





Теория игр
- Философский и исторический фон
- Базовые элементы и допущения теории игр
- Неопределенность, риск и секвенциальное равновесие
- Повторяющиеся игры и координация
- Командное мышление и условные игры
- Обязательства
- Эволюционная теория игр
- Теория игр и поведенческие данные
- Глядя вперед: области современных инноваций
- Библиография
Впервые опубликовано 25 января 1997 года; содержательно переработано 9 декабря 2014 года.
Теория игр занимается изучением того, каким образом взаимодействие решений экономических агентов дает результаты сообразно предпочтениям (или полезностям) для агентов, даже если результаты не входили в намерения ни одного из агентов. Значение этого высказывания не будет понятно неспециалистам до тех пор, пока выделенные курсивом слова и фразы не будут объяснены и проиллюстрированы примерами. Этому и будет посвящена настоящая статья. Для начала, однако, мы рассмотрим исторический и философский контекст, дабы подготовить читателя к технической части текста, что последует далее.
Философский и исторический фон
Математическая теория игр была разработана Джоном фон Нейманом и Оскаром Моргенштерном (von Neumann and Morgenstern 1944). По причинам, которые мы обсудим позже, ограничения их математической модели позволяли применять теорию только для ряда специальных и ограниченных условий. За прошедшие семьдесят лет, по мере углубления и обобщения теории, это изменилось самым значительным образом. Теория продолжает дорабатываться, и в конце статьи мы рассмотрим несколько крупных проблем, которые еще только предстоит решить. Однако как минимум с конца 1970-х годов уже можно с уверенностью говорить, что теория игр является самым важным и полезным инструментом в арсенале аналитика, который столкнулся с ситуацией, в которой наилучшее действие агента зависит от его ожиданий от поступков других агентов — а то, что считается наилучшим действием для них, также зависит от их ожиданий по отношению к первому агенту.
Несмотря на то, что теория игр получила математическую и логическую формализацию только в 1944 году, экскурсы в эту область можно найти в античных текстах. Например, в двух сочинениях Платона, «Лахесе» и «Пире», Сократ упоминает сражение при Делии, которое некоторые комментаторы (скорее всего, поздние) интерпретировали следующим образом.
Рассмотрим воина, который готовится вместе со своими товарищами отразить атаку противника. Ему может прийти в голову, что в случае, если оборона окажется успешной, его личный вклад в победу вряд ли будет решающим. Но если он останется в строю, то рискует быть убитым или раненым — как кажется, без всякого смысла. С другой стороны, если противник одержит верх, то шансы нашего воина быть убитым или раненым будут еще выше, что еще более бессмысленно, поскольку оборона все равно будет сломлена. Опираясь на эти соображения, воину, казалось бы, следовало бы дезертировать, независимо от того, кто выиграет битву. Конечно, если все бойцы рассудят так — как им, в общем-то, следовало бы, поскольку они находятся в одной и той же ситуации — это, безусловно, сразу же приведет к поражению в битве. Разумеется, поскольку это очевидно для нас, аналитиков, это может прийти в голову и самим воинам. Дает ли им это основание оставаться в строю? Как раз наоборот: чем больше опасаются воины проиграть сражение, тем больше у них поводов убраться подобру-поздорову. И чем больше их уверенность в победе, которая не требует от них личного участия, тем меньше у них оснований оставаться в строю. Если каждый из них предвосхитит подобный ход мыслей у других, все в итоге быстро впадут в панику, и их командир потерпит поражение прежде, чем враг выпустит первую стрелу.
Задолго до того, как теория игр продемонстрировала аналитикам способы систематического разбора таких проблем, подобные размышления приходили в голову полководцам и влияли на их стратегию. Так, высадившийся в Мексике Кортес имел весьма небольшое войско — и у него были все основания опасаться, что ему не удастся отразить атаки намного более многочисленных ацтеков. Кортес избежал возможного бегства своих войск, предав огню корабли, на которых прибыли испанцы. Не имея физической возможности бежать, у бойцов Кортеса не было лучшего выхода из ситуации, кроме как сражаться — и, более того, сражаться со всей решимостью, на которую они только были способны.
Более того, с точки зрения Кортеса, его действия возымели еще и деморализующий эффект на ацтеков. Он принял специальные меры к тому, чтобы корабли полыхали прямо на глазах у индейцев. И те рассудили так: любой командир, по собственной воле уничтожающий всякую возможность благоразумно ретироваться при неблагоприятном исходе битвы, должен иметь крайне сильные основания для подобного оптимизма. Атаковать врага, имеющего столь весомые причины считать себя непобедимым (какими бы эти причины ни были), неразумно. Потому ацтеки отступили, а Кортес одержал победу, не пролив ни капли крови.
