 существует δ > 0 такое, что для всех вероятностных функций P:
если P(γ) > 1 − δ для любого γ ∈ Γ, то P(ϕ) > 1 − ϵ.
Можно показать, что классическая пропозициональная логика является (сильно) обоснованной и полной по отношению к вероятностной семантике Адамса:
Γ ⊧a ϕ тогда и только тогда, когда Γ ⊢ ϕ.
Адамс (Adams 1998: 154) также определяет другую логику, для которой его вероятностная семантика является обоснованной и полной. Однако эта система включает в себя не-истинностно-функциональную логическую связку (вероятностный кондиционал) и поэтому выходит за рамки данного раздела. (Для получения дополнительной информации о вероятностных интерпретациях кондиционалов читатель может ознакомиться со статьями о кондиционалах и логике кондиционалов.)
Рассмотрим следующий пример. Аргумент A с посылками p, q, r, s и выводом p ∧ (q ∨ r) является валидным. Предположим, что P(p) = 10/11, P(q) = P(r) = 9/11 и P(s) = 7/11. Тогда теорема 2 гласит:
U(p ∧ (q ∨ r)) ≤ 1/11 + 2/11 + 2/11 + 4/11 = 9/11.
Эта верхняя граница неопределенности вывода довольно разочаровывает и обнажает главную слабость теоремы 2. Одна из причин, почему верхняя граница так высока, заключается в том, что для ее вычисления мы учитывали посылку s, которая имеет довольно высокую неопределенность (4/11). Однако эта посылка нерелевантна в том смысле, что вывод уже вытекает из трех других посылок. Следовательно, мы можем рассматривать p ∧ (q ∨ r) не только как вывод из валидного аргумента A, но и как заключение (равно валидного) аргумента A', имеющего посылки p, q, r. В последнем случае теорема 2 дает верхнюю границу 1/11 + 2/11 + 2/11 = 5/11, а это уже гораздо ниже.
Слабость теоремы 2 состоит, таким образом, в том, что она учитывает нерелевантные или несущественные посылки (точнее, их неопределенность). Чтобы получить улучшенную версию этой теоремы, необходимо более градуированное понятие «существенности». В аргументе а в приведенном выше примере посылка s абсолютно нерелевантна. И аналогично, посылка Р абсолютно релевантна в том смысле, что без этой посылки заключение p ∧ (q ∨ r) больше не выводимо. Наконец, подмножество посылок {q, r} находится «посередине»: вместе q и r релевантны (если обе посылки опущены, заключение больше не выводимо), но каждая из них по отдельности может быть опущена (сохраняя заключение выводимым).
Понятие существенности формализуется следующим образом:
Множество существенных посылок.
Для валидного аргумента (Γ, ϕ), множество Γ' ⊆ Γ существенно тогда и только тогда, когда Γ − Γ′⊭ϕ.
Степень существенности.
Для валидного аргумента (Γ, ϕ) и посылки γ ∈ Γ степень существенности γ, записанной E(γ), равна 1 / |Sγ|, где |Sγ| — мощность наименьшего множества существенных посылок, содержащего γ. Если γ не принадлежит какому-либо минимальному множеству существенных посылок, то степень существенности γ равна 0.
С помощью этих определений можно сформулировать уточненную версию теоремы 2:
Теорема 4. Рассмотрим валидный аргумент (Γ, ϕ). Тогда неопределенность заключения ϕ не может превышать взвешенной суммы неопределенностей посылок γ ∈ Γ, где в качестве весов выступают степени существенности. Формально:
U(ϕ) ≤ ∑ γ∈Γ E(γ)U(γ).
Доказательство теоремы 4 значительно сложнее, чем доказательство теоремы 2: теорема 2 требует только базовой теории вероятностей, тогда как теорема 4 доказывается методами линейного программирования (Adams and Levine 1975; Goldman and Tucker 1956). Теорема 4 включает теорему 2 в качестве частного случая: если все посылки релевантны (т.е. имеют степень существенности 1), то теорема 4 даст ту же верхнюю границу, что и теорема 2. Кроме того, теорема 4 не учитывает нерелевантные посылки (т.е. посылки со степенью существенности 0) для вычисления верхней границы; следовательно, если посылка не имеет отношения к валидности аргумента, то ее неопределенность не будет перенесена на заключение. Наконец, заметим, что поскольку E(γ) ∈ [0,1] для всех γ ∈ Γ, то справедливо, что
∑ γ∈Γ E(γ) U(γ) ≤ ∑ γ∈Γ U(γ),
то есть теорема 4 даст в общем случае более строгую верхнюю границу, чем теорема 2. Чтобы проиллюстрировать это, снова рассмотрим аргумент с посылками p, q, r, s и заключением p ∧ (q ∨ r). Напомним, что P(p) = 10/11, P(q) = P(r) = 9/11 и P(s) = 7/11. Можно рассчитать степени существенности посылок: E(p) = 1, E(q) = E(r) = 1/2 и E(s) = 0. Следовательно, теорема 4 дает
U(p ∧ (q ∨ r)) ≤ (1 × 1/11) + (1/2 × 2/11) + (1/2 × 2/11) + (0 × 4/11) = 3/11,
что является более жесткой верхней границей для неопределенности p ∧ (q ∨ r), чем любая из оценок, полученных выше с помощью теоремы 2 (а именно: 9/11 и 5/11).
Дальнейшие обобщения
Учитывая неопределенности (и степени существенности) посылок валидного аргумента, теоремы Адамса позволяют нам вычислить верхнюю границу неопределенности заключения. Конечно, эти результаты также могут быть выражены через вероятности, а не неопределенности; тогда они дают низкую границу вероятности заключения. Например, выраженная в терминах вероятностей, а не неопределенностей, теорема 4 выглядит следующим образом:
P(ϕ) ≥ 1 − ∑ γ∈Γ E(γ)(1 − P(γ)).
Результаты Адамса ограничены по крайней мере двумя способами:
● Они дают только нижнюю границу вероятности вывода (с учетом вероятностей посылок). В некотором смысле это самая важная граница: она репрезентирует вероятность заключения в «наихудшем сценарии», что может оказаться полезной информацией в рамках практических приложений. Однако для некоторых случаев также может быть информативно знать верхнюю границу вероятности вывода. Например, если человек знает, что эта вероятность имеет верхнюю границу 0,4, то он может принять решение воздержаться от определенных действий (которые он совершил бы, если бы эта верхняя граница была (известной как) 0,9).
● Они предполагают, что известны точные вероятности посылок. Однако на практике может быть известна только частичная информация о вероятности посылки γ: ее точное значение неизвестно, но известно, что ее нижняя граница a и верхняя граница b (Walley 1991). В таких случаях было бы полезно иметь метод расчета (оптимальных) нижней и верхней границ вероятности вывода в терминах верхней и нижней границ вероятностей посылок.
Хайлперин (Hailperin 1965, 1984, 1986, 1996) и Нильссон (Nilsson 1986) используют методы линейного программирования, чтобы показать, как эти два ограничения могут быть преодолены. Их самый важный результат заключается в следующем:
Теорема 5. Рассмотрим аргумент (Γ, ϕ), где |Γ| = n. Существуют функции LΓ, ϕ : ℝ2n → ℝ and UΓ, ϕ : ℝ2n → ℝ такие, что для любой функции вероятности P справедливо следующее: если ai ≤ P(γi) ≤ bi при 1 ≤ i ≤ n, , то
1. LΓ, ϕ(a1, …, an, b1, …, bn) ≤ P(ϕ) ≤ UΓ, ϕ(a1, …, an, b1, …, bn).
2. Границы в пункте 1 являются оптимальными в том смысле, что существуют вероятностные функции PL и PU такие, что ai ≤ PL(γi), PU(γi) ≤ bi при 1 ≤ i ≤ n, LΓ, ϕ(a1, …, an, b1, …, bn) = PL(ϕ) и PU(ϕ) = UΓ, ϕ(a1, …, an, b1, …, bn).
3. Функции LΓ, ϕ и UΓ, ϕ эффективно определяются из булевой структуры предложений в Γ ∪ {ϕ}.
Этот результат также может быть использован для определения еще одного вероятностного понятия валидности, которое мы будем называть вероятностной валидностью Хайлперина или просто h-валидностью. Это понятие определяется не по отношению к формулам, а скорее по отношению к парам, состоящим из формулы и подинтервала [0,1]. Если Xi — интервал, связанный с посылкой yi ∈ Γ, а Y — интервал, связанный с заключением ϕ, то аргумент (Γ, ϕ) считается h-валидным и записывается как Γ ⊧h ϕ, тогда и только тогда, когда
для всех вероятностных функций P : если P(γi) ∈ Xi при 1 ≤ i ≤ n, тогда P(ϕ) ∈ Y
В работе Haenni et al. 2011 это записывается так:
γ1 X1, …, γn Xn |≈ ϕY
и называется стандартной вероятностной семантикой.
Работа Нильссона по вероятностной логике (Nilsson 1986, 1993) стала причиной появления множества исследований по вероятностному рассуждению в области ИИ (Hansen and Jaumard 2000; Haenni et al. 2011: ch. 2). Однако следует отметить, что хотя теорема 5 утверждает, что функции LΓ, ϕ и UΓ, ϕ эффективно определимы из утверждений в Γ ∪ {Φ}, вычислительная сложность этой задачи довольно высока (Georgakopoulos et al. 1988, Kavvadias and Papadimitriou 1990), и поэтому нахождение функций быстро становится вычислительно неосуществимым на практике. Современные подходы, основанные на вероятностных системах аргументации и вероятностных сетях, лучше справляются с такими вычислительными задачами. Кроме того, вероятностные системы аргументации тесно связаны с теорией Демпстера — Шейфера (Dempster 1968; Shafer 1976; Haenni and Lehmann 2003). Однако расширенное обсуждение этих подходов выходит за рамки (текущей версии) этой статьи; см. Haenni et al. 2011 для недавнего обзора.
Основные вероятностные операторы
В этом разделе мы рассмотрим вероятностные логики, которые расширяют пропозициональный язык L с помощью довольно простых вероятностных операторов. В подразделе 2.1 рассматриваются качественные вероятностные операторы; в подразделе 2.2 рассматриваются количественные вероятностные операторы.
Качественные представления неопределенности
Существует несколько практических применений, для которых качественные теории вероятности могут быть полезны или даже необходимы. В некоторых ситуациях не существует частот, доступных для использования в качестве оценок вероятностей, или получение таких частот может быть практически невозможно. Кроме того, люди часто желают сравнивать вероятности двух утверждений («ϕ более вероятно, чем ψ»), не будучи в состоянии приписать эксплицитные вероятности каждому из утверждений по отдельности (Szolovits and Pauker 1978; Halpern and Rabin 1987). В таких ситуациях пригодится качественная вероятностная логика.
Одной из самых ранних качественных вероятностных логик является логика Хэмблина (Hamblin 1959). Язык расширяется с помощью одноместного оператора □, который должен читаться как «вероятно». Следовательно, формулу □ϕ следует читать как «вероятно ϕ». Это понятие «вероятного» может быть формализовано как достаточно высокая (численная) вероятность (т.е. P (ϕ) ≥ t для некоторого порогового значения 1/2 < t ≤ 1) или же иным способом в терминах правдоподобия, которое является неметрическим обобщением вероятности. Далее эти системы развивает Берджесс (Burgess 1969), сосредотачиваясь на интерпретации «высокой числовой вероятности». И Хэмблин, и Берджесс вводят в свои системы дополнительные операторы (выражающие, например, метафизическую необходимость и/или знание) и изучают взаимодействие между оператором «вероятно» и другими модальными операторами. Однако оператор «вероятно» уже сам по себе отображает некоторые интересные функции (независимо от любых других операторов). Если он интерпретируется как «достаточно высокая вероятность», то он не удовлетворяет принципу (□ϕ ∧□ψ) → □(ϕ ∧ ψ). Это означает, что он не является нормальным модальным оператором и не может быть задан (реляционной) семантикой Крипке. Херциг и Лонгин (Herzig and Longin 2003) и Арло Коста (Arló Costa 2005) предлагают более слабые системы семантики окрестностей для таких операторов «вероятно», в то время как Ялчин (Yalcin 2010) обсуждает их поведение с более лингвистически ориентированной точки зрения.
Другим маршрутом следуют Сегерберг (Segerberg 1971) и Герденфорс (Gärdenfors 1975a,b). Они используют двуместный оператор ≥; формула ϕ ≥ ψ должна читаться как «ϕ по крайней мере так же вероятно, как ψ» (формально: P(ϕ) ≥ P(ψ)). Ключевая идея заключается в том, что можно полностью охарактеризовать поведение ≥, не прибегая к использованию вероятностей, «лежащих в основе» отдельных формул. Наконец, следует отметить, что при сравнительной вероятности (двуместный оператор) можно также выразить некоторые абсолютные вероятностные свойства (одноместные операторы). Например, ϕ ≥ ⊤ выражает, что ϕ имеет вероятность 1, а ϕ ≥ ¬ϕ выражает, что вероятность ϕ не менее 1/2.
Выражение свойств вероятностей с линейными комбинациями и без них
Семантика пропозициональной вероятностной логики включает в себя вероятностную функцию Р, которая удовлетворяет определенным свойствам. Здесь мы рассматриваем P как оператор в объектном языке. В таком языке можно было бы просто добавить формулы вероятности к пропозициональной логике, такие как P(ϕ) ≥ q, где ϕ — пропозициональная формула. Но заметим, что одним из условий для вероятностной функции является аддитивность: P(ϕ ∨ ψ) = P(ϕ) + P(ψ) всякий раз, когда ¬(ϕ ∧ ψ) является тавтологией. Таким образом, вполне естественно использовать сложение (и, в более общем смысле, линейные комбинации) в вероятностном языке с вероятностными операторами. Но мы увидим, что многое может быть выражено в языке эксплицитно, без линейных комбинаций.