Приведенные выше примеры, битва при Делии и поступок Кортеса, имеют любопытную и при том схожую логическую структуру. Заметьте, что мотивы для дезертирства возникают у солдат не столько потому — или даже только — что они рационально оценивают опасности битвы и свою личную выгону. Скорее, осознавая, что то, что разумно для них, зависит от того, что разумно для других, и что все остальные также могут это заметить, они получают весомые причины для бегства. Даже весьма смелый воин может предпочесть бегство героической, но бессмысленной смерти в попытке единолично остановить наступление противника. Следовательно, мы можем непротиворечиво представить себе обстоятельства, при которых исключительно храбрая армия бежит со всех ног еще до того, как противник двинется в ее сторону.
Другой классический источник, в котором мы находим ту же цепочку рассуждений, — шекспировская пьеса «Генрих V». Во время битвы при Азенкуре Генрих принимает решение казнить пленных французов на виду у врага — и на удивление своих подчиненных, считающих такой поступок аморальным. Основания, из которых исходит Генрих, не имеют отношения к вопросам стратегии: он якобы опасается, что пленники могут освободиться и создать угрозу его позиции. Однако специалист по теории игр мог бы поддержать Генриха со стороны стратегии, хотя его обоснования, будучи благоразумными, возможно, будут не менее аморальны.
Войска увидят казнь пленников, а также то, что ее также лицезрел и их противник. Поэтому они будут знать, какая судьба будет их ждать, если они не одержат победы. Метафорически (но крайне эффективно) выражаясь, их корабли будут преданы огню. Казнь пленников пошлет недвусмысленный сигнал солдатам обеих сторон, и их изменившиеся установки будут благоприятствовать победе англичан.
Эти примеры могут показаться релевантными только для тех, кто регулярно оказывается в ситуации ожесточеннейшей конкуренции. Возможно, подумаете вы, что все это может пригодиться только генералам, политикам, мафиози, тренерам спортивных команд и другим людям, чья работа подразумевает манипулирование другими в стратегических целях — в то время как философу стоит лишь порицать их аморальность. Однако смеем заверить вас, что делать подобные выводы было бы слишком преждевременно. Исследование логики, которая управляет взаимоотношениями между стимулами, стратегическими взаимодействиями и их результатами лежали в основаниях современной политической философии за века до того, как подобному типу логики было найдено имя. Философам в той же мере, что и социологам, необходимо уметь представлять и систематически моделировать не только должное поведение людей, но и их действительное поведение в ситуациях взаимодействия.
«Левиафан» Гоббса часто называют основополагающей работой для современной политической философии. Этот текст положил начало исследованиям функций государственности, ее обоснований, а также ограничений, которые последняя накладывает на индивидуальные свободы. Ключевую мысль Гоббса можно сформулировать довольно прямолинейно: наилучшая ситуация для любого человека — такая, в которой он волен поступать так, как ему вздумается. (Можно с этим соглашаться или не соглашаться, если смотреть на это с точки зрения психологии, но уж такова предпосылка Гоббса.) Зачастую свободные в подобном смысле люди будут стремиться к кооперации для выполнения задач, с которыми невозможно в одиночку. Но если среди них найдется имморальный или аморальный агент, он заметит, что в его интересах будет хотя бы иногда «снимать сливки» с кооперации и не отдавать ничего взамен. Предположим, например, что вы согласились помочь мне с постройкой дома — взамен на мое обещание помочь вам с постройкой вашего. После того, как мой дом возведен, я могу сделать ваш труд неоплачиваемым, просто отказавшись от своего обещания. Потом я, однако, пойму, что если это оставит вас без дома, у вас появится стимул отобрать мой. Это поставит меня в ситуацию постоянного страха, и заставит меня потратить ценные время и ресурсы на защиту от вас. Наилучший способ минимизировать подобные издержки для меня — это ударить первым и убить вас при первой возможности. Конечно же, вы можете предвосхитить все эти рассуждения, происходящие в моей голове, и иметь потому хорошие основания для того чтобы опередить меня. Поскольку я также могу предвосхитить это, мой изначальный страх перед вами не параноидален, равно как и ваши подозрения по отношению ко мне. В действительности, никому из нас не обязательно быть имморальным для того чтобы прийти к подобной цепочке рассуждений; нам достаточно лишь подумать о том, что есть некоторая вероятность, что другой попробует смошенничать. Как только тень сомнения проникает в чей-либо ум, стимул, вырастающий из страха перед последствиями опережающего удара — пострадать от удара до того, как ударил сам — быстро становится чрезвычайно силен. Если хоть один из нас обладает какими-либо небезынтересными для других ресурсами, эта убийственная логика получит власть над нами намного раньше, чем кто-то из нас по глупости предположит, будто мы можем помочь друг другу с постройкой домов. Предоставленные сами себе, хотя бы изредка корыстные агенты будут снова и снова обнаруживать отсутствие всяких выгод от кооперации, вместе с этим все глубже погружаясь в гоббсовскую «войну всех против всех». В подобных обстоятельствах человеческая жизнь, как гласит знаменитая максима Гоббса, действительно будет «одинокой, бедной, мерзкой, грубой и короткой».