Часто желательно иметь как можно меньше неразложимых (примитивных) определений и выстраивать дальнейшие определения из неразложимых. Это позволяет нам более сжато конкретизировать язык. Давайте сначала посмотрим, что можно выразить с помощью линейных комбинаций основных неразложимых форм. Примем в качестве неразложимых формулы вида a1P(ϕ1) + ⋯ + anP(ϕn) ≥ b, где n — положительное целое число, которое может отличаться от формулы к формуле, и a1, …, an, и b — рациональные числа. Вот несколько примеров того, что можно выразить.
● P(ϕ) ≤ q через − P(ϕ) ≥−q,
● P(ϕ) < q через ¬(P(ϕ) ≥ q),
● P(ϕ) = q через P(ϕ) ≥ q ∧ P(ϕ) ≤ q.
Теперь рассмотрим язык, ограниченный формулами вида P (ϕ) ≥ q для некоторой пропозициональной формулы ϕ и рационального числа q. Заметим, что мы даже не рассматриваем коэффициенты вероятностного терма. Мы можем определить
● P(ϕ) ≤ q через P(¬ϕ) ≥ 1 − q,
что вполне разумно, учитывая, что вероятность дополнения утверждения равна 1 минус вероятность утверждения. Формулы P(ϕ) < q и P(ϕ) = q могут быть определены без использования линейных комбинаций, как это было сделано выше. Используя подобный язык ограниченной вероятности, мы можем рассуждать об аддитивности менее прямолинейно. Формула
[P(ϕ ∧ ψ) = a ∧ P(ϕ ∧¬ψ) = b] → P(ϕ) = a + b
утверждает, что если вероятность ϕ ∧ ψ — это a и вероятность ϕ ∧¬ψ — это b, то вероятность дизъюнкции формул (ϕ ∧ ψ) ∨ (ϕ ∧¬ψ) — что эквивалентно ϕ — это a + b. Однако, хотя использование линейных комбинаций позволяет нам утверждать, что вероятности ϕ ∧ ψ и ϕ ∧ ψ аддитивны благодаря формуле P(ϕ ∧ ψ) + P(ϕ ∧¬ψ) = P(ϕ), формула без линейных комбинаций выше делает это только в том случае, если мы выбираем правильные числа a и b.
В работе Fagin et al. 1990 приводится обоснованная и полная система доказательств для логики, включающей линейные комбинации, где даны аксиомы для линейных комбинаций. В работе Heifetz and Mongin 2001 дается обоснованная и полная система доказательств для логики без линейных комбинаций, где аддитивность разбивается на следствия
[P(ϕ ∧ ψ) ≥ a ∧ P(ϕ ∧¬ψ) ≥ b] → P(ϕ) ≥ a + b,
и утверждается, что вероятность объединения двух непересекающихся множеств есть по меньшей мере сумма нижних границ вероятностей каждого из множеств и
[P(ϕ ∧ ψ) < a ∧ P(ϕ ∧¬ψ) < b] → P(ϕ) < a + b.
Обе эти логики лишены свойства компактности; например, каждое конечное подмножество {P(p) > 0} ∪ {P(p) ≤ a | a > 0} удовлетворяет ему, но не все множество.
Модальная вероятностная логика
Многие вероятностные логики интерпретируются в рамках одного, но произвольного вероятностного пространства. Модальная вероятностная логика использует множество вероятностных пространств, каждое из которых связано с возможным миром или состоянием. Это можно рассматривать как незначительную поправку к реляционной семантике модальной логики: вместо того чтобы связывать множество доступных миров с каждым возможным миром, как это делается в модальной логике, модальная вероятностная логика связывает с каждым возможным миром распределение вероятностей, вероятностное пространство или множество вероятностных распределений. Язык модальной вероятностной логики допускает вложение (embedding) вероятностей в вероятности, то есть можно, например, рассуждать о вероятности того, что (возможно, другая) вероятность равна 1/2. Эта модальная установка, включающая множество вероятностей, обычно интерпретировалась (1) стохастически, относительно различных вероятностей в следующих состояниях, в которые может перейти система (Larsen and Skou 1991), и (2) субъективно, относительно различных вероятностей, которые могут иметь различные агенты в отношении ситуации или вероятностей друг друга (Fagin and Halpern 1988). Обе интерпретации могут использовать совершенно одинаковые формальные аппараты.
Базовая модальная вероятностная логика добавляет к пропозициональной логике формулы вида P(ϕ) ≥ q, где q — обычно рациональное число, а ϕ — любая формула языка, возможно, формула вероятности. Читать такую формулу следует так: вероятность ϕ равна по меньшей мере q. Такое общее прочтение формулы не отражает никакой разницы между модальной вероятностной логикой и другими вероятностными логиками с той же формулой; разница заключается в способности вложения вероятностей в аргументы вероятностных термов и семантику. В следующих подразделах представлен обзор вариантов моделирования модальной вероятностной логики. В одном случае формулировка слегка изменена (подраздел 4.2), а в других случаях логика расширена для рассмотрения взаимодействия между качественной и количественной неопределенностью (подраздел 4.4) или динамикой (подраздел 4.5).
Основные финитные модальные вероятностные модели
Формально базовой финитной модальной вероятностной моделью является кортеж M = (W, P, V), где W — конечное множество возможных миров или состояний, P — функция, связывающая распределение Pw по W с каждым миром w ∈ W, и V — «функция оценивания», приписывающая атомарные пропозиции из множества Φ каждому миру. Распределение аддитивно распространяется от отдельных миров к множествам миров: Pw(S) = ∑s∈SPw(s). Первые два компонента базовой модальной вероятностной модели фактически совпадают с фреймом Крипке, отношение которого декорировано числами (вероятностными значениями). Такая структура имеет различные названия, такие как ориентированный граф с разметкой ребер в математике или вероятностная переходная система в информатике. Функция оценивания, как и в модели Крипке, позволяет нам присваивать свойства мирам.
Семантика формул задана парами (M, w), где M — модель, а w — элемент модели. Формула P(ϕ) ≥ q истинна в паре (M,w), что записывается как (M,w) ⊧ P(ϕ) ≥ q, тогда и только тогда, когда Pw({w′ | (M,w′) ⊧ ϕ}) ≥ q.
Индексация и интерпретации
Первое обобщение, которое наиболее часто встречается в приложениях модальной вероятностной логики, состоит в том, чтобы позволить распределениям индексироваться двумя множествами, а не одним. Первое множество — множество миров W (базовое множество модели), а другое — множество индексов A, которое часто следует рассматривать как множество действий, агентов или игроков в игре. Формально Р связывает распределение Pa,w над W для каждого w ∈ W и a ∈ A. Для языка мы не включаем формулы вида P(ϕ) ≥ q, а имеем Pa(ϕ) ≥ q и (M,w) ⊧ Pa(ϕ) ≥ q тогда и только тогда, когда Pa,w({w′ | (M,w′) ⊧ ϕ}) ≥ q.
Пример: предположим, что у нас есть множество индексов A = {a,b}, и множество атомарных пропозиций Φ = {p,q}. Рассмотрим (W, P, V), где
● W = {w, x, y, z}
●
Pa,w
и Pa,x отображают w на 1/2, x на 1/2, y на 0 и z на 0.
Pa,y и Pa,z отображают y на 1/3, z на 2/3, w на 0 и x на 0.
Pb,w и Pb,y отображают w на 1/2, y на 1/2, x на 0 и z на 0.
Pb,x и Pb,z отображают x на 1/4, z на 3/4, w на 0 и y на 0.
●
V (p) = {w,x}
V (q) = {w,y}.
Мы изобразим этот пример на следующей диаграмме. Внутри каждого круга находится разметка истинности каждого знака пропозиции для мира, название которого помечено прямо за пределами круга. Стрелки указывают на вероятности. Например, стрелка от мира x к миру z, обозначенная (b,3/4) означает, что из х вероятность z под меткой b составит 3/4. Вероятности 0 не помечаются
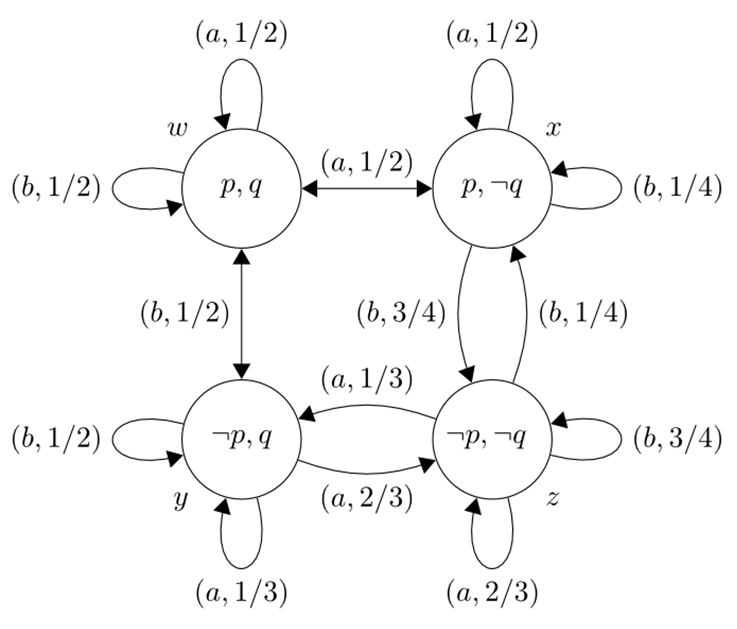
Стохастическая интерпретация: пусть элементы a и b A — это действия, например, нажатие кнопок на машине. В таком случае нажатие кнопки не имеет определенного результата. Например, если машина находится в состоянии x, существует вероятность 1/2, что она останется в том же состоянии после нажатия кнопки a, но также вероятность 1/4, что она останется в том же состоянии после нажатия кнопки B. То есть
(M,x) ⊧ Pa(p ∧¬q) = 1/2 ∧ Pb(p ∧¬q) = 1/4.
Существенной особенностью модальной логики вообще (а это относится и к модальной вероятностной логике) является способность поддерживать рассуждения более высокого порядка, то есть рассуждения о вероятностях вероятностей. Важность вероятностей более высокого порядка очевидна из той роли, которую они играют, например, в принципе Миллера, который утверждает, что P1(ϕ | P2(ϕ) = b) = b. Здесь P1 и P2 — это вероятностные функции, которые могут иметь различные интерпретации, такие как вероятности двух агентов, логические и статистические вероятности или вероятности одного агента в разные моменты времени (Miller 1966; Lewis 1980; van Fraassen 1984; Halpern 1991). Вероятность более высокого порядка также имеет место, например, в проблеме Джуди Бенджамин (van Fraassen 1981a), где одно условие зависит от вероятностной информации. Независимо от того, согласны ли мы с принципами, предложенными в литературе о вероятностях высшего порядка, или нет, способность к их репрезентации заставляет нас исследовать принципы, управляющие ими.
Чтобы более конкретно проиллюстрировать рассуждения более высокого порядка, мы возвращаемся к нашему примеру и видим, что утверждение, что при x существует вероятность 1/2, что после нажатия кнопки a существует вероятность 1/2, что после нажатия кнопки b будет иметь место ¬p будет истинно, то есть
(M,x) ⊧ Pa(Pb(¬p) = 1/2) = 1/2.
Субъективная интерпретация: предположим, что элементы a и b A являются участниками игры. p и ¬p — стратегии игрока a, q и ¬q — стратегии игрока b. В этой модели каждый игрок уверен в своей собственной стратегии; например, в x игрок a уверен, что он будет играть p, а игрок b уверен, что он будет играть ¬q, то есть
(M,x) ⊧ Pa(p) = 1 ∧ Pb(¬q) = 1.
Но игроки произвольно представляют своих соперников. Например, при x вероятность того, что b имеет для a вероятность ¬q, равную 1/2, равна 1/4, то есть
(M,x) ⊧ Pb(Pa(q) = 1/2) = 1/4.
Вероятностные пространства
Вероятности обычно определяются как меры в пространстве мер. Пространством меры является множество Ω (пространство выборки) вместе с σ-алгеброй (также называемой σ-полем) A над Ω, которое представляет собой непустое множество подмножеств Ω таких, что A ∈ A подразумевает, что Ω − A ∈ A, и Ai ∈ A для всех натуральных чисел i подразумевает, что ⋃iAi ∈ A. Мера является функцией μ, определенной по σ-алгебре A такой, что μ(A) ≥ 0 для каждого множества A ∈ A и μ(⋃iAi) = ∑i μ(Ai) в любом случае, если Ai ∩ Aj = ∅ для всех i, j.
Эффект σ-алгебры заключается в ограничении домена так, что не каждое подмножество Ω должно иметь вероятность. Это имеет решающее значение для определения некоторых вероятностей на несчетно бесконечных множествах; например, равномерное распределение на единичном интервале не может быть определено на всех подмножествах интервала, сохраняя при этом условие счетной аддитивности для вероятностных мер.
Тот же базовый язык, который использовался для базовой логики конечных вероятностей, не нуждается в изменении, но его семантика немного отличается: для каждого состояния w ∈ W компонент Pw модальной вероятностной модели заменяется целым вероятностным пространством (Ωw, Aw, μw), таким что Ωw ⊆ W и Aw — это σ-алгебра на Ωw. Причина, по которой мы можем захотеть, чтобы целые пространства отличались от одного мира к другому, заключается в том, чтобы отразить неопределенность относительно того, какое вероятностное пространство является правильным. Для семантики вероятностных формул (M,w) ⊧ P(ϕ) ≥ q тогда и только тогда, когда μw({w′ | (M,w′) ⊧ ϕ}) ≥ q. Такое определение плохо определено в том случае, если {w′ | (M,w′) ⊧ ϕ} ∉ Aw. Таким образом, на модели часто накладываются ограничения, гарантирующие, что такие множества всегда находятся в σ-алгебрах.