Гоббсовским решением этой проблемы стала тирания. Люди могут нанять агента — правительство, которое будет наказывать любого, кто нарушает какое бы то ни было обещание. До тех пор, пока угрожающее наказание будет достаточно тяжелым, потери от нарушения обещаний превысят затраты на их соблюдение. Логика здесь идентична той, которая используется армией, угрожающей расстреливать дезертиров. Если все люди будут четко осознавать, что эти стимулы существуют также и для большинства других, то сотрудничество не просто окажется возможным — оно станет ожидаемой нормой, а война всех против всех сменится общим миром.
Гоббс развертывает логику данного аргумента до очень сильного вывода, утверждая, что он подразумевает не только наличие правительства, обладающего правом и силой для обеспечения сотрудничества, но и «неразделенного» правительства, в котором произвольная воля одного правителя должна налагать абсолютное обязательство на всех. Немногие современные политические теоретики считают, что конкретные шаги, с помощью которых Гоббс приходит к такому выводу, являются одновременно и обоснованными, и правильными. Однако обсуждение этих вопросов увело бы нас от исходной темы и заставило погружаться в нюансы контрактуалистской политической философии. В данном контексте важно то, что эти нюансы, как они обсуждаются в современных дискуссиях, требуют сложной интерпретации проблем с использованием ресурсов современной теории игр. Более того, исходный аргумент Гоббса — что главным обоснованием принудительной власти и практик правительств является потребность людей защищать себя от того, что теоретики игр называют «социальными дилеммами» — принимается многими политическими мыслителями, если не большинством из них. Следует обратить внимание на то, что Гоббс не говорил о желательности тирании как таковой. Согласно его аргументу логика стратегического взаимодействия оставляет только два возможных общих политических решения: тиранию и анархию. Разумные агенты выбирают тиранию как меньшее из двух зол.
Рассуждения афинских солдат, Кортеса и политических агентов Гоббса имеют общую логику, производную от их ситуаций. В каждом случае аспектом окружающей среды, который наиболее важен для достижения агентами предпочтительных для них результатов, является совокупность ожиданий и возможных реакций на их стратегии других агентов. Различие между параметрическим воздействием на пассивный мир и непараметрическим воздействием на мир, пытающийся действовать с опорой на предвосхищение этого воздействия, является фундаментальным. Если вы хотите ударом ноги спустить камень с холма, вам нужно беспокоиться лишь о соотношении массы камня с силой своего удара, степенью сцепления камня с опорной поверхностью, уклоном по другую сторону камня и ожидаемым воздействием удара на вашу ногу. Значения всех этих переменных не зависят от ваших планов и намерений, поскольку глыба не имеет собственных интересов и не предпринимает никаких действий, чтобы попытаться помочь или помешать вам. В отличие от этого, если вы хотите пинком сбросить кого-то с холма, то, если этот человек не находится в бессознательном состоянии, не связан или не беспомощен, вы, скорее всего, не добьетесь успеха, если не сможете замаскировать свои планы, пока ему не станет слишком поздно предпринимать какое-либо упреждающее действие. Более того, можно ожидать, что он попытается как-то отплатить вам, что было бы разумно учитывать. Наконец, относительные вероятности различных его реакций будут зависеть от его ожиданий относительно ваших вероятных ответов на его ответы. (Учитывайте также разницу, которая скажется на обоих ваших рассуждениях, если один или оба из вас вооружены, или один из вас больше другого, или один из вас — начальник другого). Логические проблемы, связанные с ситуацией второго типа (где сталкивают человека, а не камень) обычно намного сложнее, как это проиллюстрирует следующий простой гипотетический пример.
Предположим сначала, что вы хотите пересечь реку, через которую переброшены три моста. (Допустим, что перейти реку вброд, одолеть ее вплавь или переплыть на лодке невозможно) Известно, что первый мост безопасен и скрывает никаких препятствий; если вы попытаетесь пересечь реку по нему, вы добьетесь успеха. Второй мост пролегает под скалой, с которой иногда падают большие камни. Третий кишит смертельными кобрами. Теперь предположим, что вы хотите определить, насколько каждый мост предпочтителен для переправы, и распределить мосты по соответствующим уровням пригодности. Если рисковать своей жизнью вам не по нраву — а как человек мы вполне можете этим наслаждаться (усложнение, которое мы рассмотрим позже в этой статье), — тогда проблема с выбором решения здесь проста. Первый мост, очевидно, лучше всего, так как он безопасен. Чтобы ранжировать два других моста, вам требуется информация об их относительных уровнях опасности. Если бы у вас была возможность некоторое время изучать частоту камнепадов и передвижения кобр, вы смогли бы вычислить, что вероятность быть раздавленным камнями на втором мосту составляет 10%, а быть укушенным коброй на третьем мосту — 20%. Ваше рассуждение здесь строго параметрическое, потому что ни камни, ни кобры не пытаются влиять на ваши действия, например, скрывая типичные закономерности своего поведения в силу того, что они знают, что вы их изучаете. Очевидно, что здесь вам необходимо: пересечь реку по безопасному мосту. Теперь немного усложним ситуацию. Предположим, что мост со скалами находится непосредственно перед вами, в то время как безопасный мост находится на расстоянии сложного суточного перехода. Ваша ситуация с принятием решения здесь немного сложнее, но она по-прежнему остается строго параметрической. Вы должны решить, стоит ли длинный поход 10 % шанса смерти от камнепада. Однако это все, что должны решить именно вы, и вероятность успешной переправы полностью зависит только от вас; окружающую среду не интересуют ваши планы.
Однако, если мы усложним ситуацию, добавив непараметрический элемент, она станет более сложной. Предположим, что вы некий беглец, а на другом береге реки вас ожидает с ружьем ваш преследователь. Он поймает вас и пристрелит, допустим, только если он ждет у моста, который вы пытаетесь пересечь; в противном случае вы убежите. Когда вы рассуждаете о выборе моста, вам приходит в голову, что преследователь также пытается предвидеть ваши рассуждения. Тогда, безусловно, выбор безопасного моста сразу станет ошибочным, так как именно там преследователь и будет вас ожидать, и возможность быть убитым будет несомненной. Поэтому, возможно, вам следует принять риск камнепада, поскольку в этом случае ваш шанс спастись будет намного выше. Однако если вы сможете прийти к такому выводу, ваш преследователь, который так же рационален и хорошо информирован, как и вы, также сможет предвидеть, что вы придете к этому решению (избежать камнепада), и будет ожидать вас именно там, куда вы предпочтете пойти. Поэтому, возможно, вы должны испытать свои шансы с кобрами, поскольку этого преследователь должен ожидать меньше всего. Но тогда… если преследователь ожидает, что вы ожидаете, что он ожидает этого меньше всего, тогда он этого ожидает еще больше всего. Эта дилемма, как вы осознаете с ужасом, является общей: вы должны делать то, чего меньше всего ожидает ваш преследователь; но то, что ваш преследователь будет более всего ожидать именно то, что, по вашим ожиданиям, он бы ожидал менее всего. Похоже, что вы оказались в ловушке неразрешимости. Вас может хоть немного утешить лишь то обстоятельство, что на другом берегу реки ваш преследователь оказывается в ловушке точно такого же затруднения, будучи неспособен решить, у какого моста следует ждать, поскольку как только противник поймет, какое решение вы приняли, он заметит, что если он способен найти наилучшее основание для выбора того или иного моста, то вы можете это предвидеть, и, следовательно, избежать встречи.
Из опыта мы знаем, что в подобных ситуациях люди обычно не остаются в смятении вечно. Как мы увидим позже, существует рациональное решение, — то есть лучшее рациональное действие, — доступное для обоих игроков. Однако до 1940-х годов ни философы, ни экономисты не знали, как найти его математически. В результате экономисты были вынуждены рассматривать непараметрические влияния так, как если бы они были усложненными параметрическими. Это, скорее всего, может показаться странным, поскольку наш пример с переправой должен был показать, что непараметрические функции часто являются фундаментальными особенностями проблем принятия решений. Частично объяснение причин позднего попадания теории игр в эту область заключается в проблемах, с которыми экономисты сталкивались на протяжении истории.
Классические экономисты, такие как Адам Смит и Давид Рикардо, в основном интересовались тем, как агенты на очень больших рынках — целые народы — могут взаимодействовать для обеспечения максимального денежного благосостояния.
Экономисты всегда признавали, что эта совокупность предположений является чистой идеализацией для целей анализа, а не возможным положением вещей, которое любой человек мог бы попробовать (или должен хотеть попробовать) достичь. Но до тех пор, пока математический аппарат теории игр не достиг зрелости к концу 1970-х годов, экономисты вынуждены были надеяться, что чем более рынок приблизится к совершенной конкуренции, тем эффективнее он будет. Однако такая надежда не может быть в целом оправдана ни математически, ни логически; в самом деле, в качестве строгого обобщения данная посылка была признана ложной еще в 1950-х годах.