Сочетание количественной и качественной неопределенности
Хотя вероятности отражают количественную неопределенность на одном уровне, они также могут быть и качественными. Мы можем пожелать иметь качественную и количественную неопределенность, потому что мы можем быть настолько неуверенными в некоторых ситуациях, что не захотим присваивать числа вероятностям их событий, в то время как существуют другие ситуации, где у нас есть ощущение вероятности их событий; и эти ситуации могут взаимодействовать.
Есть много ситуаций, в которых мы, возможно, не захотим присваивать числовые значения неопределенностям. Один из примеров — это когда компьютер выбирает бит 0 или 1, и мы ничего не знаем о том, как этот бит выбирается. Результаты подбрасывания монетки, с другой стороны, часто используются в качестве примеров того, когда мы могли бы присвоить вероятности отдельным результатам.
Примером их взаимодействия может служить такая ситуация: результат бита определяет, будет ли справедливой или нет (скажем, орел будет выпадать с вероятностью 2/3) монета, используемая при подбрасывании. Таким образом, существует качественная неопределенность относительно того, появится ли орел в результате подбрасывания монеты с вероятностью 1/2 или 2/3.
Одним из способов формализовать взаимодействие между вероятностью и качественной неопределенностью является добавление другого отношения в модель и модального оператора в язык, как это было сделано в работах Fagin and Halpern 1988, 1994. Формально мы добавляем к базовой модели финитной вероятности отношение R ⊆ W2. Затем мы добавим в язык модальный оператор □, такой что(M,w) ⊧ □ϕ, если и только если (M,w′) ⊧ ϕ в случае wRw′.
Рассмотрим следующий пример:
● W = {(0,H), (0,T), (1,H), (1,T)},
● Φ = {h,t} — множество атомарных пропозиций,
● R = W2,
● P ассоциируется с (0,H) и (0,T), где распределение приписывает (0,H) и (0,T) по 1/2, и ассоциируется с (1,H) и (1,T), где распределение приписывает (1,H) по 2/3 и (1,T) по 1/3,
● V приписывает h множеству{(0,H), (1,H)} и t множеству {(0,T), (1,T)}.
Тогда при (0,H) истинна следующая формула: ¬□h ∧ (¬□P(h) = 1/2) ∧ (♢P(h) = 1/2). Ее можно прочесть так: неизвестно, что h истинно, и неизвестно, что вероятность h равна 1/2, но возможно, что вероятность h равна 1/2.
Динамика
Мы обсудили два взгляда на модальную вероятностную логику. Один из них является темпоральным или стохастическим, где распределение вероятностей, связанное с каждым состоянием, определяет вероятность перехода в другие состояния; другой связан с субъективными перспективами агентов, которые могут рассуждать о вероятностях других агентов. Стохастическая система динамична в том смысле, что она представляет собой вероятности различных переходов, что может быть передано самими модальными вероятностными моделями. Но с субъективной точки зрения модальные вероятностные модели статичны: вероятности связаны с тем, что в настоящее время имеет место. Несмотря на статичность их интерпретации, модальная вероятностная установка может быть помещена в динамический контекст.
Динамика в модальной вероятностной установке обычно связана с одновременным изменением вероятностей потенциально во всех возможных мирах. Говоря интуитивно, такое изменение может быть вызвано новой информацией, которая вызывает вероятностный пересмотр в каждом возможном мире. Динамика субъективных вероятностей часто моделируется с использованием кондициональных вероятностей, таких как у Kooi 2003, Baltag and Smets 2008 и van Benthem et al 2009. Вероятность F при условии E, записываемая P(E | F), составит P(E ∩ F) / P(F). При обновлении множеством F распределение вероятностей P заменяется распределением вероятностей P′, таким что P′(E) = P(E | F), пока P(F) ≠ 0. Давайте предположим в рамках остальной части этого раздела о динамике, что каждое рассматриваемое релевантное множество имеет положительную вероятность.
Используя вероятностную логику с линейными комбинациями, мы можем записать кондициональную вероятность P(ϕ | ψ) ≥ q как P(ϕ ∧ ψ) − qP(ψ) ≥ 0. В модальной установке к языку можно добавить оператор [!ψ], такой что M, w ⊧ [!ψ] тогда и только тогда, когда M', w ⊧ ϕ, где M' — модель, полученная из M путем пересмотра вероятностей каждого мира на ψ. Обратите внимание, что [!ψ](P(ϕ) ≥ q) отличается от P(ϕ | ψ) ≥ q тем, что в [!ψ]P(ϕ) ≥ q) интерпретация вероятностных термов ϕ зависит от пересмотра ψ, в то время как в P(ϕ | ψ) ≥ q — нет, поэтому P(ϕ | ψ) ≥ q красиво разворачивается в другую формулу вероятности. Однако [!ψ]ϕ тоже разворачивается, но при большем количестве шагов:
[!ψ](P(ϕ) ≥ q) ↔ (ψ → P([!ψ] ϕ | ψ) ≥ q).
Вероятностная логика первого порядка
В этом разделе мы обсудим вероятностную логику первого порядка. Как объяснялось в разделе 1, существует множество способов, с помощью которых можно добавить вероятностные характеристики в логику. Модели логики могут иметь вероятностные аспекты, понятие следствия может иметь вероятностный оттенок или язык логики может содержать вероятностные операторы. В этом разделе мы сосредоточимся на тех логических операторах, которые имеют вид первого порядка. Вид первого порядка — то, что отличает эти операторы от вероятностных модальных операторов предыдущего раздела.
Рассмотрим следующий пример из работы Bacchus 1990:
Более 75% всех птиц летают.
Существует прямая вероятностная интерпретация этого утверждения, а именно: когда кто-то случайно выбирает птицу, то вероятность того, что выбранная птица летит, составляет более 3/4. Для выражения такого рода утверждений необходимы вероятностные операторы первого порядка.
Пример вероятностной логики первого порядка
В этом разделе, чтобы сосредоточиться на вероятностных кванторах, мы более подробно рассмотрим конкретную вероятностную логику первого порядка, язык которой максимально прост. Этот язык очень похож на язык классической логики первого порядка, но вместо привычного универсального и экзистенциального квантора он содержит вероятностный квантор.
Язык построен на множестве индивидуальных переменных (обозначенных x, y, z, x1, x2, …), множестве функциональных символов (обозначаемых f, g, h, f1, …), где местность ассоциируется с каждым символом (нульместные функциональные символы также называются индивидуальными постоянными), и множеством букв предикатов (обозначенных R, P1, …), где местность ассоциируется с каждым символом. Язык содержит два вида синтаксических объектов, а именно термы и формулы. Термы определяются индуктивно следующим образом:
● Каждая индивидуальная переменная x является термом.
● Каждый символ функции f местности n, за которым следует n-кортеж термов (t1, …, tn), является термом.
Учитывая это определение термов, формулы определяются индуктивно следующим образом:
● Каждая предикатная буква R местности n, за которой следует n-кортеж термов (t1, …, tn), является формулой.