В этой статье речь не идет об основах экономики, однако нам важно понять истоки и масштабы теории игр, чтобы знать, что в идеально конкурентные рынки встроена некое свойство, которое делает их восприимчивыми к параметрическому анализу. Поскольку агенты не обременены расходами на вход на рынки, они будут открывать магазины на любом рынке, пока конкуренция не обнулит все прибыли. Это подразумевает, что если производственные издержки будут фиксированными, а спрос будет экзогенным, то агенты, — если они пытаются максимизировать разницу между своими расходами и доходами, — не могут свободно выбирать количество производимого. Уровни производства могут быть определены отдельно для каждого агента, поэтому никто не должен обращать внимание на то, что делают другие; каждый агент рассматривает своих коллег в качестве пассивных элементов окружающей среды. Другая ситуация, к которой может применяться классический экономический анализ без использования теории игр, — это монополия со множеством клиентов. Здесь, пока ни один клиент не получит достаточно большой доли спроса для осуществления стратегического влияния, исключаются всякие непараметрические соображения, и задача фирмы заключается только в определении такого сочетания цены и объема производства, при котором она максимизирует прибыль. Тем не менее как идеальная, так и монополистическая конкуренция — это особые и необычные рыночные механизмы. Поэтому до появления теории игр экономисты были существенно ограничены в выборе класса обстоятельств, к которым они могли бы точно применять свои модели.
Философы разделяют с экономистами профессиональный интерес к условиям и методам максимизации благосостояния. Кроме того, философы особенно озабочены логическим обоснованием действий, и зачастую от действий ожидается, что они будут обоснованы в виду ожидаемых от них результатов. (Одна из философских традиций, утилитаризм, отталкивается от идеи, что все могущие быть обоснованными действия должны обосновываться именно таким образом.) Без привлечения теории игр обе эти проблемы ускользают от анализа в ситуациях с непараметрическими аспектами. Мы вскоре продемонстрируем это, ссылаясь на самую известную (хотя и не самую типичную) игровую ситуацию, так называемую «дилемму заключенного», а также на другие, более типичные игры. При этом нам нужно будет ввести, определить и проиллюстрировать основные элементы и методы теории игр. К этому мы теперь и обратимся.
Базовые элементы и допущения теории игр
Полезность
Экономический агент по определению обладает предпочтениями (preferences). Специалисты в области теории игр, подобно экономистам и философам, изучающим рациональное принятие решений, описывают эти предпочтения при помощи абстрактного понятия полезности. Здесь имеется в виду ранжирование по некоторой специфической шкале субъективного благосостояния, которую агент применяет по отношению к тому или иному объекту или событию. Под «благосостоянием» мы понимаем некий нормативный индекс относительного благополучия, который опирается на ту или иную систему отсчета. К примеру, мы можем оценивать относительное благосостояние стран (если мы берем страны в качестве модельных агентов), используя доход на душу населения; мы можем оценивать относительное благосостояние животного — для предсказания и объяснения его поведенческих предрасположенностей — опираясь на наши ожидания относительно его эволюционной приспособленности.
В случае с людьми экономика, равно как и теория игр, обыкновенно оценивает их относительное благосостояние, опираясь на его имплицитную или эксплицитную со стороны самих людей. Поэтому мы выше и говорили о субъективном благополучии. Возьмем человека, который без ума от вкуса маринованных огурцов, но не в восторге от лука. Можно сказать, что он приписывает большую полезность тем состояниям мира, при которых он потребляет больше маринованных огурцов и меньше лука, чем тем, в которых он потребляет больше лука и меньше маринованных огурцов. Примеры подобного рода предполагают, что «полезность» есть мера субъективного психологического удовлетворения.
Именно так это понятие изначально понималось экономистами и философами, испытавшими влияние утилитаризма Иеремии Бентама. Однако в начале ХХ века экономисты со все большей ясностью видели, что предметом их интереса была рыночная собственность, предельный спрос на которую падал, независимо от того, происходило ли это в силу насыщения потребителей или каких-либо еще факторов. В 1930-е годы эта мотивировка экономистов была созвучна бихевиоризму и радикальному эмпиризму в психологии и, соответственно, в философии науки. Бихевиористы и радикальные эмпирицисты протестовали против теоретического использования таких ненаблюдаемых сущностей, как «коэффициент психологического удовлетворения».
Подобный интеллектуальный климат благоприятствовал попыткам экономиста Пола Самуэльсона переопределить полезность, сделав его чисто техническим понятием лишив его спекулятивных психологических корней. В 1950-е годы определение Самуэльсона стало общепринятым: когда мы говорим, что агент действует ради максимизации полезности, под «полезностью» мы понимаем просто Если вы заметили круг в этом определении, вы не ошиблись: теоретики, следующие за Самуэльсоном, действительно рассматривают высказывание «агенты действуют так, чтобы максимизировать полезность» как тавтологию, где «[экономический] агент» — это любая сущность, которая может быть точно описана как действующая для максимизации функции полезности. Под «действием» тут понимается выбор из множества максимизирующих полезность альтернатив, а под «функцией полезности» — то, что экономический агент максимизирует. Подобно всем другим тавтологиям, которые возникают в основаниях научных теорий, эта рекурсивная система дефиниций полезна не сама по себе, но постольку, поскольку позволяет нам установить контекст исследования.
Хотя бихевиоризм 1930-х годов был вытеснен интересом к латентным когнитивным процессам, многие теоретики и по сей день понимают полезность в духе Самуэльсона, поскольку считают важным сохранить применимость теории игр к агентам любого типа — человеку, медведю, пчеле, фирме или стране, — а не только агентам, наделенным человеческим сознанием. Поскольку эти теоретики полагают, что агенты действуют для того чтобы максимизировать полезность, они хотят, чтобы это было частью определения того, что значит быть агентом, а не эмпирическим утверждением о возможных внутренних состояниях и мотивациях. Концепция Самуэльсона, известная как RPT (Revealed Preference Theory, концепция выявленных предпочтений), — которую он описал в своей уже ставшей классической работе (Samuelson 1938), удовлетворяет этому требованию.
Тем, кто интерпретирует теорию игр в терминах RPT, не следует думать о теории игр как об эмпирическом описании мотивов субъектов из плоти и крови (т.е. реальных людей). Скорее, им нужно рассматривать теорию игр как математический аппарат для моделирования сущностей (как существующих, так и нет), которые последовательно выбирают элементы из взаимоисключающих множеств действий. В результате появляются устойчивые паттерны выборов, которые могут быть статистически смоделированы как максимизация функций полезности, с поправкой на стохастичность и шум.
Другие теоретики иначе понимают смысл теории игр. Они рассматривают теорию игр как инструмент, позволяющий описать логику стратегического мышления. Для принятия этой позиции мы должны исходить из того, что агенты в непараметрических ситуациях по крайней мере иногда делают то, что они делают, потому что теоретико-игровая логика рекомендует определенные действия в качестве «рациональных». Такое понимание теории игр включает в себя нормативный аспект, поскольку «рациональность» тут обозначает свойство, которым агент по меньшей мере должен хотеть обладать. Эти два очень общих способа понимания возможного использования теории игр согласуются с тавтологической интерпретацией максимизации полезности по Самуэльсону. Однако это философское различие не является пустым с точки зрения последователей теории игр. Как мы увидим далее в следующем разделе, те, кто надеется использовать теорию игр для объяснения стратегического мышления — в противоположность просто стратегическому поведению — сталкиваются со специфическими философскими и практическими проблемами.
Поскольку теория игр есть технология формального моделирования, нам нужен инструмент, для того чтобы математически мыслить максимизацию полезности. Таким инструментом является функция полезности. Мы введем общую идею функции полезности через ее частный случай, порядковую функцию полезности. (Позже мы встретимся также и с функцией полезности, которая включает в себя больше информации.) Отображение полезности называется «функцией», поскольку она соотносит порядок предпочтений агента с действительными числами. Предположим, что агент х предпочитает набор а набору b, а набор b — набору c. Тогда мы можем сопоставить эти предпочтения с рядом чисел, где функция соотнесет наивысший набор с крупнейшим числом в списке, второй в рейтинге — со вторым числом в списке, и так далее, т.е.:
набор a ≫ 3
набор b ≫ 2
набор c ≫ 1
Единственное свойство, которое зафиксировала эта функция — это порядок. Величины самих чисел неважны; это значит, что мы не должны думать, будто х получит в три раза больше пользы от набора а по сравнению с набором c. Мы можем представить ту же самую функцию полезности так:
набор a ≫ 7 326
набор b ≫ 12,6
набор c ≫ −1 000 000
Числа, которые мы используем в порядковой функции полезности, таким образом, ничего не квантифицируют. Функция полезности, в которой величины этих чисел приобретают значение, именуется «кардинальной». Когда кто-либо говорит о функции полезности, не уточняя, какой именно вид он имеет в виду, вам следует предполагать порядковую функцию. Именно ее мы будем использовать для того, чтобы разобрать наши первые игры. Позже, когда мы начнем говорить о решении игр, которые уже включают в себя рандомизацию — например, игру про переправу и три моста из первой части статьи — нам уже потребуются кардинальные функции полезности. Эту технику описали фон Нейман и Моргенштерн (von Neumann and Morgenstern 1944), и она, собственно, была главной составляющей в изобретенной ими теории игр. Но пока что, однако, нам потребуются только ординальные функции.
Игры и рациональность
Все ситуации, в которых как минимум один агент может максимизировать полезность лишь через предвосхищение (осознанно или нет) реакции одного или более агентов, называются игрой. Агенты, принимающие участие в игре, называются игроками. Если у всех агентов есть оптимальные действия, которые не зависят от поступков других, подобно параметрическим ситуациям, или условиям монополии, или идеальной конкуренции (см. раздел 1), мы можем смоделировать эту игру без обращения к теории игр; в иных же случаях нам без нее не обойтись.