● Если ϕ формула, то и ¬ϕ тоже.
● Если ϕ и ψ являются формулами, то и (ϕ ∧ ψ) тоже.
● Если ϕ — формула, а q — рациональное число в интервале [0,1], то Px (ϕ) ≥ q.
Формулы вида Px(ϕ) ≥ q следует читать так: «вероятность выбора x такого, что x удовлетворяет ϕ, равна по меньшей мере q». Формула Px(ϕ) ≤ q является сокращением Px(¬ϕ) ≥ 1 − q, а Px(ϕ) = q — сокращение Px(ϕ) ≥ q ∧ Px(ϕ) ≤ q. Каждое свободное вхождение x в ϕ связано оператором.
Этот язык интерпретируется на очень простых моделях первого порядка, которые являются тройками M = (D, I, P), где область дискурса D — конечное непустое множество объектов, интерпретация I связывает n-местную функцию над D с каждым n-местным функциональным символом, который встречается в языке, и n-местное отношение D с каждой n-местной буквой предиката. P — вероятностная функция, которая приписывает вероятность P(d) каждому элементу d в D так, что ∑d∈D P(d) = 1.
Для интерпретации формул, содержащих свободные переменные, также требуется приписывание g, которое назначает каждой переменной элемент D. Интерпретация [[t]]M,g терма t с учетом модели M = (D,I,P) и приписываемого g определяется индуктивно следующим образом:
● [[x]]M,g = g(x)
● [[f(t1, …, tn)]]M,g = I(f)([[t1]], …, [[tn]])
Истина определяется как отношение ⊧ между моделями с приписываниями и формулами:
● M, g ⊧ R(t1, …, tn) тогда и только тогда, когда ([[t1]], …, [[tn]]) ∈ I(R)
● M, g ⊧ ¬ϕ тогда и только тогда, когда g ⊭ϕ
● M, g ⊧ (ϕ ∧ ψ) тогда и только тогда, когда g ⊧ ϕ и M, g ⊧ ψ
● M, g ⊧ Px(ϕ) ≥ q тогда и только тогда, когда ∑d:M,g[x↦d] ⊧ ϕ P(d) ≥ q
В качестве примера рассмотрим модель вазы, содержащей девять шариков: пять черных и четыре белых. Предположим, что P приписывает вероятность 1/9 каждому шару, что отражает идею равной вероятности выбора любого шарика. Предположим, что язык содержит одноместный предикат B, интерпретацией которого является множество черных шариков. Утверждение Px(B(x)) = 5/9 верно в этой модели независимо от приписывания.
Необходимость расширений
Представленная в предыдущем разделе логика слишком проста, чтобы охватить многие формы рассуждений о вероятностях. Мы обсудим здесь три расширения.
Квантификация более чем одной переменной
Прежде всего, хотелось бы рассуждать о случаях, когда из области выбирается более одного объекта. Рассмотрим, например, вероятность того, что сначала будет выбран черный шарик, затем его положат обратно в вазу и возьмут оттуда белый. Вероятность этого равна 5/9 × 4/9 = 20/81, но мы не можем выразить это на вышеприведенном языке. Для этого нам нужен один оператор, который будет иметь дело с несколькими переменными одновременно, записанными как Px1,…xn(ϕ) ≥ q. Тогда семантика для таких операторов должна будет обеспечить вероятностную меру на подмножествах Dn. Самый простой способ сделать это — просто взять произведение вероятностной функции P на D, которое можно принять как расширение P на кортежи, где P(d1,…dn) = P(d1) ×⋯ × P(dn), что дает следующую семантику:
M, g ⊧ Px1…xn(ϕ) ≥ q т.т.т. ∑(d1,…, dn):M,g[x1↦d1,…, xn↦dn] ⊧ ϕ P(d1,…, dn) ≥ q
Этот подход принят в Bacchus 1990 и Halpern 1990, что соответствует идее независимого отбора с заменами. С помощью подобной семантики приведенный выше пример может быть формализован как Px,y(B(x) ∧¬B(y)) = 20/81. Существуют также более общие подходы к расширению меры области на кортежи из области, такие как в Hoover 1978 и Keisler 1985.
Кондициональная вероятность
Когда мы рассмотрим первоначальный пример, что более 75% всех птиц летают, мы обнаружим, что его нельзя адекватно отобразить в модели, область которой содержит объекты, которые не являются птицами. Не эти объекты должны иметь значение для того, что хочется выразить, но кванторы вероятности, квантифицирующие всю область. Для ограничения квантификации необходимо добавить кондициональные вероятностные операторы Px (ϕ | ψ) ≥ q со следующей семантикой:
M, g ⊧ Px(ϕ | ψ) ≥ q т.т.т., если есть d ∈ D такое, что M, g[x↦d] ⊧ ψ, тогда (∑d:M,g[x↦d] ⊧ ϕ∧ψ P(d) / ∑d:M,g[x↦d] ⊧ ψ P(d)) ≥ q.
С помощью этих операторов формула Px(F(x) | B(x)) > 3/4 выражает, что более 75% всех птиц летают.
Вероятности как термы
Когда некто хочет сравнить вероятности различных событий, скажем, выбора черного шарика и белого шарика, возможно, более удобным будет рассматривать вероятности как термы сами по себе. То есть выражение Px(ϕ) интерпретируется как относящееся к некоторому рациональному числу. Затем можно расширить язык арифметическими операциями, такими как сложение и умножение, и операторами, такими как равенство и неравенство, чтобы сравнить вероятностные термы. Тогда можно сказать, что некто может выбрать черный шарик с вероятностью в два раза большей, чем белый, как Px(B(x)) = 2 × Px(W(x)). Такое расширение требует, чтобы язык содержал два отдельных класса термов: один для вероятностей, чисел и результатов арифметических операций над такими термами, а другой для области дискурса, которую вероятностные операторы квантифицируют. Мы не будем подробно здесь говорить о таком языке и семантике. Такую систему можно найти в Bacchus 1990.
Металогика
Как правило, трудно обеспечить системы доказательств для вероятностных логик первого порядка, поскольку проблема валидности этих логик, как правило, неразрешима. Это даже не имеет место, как, например, в случае классической логики первого порядка, что если вывод верен, то его можно обнаружить за конечное время (см. Abadi and Halpern 1994).
Тем не менее существует много результатов для логики вероятностей первого порядка. Например, в Hoover 1978 и Keisler 1985 изучаются результаты полноты. В Bacchus 1990 и Halpern 1990 также предоставляется полная аксиоматизация, а также комбинации вероятностной логики первого порядка и модальной вероятностной логики.
Библиография
● Рамсей, Ф. П., 2003 [1926], Истина и вероятность. Философские работы, Томск: Изд-во Том. ун-та, 2003, с. 115–161.
● Abadi, M. and J. Y. Halpern, 1994, “Decidability and Expressiveness for First-Order Logics of Probability,” Information and Computation, 112: 1–36.
● Adams, E. W. and H. P. Levine, 1975, “On the Uncertainties Transmitted from Premisses to Conclusions in Deductive Inferences,” Synthese, 30: 429–460.