Специалисты в теории игр исходят из того, игроки обладают способностью, которое в экономической литературе обычно именуют «рациональностью». Как правило, это формулируется в виде простых утверждений вроде «предполагается, что игроки рациональны». В критической литературе, как правило, или в случаях применения теории игр в гуманитарных дисциплинах, подобная риторика становится объектом нападок. В западной культурной традиции сеть референций термина «рациональность» крайне плотна и сложна, и сам термин зачастую использовался для того, чтобы с точки зрения нормативности маргинализировать такие обыкновенные и важные свойства как эмоции, женственность и эмпатия. Специалисты в области теории игр используют это понятия, как правило, вынося за скобки его идеологические коннотации. Для наших целей мы будем использовать термин «экономическая рациональность» как строго технический, и не нормативный, который отсылает к узкому и специфическому набору ограничений на предпочтения, с которыми имеют дело (1) изначальная версия теории игр фон Неймана и Моргенштерна и (2) концепция выявленных предпочтений (RPT).
Когда экономисты занимаются моделированием рынков, они также используют другое, не менее важное (для них) понятие рациональности — понятие «рациональных ожиданий». В этой фразе «рациональность» относится не к ограничениям предпочтений, но к не-ограничениям на обработку информации: рациональные ожидания — это идеализированные убеждения, являющиеся продуктом статистически верно взвешенного использования всей доступной агенту информации. Читатель должен иметь в виду, что два эти словоупотребления в рамках одной и той же дисциплины не связаны технически.
Более того, оригинальная RPT в течение этих лет уточнялась различными аксиомами для нужд моделирования. Как только мы начинаем рассматривать рациональность как техническое понятие, то каждый раз, вводя новые аксиомы, мы изменяем и понятие. Следовательно, в любой дискуссии, вовлекающей и экономистов, и философов, мы можем обнаружить, что все используют одно и то же слово, при этом имея в виду совершенно разные вещи. Это вызывает определенные трудности для тех, кому в новинку экономика, теория игр, теория принятия решений и философия действия.
В этой статье термин «экономическая рациональность» будет использоваться в техническом значении, которое он принимает в рамках теории игр, микроэкономики и формальной теории принятия решений, соответственно. Экономически рациональный игрок есть тот, кто может
(1) оценить результаты игры, т.е. ранжировать их по отношению к их вкладу в его благосостояние;
(2) вычислить пути достижения этих результатов, т.е. установить, какая последовательность действий вероятностно связана с соответствующим результатом; и
(3) выделить из набора альтернативных действий (это мы назовем «выбором» действия) такие, что приводят к наиболее предпочтительному результату, при этом учитывая действия других игроков.
Мы можем подытожить лежащую в основании этих рассуждений интуицию следующим образом: ту или иную сущность имеет смысл рассматривать в качестве экономически рационального агента до тех пор, пока у нее есть альтернативы и она выбирает из них, руководствуясь тем, что кажется ей наилучшим для ее целей — и это верно для нее чаще, чем обратное. (Для читателей, знакомых с работами Дэниела Деннета, мы можем сравнить идею экономически рационального агента с сущностями, которые Деннет описывает как интенциональные, и добавить, что мы можем предсказать поведение экономически рационального агента с опорой на интенциональную установку.)
Экономическая рациональность может в некоторых случаях достигаться лишь за счет внутренних вычислений агента, причем ему не обязательно осознавать, что он вычисляет или вычислил их условия и импликации. В других случаях экономическая рациональность может воплощаться в поведенческих установках, возникших в ходе естественного, культурного или рыночного отбора. Поэтому называя действие «выбранным», мы не обязательно подразумеваем, что этот выбор был свободным и осознанным. Мы просто имеем в виду, что действие было предпринято при наличии иной доступной альтернативы, где «доступность» понимается как нечто, что можно выяснить чисто аналитически. (Термин «доступное», когда его используют специалисты в теории игр, не должен пониматься как «метафизическая» или «логическая» доступность; почти всегда доступность следует понимать прагматически, контекстуально и предполагать возможность ее бесконечного пересмотра в ходе все более точного моделирования.)
Каждый игрок выбирает между как минимум двумя стратегиями. Стратегия — это предопределенная «программа игры», которая сообщает игроку, какие действия предпринимать в ответ на любую возможную стратегию, которую только могут использовать другие игроки. Значение фразы, выделенной курсивом, прояснится, когда мы приведем некоторые примеры игр.