● Adams, E. W., 1998, A Primer of Probability Logic, Stanford, CA: CSLI Publications.
● Arló Costa, H., 2005, “Non-Adjunctive Inference and Classical Modalities,” Journal of Philosophical Logic, 34: 581–605.
● Bacchus, F., 1990, Representing and Reasoning with Probabilistic Knowledge, Cambridge, MA: The MIT Press.
● Baltag, A. and S. Smets, 2008, “Probabilistic Dynamic Belief Revision,” Synthese, 165: 179–202.
● van Benthem, J., J. Gerbrandy, and B. Kooi, 2009, “Dynamic Update with Probabilities,” Studia Logica, 93: 67–96.
● Boole, G., 1854, An Investigation of the Laws of Thought, on which are Founded the Mathematical Theories of Logic and Probabilities, London: Walton and Maberly.
● Burgess, J., 1969, “Probability Logic,” Journal of Symbolic Logic, 34: 264–274.
● Carnap, R., 1950, Logical Foundations of Probability, Chicago, IL: University of Chicago Press.
● Cross, C., 1993, “From Worlds to Probabilities: A Probabilistic Semantics for Modal Logic,” Journal of Philosophical Logic, 22: 169–192.
● Dempster, A., 1968, “A Generalization of Bayesian Inference,” Journal of the Royal Statistical Society, 30: 205–247.
● De Morgan, A., 1847, Formal Logic, London: Taylor and Walton.
● de Finetti, B., 1937, “La Prévision: Ses Lois Logiques, Ses Sources Subjectives”, Annales de l'Institut Henri Poincaré, 7: 168; translated as “Foresight. Its Logical Laws, Its Subjective Sources,” in Studies in Subjective Probability, H. E. Kyburg, Jr. and H. E. Smokler (eds.), Malabar, FL: R. E. Krieger Publishing Company, 1980, pp. 53–118.
● Eagle, A., 2010, Philosophy of Probability: Contemporary Readings, London: Routledge.
● Fagin, R. and J. Y. Halpern, 1988, “Reasoning about Knowledge and Probability,” in Proceedings of the 2nd conference on Theoretical aspects of reasoning about knowledge, M. Y. Vardi (ed.), Pacific Grove, CA: Morgan Kaufmann, pp. 277–293.
● –––, 1994, “Reasoning about Knowledge and Probability,” Journal of the ACM, 41: 340–367.
● Fagin, R., J. Y. Halpern, and N. Megiddo, 1990, “A Logic for Reasoning about Probabilities,” Information and Computation, 87: 78–128.
● Fitelson, B., 2006, “Inductive Logic,” in The Philosophy of Science: An Encyclopedia, J. Pfeifer and S. Sarkar (eds.), New York, NY: Routledge, pp. 384–394.
● Gärdenfors, P., 1975a, “Qualitative Probability as an Intensional Logic,” Journal of Philosophical Logic, 4: 171–185.
● –––, 1975b, “Some Basic Theorems of Qualitative Probability,” Studia Logica, 34: 257–264.
● Georgakopoulos, G., D. Kavvadias, and C. H. Papadimitriou, 1988, “Probabilistic Satisfiability,” Journal of Complexity, 4: 1–11.
● Gerla, G., 1994, “Inferences in Probability Logic,” Artificial Intelligence, 70: 33–52.
● Gillies, D., 2000, Philosophical Theories of Probability, London: Routledge.
● Goldman, A. J. and A. W. Tucker, 1956, “Theory of Linear Programming,” in Linear Inequalities and Related Systems. Annals of Mathematics Studies 38, H. W. Kuhn and A. W. Tucker (eds.), Princeton: Princeton University Press, pp. 53–98.
● Goosens, W. K., 1979, “Alternative Axiomatizations of Elementary Probability Theory,” Notre Dame Journal of Formal Logic, 20: 227–239.
● Hájek, A., 2001, “Probability, Logic, and Probability Logic,” in The Blackwell Guide to Philosophical Logic, L. Goble (ed.), Oxford: Blackwell, pp. 362–384.
● Hájek, A. and S. Hartmann, 2010, “Bayesian Epistemology,” in A Companion to Epistemology, J. Dancy, E. Sosa, and M. Steup (eds.), Oxford: Blackwell, pp. 93–106.
● Haenni, R. and N. Lehmann, 2003, “Probabilistic Argumentation Systems: a New Perspective on Dempster-Shafer Theory,” International Journal of Intelligent Systems, 18: 93–106.
● Haenni, R., J.-W. Romeijn, G. Wheeler, and J. Williamson, 2011, Probabilistic Logics and Probabilistic Networks, Dordrecht: Springer.
● Hailperin, T., 1965, “Best Possible Inequalities for the Probability of a Logical Function of Events,” American Mathematical Monthly, 72: 343–359.
● –––, 1984, “Probability Logic,” Notre Dame Journal of Formal Logic, 25: 198–212.
● –––, 1986, Boole's Logic and Probability, Amsterdam: North-Holland.
● –––, 1996, Sentential Probability Logic: Origins, Development, Current Status, and Technical Applications, Bethlehem, PA: Lehigh University Press.
● Halpern, J. Y. and M. O. Rabin, 1987, “A Logic to Reason about Likelihood”, Artificial Intelligence, 32: 379–405.
● Halpern, J. Y., 1990, “An analysis of first-order logics of probability”, Artificial Intelligence, 46: 311–350.
● –––, 1991, “The Relationship between Knowledge, Belief, and Certainty,” Annals of Mathematics and Artificial Intelligence, 4: 301–322. Errata appeared in Annals of Mathematics and Artificial Intelligence, 26 (1999): 59–61.
● –––, 2003, Reasoning about Uncertainty, Cambridge, MA: The MIT Press.
● Hamblin, C.L., 1959, “The modal ‘probably’”, Mind, 68: 234–240.
● Hansen, P. and B. Jaumard, 2000, “Probabilistic Satisfiability,” in Handbook of Defeasible Reasoning and Uncertainty Management Systems. Volume 5: Algorithms for Uncertainty and Defeasible Reasoning, J. Kohlas and S. Moral (eds.), Dordrecht: Kluwer, pp. 321–367.
● Hartmann, S. and J. Sprenger, 2010, “Bayesian Epistemology,” in Routledge Companion to Epistemology, S. Bernecker and D. Pritchard (eds.), London: Routledge, pp. 609–620.
● Heifetz, A. and P. Mongin, 2001, “Probability Logic for Type Spaces”, Games and Economic Behavior, 35: 31–53.
● Herzig, A. and D. Longin, 2003, “On Modal Probability and Belief,” in Proceedings of the 7th European Conference on Symbolic and Quantitative Approaches to Reasoning with Uncertainty (ECSQARU 2003), T.D. Nielsen and N.L. Zhang (eds.), Lecture Notes in Computer Science 2711, Berlin: Springer, pp. 62–73.
● Hoover, D. N., 1978, “Probability Logic,” Annals of Mathematical Logic, 14: 287–313.
● Howson, C., 2003, “Probability and Logic,” Journal of Applied Logic, 1: 151–165.
● –––, 2007, “Logic with Numbers,” Synthese, 156: 491–512.
● –––, 2009, “Can Logic be Combined with Probability? Probably,” Journal of Applied Logic, 7: 177–187.
● Jeffrey, R., 1992, Probability and the Art of Judgement, Cambridge: Cambridge University Press.
● Jonsson, B., K. Larsen, and W. Yi, 2001 “Probabilistic Extensions of Process Algebras,” in Handbook of Process Algebra, J. A. Bergstra, A. Ponse, and S. A. Smolka (eds.), Amsterdam: Elsevier, pp. 685–710.
● Kavvadias, D. and C. H. Papadimitriou, 1990, “A Linear Programming Approach to Reasoning about Probabilities,” Annals of Mathematics and Artificial Intelligence, 1: 189–205.
● Keisler, H. J., 1985, “Probability Quantifiers,” in Model-Theoretic Logics, J. Barwise and S. Feferman (eds.), New York, NY: Springer, pp. 509–556.
● Kooi B. P., 2003, “Probabilistic Dynamic Epistemic Logic,” Journal of Logic, Language and Information, 12: 381–408.
● Kyburg, H. E., 1965, “Probability, Rationality, and the Rule of Detachment,” in Proceedings of the 1964 International Congress for Logic, Methodology, and Philosophy of Science, Y. Bar-Hillel (ed.), Amsterdam: North-Holland, pp. 301–310.
● –––, 1994, “Uncertainty Logics, ” in Handbook of Logic in Artificial Intelligence and Logic Programming, D. M. Gabbay, C. J. Hogger, and J. A. Robinson (eds.), Oxford: Oxford University Press, pp. 397–438.
● Larsen, K. and A. Skou, 1991, “Bisimulation through Probabilistic Testing,” Information and Computation, 94: 1–28.
● Leblanc, H., 1979, “Probabilistic Semantics for First-Order Logic,” Zeitschrift für mathematische Logik und Grundlagen der Mathematik, 25: 497–509.
● –––, 1983, “Alternatives to Standard First-Order Semantics,” in Handbook of Philosophical Logic, Volume I, D. Gabbay and F. Guenthner (eds.), Dordrecht: Reidel, pp. 189–274.
● Lewis, D., 1980, “A Subjectivist's Guide to Objective Chance,” in Studies in Inductive Logic and Probability. Volume 2, R. C. Jeffrey (ed.), Berkeley, CA: University of California Press, pp. 263–293; reprinted in Philosophical Papers. Volume II, Oxford: Oxford University Press, 1987, pp. 83–113.
● Miller, D., 1966, “A Paradox of Information,” British Journal for the Philosophy of Science, 17: 59–61.
● Morgan, C., 1982a, “There is a Probabilistic Semantics for Every Extension of Classical Sentence Logic,” Journal of Philosophical Logic, 11: 431–442.
● –––, 1982b, “Simple Probabilistic Semantics for Propositional K, T, B, S4, and S5,” Journal of Philosophical Logic, 11: 443–458.
● –––, 1983, “Probabilistic Semantics for Propositional Modal Logics”. in Essays in Epistemology and Semantics, H. Leblanc, R. Gumb, and R. Stern (eds.), New York, NY: Haven Publications, pp. 97–116.
● Morgan, C. and H. Leblanc, 1983, “Probabilistic Semantics for Intuitionistic Logic,” Notre Dame Journal of Formal Logic, 24: 161–180.
● Nilsson, N., 1986, “Probabilistic Logic,” Artificial Intelligence, 28: 71–87.
● –––, 1993, “Probabilistic Logic Revisited,” Artificial Intelligence, 59: 39–42.
● Paris, J. B., 1994, The Uncertain Reasoner's Companion, A Mathematical Perspective, Cambridge: Cambridge University Press.
● Parma, A. and R. Segala, 2007, “Logical Characterizations of Bisimulations for Discrete Probabilistic Systems,” in Proceedings of the 10th International Conference on Foundations of Software Science and Computational Structures (FOSSACS), H. Seidl (ed.), Lecture Notes in Computer Science 4423, Berlin: Springer, pp. 287–301.
● Pearl, J., 1991, “Probabilistic Semantics for Nonmonotonic Reasoning,” in Philosophy and AI: Essays at the Interface, R. Cummins and J. Pollock (eds.), Cambridge, MA: The MIT Press, pp. 157–188.
● Reichenbach, H., 1949, The Theory of Probability, Berkeley, CA: University of California Press.
● Romeijn, J.-W., 2011, “Statistics as Inductive Logic,” in Handbook for the Philosophy of Science. Vol. 7: Philosophy of Statistics, P. Bandyopadhyay and M. Forster (eds.), Amsterdam: Elsevier, pp. 751–774.
● Segerberg, K., 1971, “Qualitative Probability in a Modal Setting”, in Proceedings 2nd Scandinavian Logic Symposium, E. Fenstad (ed.), Amsterdam: North-Holland, pp. 341–352.
● Shafer, G., 1976, A Mathematical Theory of Evidence, Princeton, NJ: Princeton University Press.
● Suppes, P., 1966, “Probabilistic Inference and the Concept of Total Evidence,” in Aspects of Inductive Logic, J. Hintikka and P. Suppes (eds.), Amsterdam: Elsevier, pp. 49–65.
● Szolovits, P. and S. G. Pauker, 1978, “Categorical and Probabilistic Reasoning in Medical Diagnosis,” Artificial Intelligence, 11: 115–144.
● Tarski, A., 1936, “Wahrscheinlichkeitslehre und mehrwertige Logik”, Erkenntnis, 5: 174–175.
● Van Fraassen, B., 1981a, “A Problem for Relative Information Minimizers in Probability Kinematics,” British Journal for the Philosophy of Science, 32:375–379.
● –––, 1981b, “Probabilistic Semantics Objectified: I. Postulates and Logics,” Journal of Philosophical Logic, 10: 371–391.
● –––, 1983, “Gentlemen's Wagers: Relevant Logic and Probability,” Philosophical Studies, 43: 47–61.
● –––, 1984, “Belief and the Will,” Journal of Philosophy, 81: 235–256.
● Vennekens, J., M. Denecker, and M. Bruynooghe, 2009, “CP-logic: A Language of Causal Probabilistic Events and its Relation to Logic Programming,” Theory and Practice of Logic Programming, 9: 245–308.
● Walley, P., 1991, Statistical Reasoning with Imprecise Probabilities, London: Chapman and Hall.
● Williamson, J., 2002, “Probability Logic,” in Handbook of the Logic of Argument and Inference: the Turn Toward the Practical, D. Gabbay, R. Johnson, H. J. Ohlbach, and J. Woods (eds.), Amsterdam: Elsevier, pp. 397–424.
● Yalcin, S., 2010, “Probability Operators,” Philosophy Compass, 5: 916–937.


.jpg)
.jpg)