Критически важный аспект спецификации игры касается объема информации, которым располагают игроки при выборе стратегии. Простейшие игры (с точки зрения их логической структуры) суть те, в которых агенты располагают полной информацией: то есть в каждый момент, когда стратегия требует от игрока предпринять некоторое действие, он знает всё то, что происходило в игре до этого момента. Настольная игра с последовательными ходами, в которой оба игрока видят все действия и в целом знают правила игры — типа шахмат — является примером простейшей игры. В то время как игра с переправой по мостам из первого раздела является примером игры с неполной информацией, поскольку беглец должен выбрать мост для переправы, не зная, какой мост избрал для засады его преследователь; а последний, соответственно, принимает решение, не зная о выборе своей жертвы. Поскольку теория игр имеет дело с экономически рациональным действиями, принимая во внимание стратегически значимые действия других игроков, вас не должен удивлять тот факт, что то, что думают, или во что не верят, игроки о действиях других, имеет большое значение для нашего анализа. Мы это далее еще увидим.
Деревья и матрицы
Разница между играми с полной и неполной информацией связана с различием между способами репрезентации игр, которые опираются на очередность игры (хотя и не тождественна этому различию). Давайте начнем с того, что установим различие между играми с последовательными и одновременными ходами (речь идет об информации). При первом приближении, кажется естественным полагать, что в игре с последовательным ходом игроки определяются со своей стратегией по очереди, а в игре с одновременным ходом игроки определяются со стратегиями одновременно. Однако это не совсем верно, поскольку стратегическое значение имеет не темпоральный порядок событий как таковой, но то, знают ли игроки — и когда они узнают — о действиях других игроков на момент совершения выбора. Например, если два конкурирующих друг с другом предприятия планируют свои маркетинговые кампании, одно из них может выбрать свою стратегию за месяцы до второго; но если ни одна из сторон не знает, что именно предприняла вторая (или предпримет, когда примет решение) — это игра с одновременным ходом. В шахматы же, напротив, обычно играют как в игру с последовательной очередностью хода: вы видите, что сделал ваш оппонент, прежде чем выбрать свое следующее действие. (Шахматы могут стать игрой с одновременным ходом, если каждый из игроков будет объявлять свой ход на общей доске, будучи изолирован от другого; но эта игра будет сильно отличаться от обычных шахмат.)
Выше было сказано, что различие между играми с последовательным и одновременным ходом не тождественны различию между играми с полной и неполной информацией. Хороший способ уточнить оба концепта — объяснить, почему это так. Как мы говорили выше, игры с одновременным ходом являются играми с неполной информацией. Однако некоторые игры могут быть смесью игр с одновременным и последовательным ходом. Например, две фирмы могут приступить к реализации своих маркетинговых стратегий независимо и в тайне друг от друга — но затем вступить в ценовую конкуренцию, где их действия будут полностью видимы. Если бы оптимальные маркетинговые стратегии частично или полностью зависели от того, что игроки ожидают от дальнейшего противостояния цен, тогда оба этапа необходимо было бы анализировать как единую игру, в которой этап последовательных ходов сменялся бы этапом игры с одновременным ходом. Целые игры, которые включают в себя смешанные этапы подобного рода, являются играми с неполной информацией, даже если и некоторые из ее этапов могут разыгрываться поочередно. Игры с полной информацией, как и подразумевает их название, суть ситуации, где нет одновременных ходов (и где ни один из игроков никогда не забывает о том, что было прежде).
Как мы уже упомянули выше, игры с полной информацией — это простейший, с точки зрения логики, вид игр. Игроки и аналитики в подобных играх (до тех пор, пока они конечны, т.е. заканчиваются после определенного количества действий) могут использовать прямые процедуры для предсказания итогов. Игрок выбирает свое первое действие, учитывая возможные реакции оппонентов на него и контрдействия, что будут доступны ему в дальнейшем. В этом случае он задается вопросом о том, какой из доступных конечных результатов ему наиболее полезен, и выбирает тот ход, который должен быть первым в цепочке событий, приводящей к этому результату. Этот процесс называется обратной индукцией (поскольку рассуждение идет обратно, от конечных результатов к моменту выбора).
Об обратной индукции и ее характеристиках будет мы будет говорить подробнее в следующем разделе, при обсуждении равновесия и выбора равновесия. Пока что мы упомянули ее лишь для того, чтобы с ее помощью представить один из двух типов математических объектов, которые используются для репрезентации игр: игровых деревьев. Игровое древо — это пример того, что математики называют ориентированным графом (или, кратко, орграфом). Он представляет собой множество вершин, связанных таким образом, что граф целиком имеет направление. Мы можем строить деревья сверху вниз или слева направо. В первом случае вершины наверху рассматриваются как более ранние поступки. Если же мы строим наш граф слева направо, то хронологически более ранние события мы размещаем левее. Неразмеченное древо имеет подобную структуру:
Репрезентация игр при помощи деревьев удобна для того, чтобы визуализировать обратную индукцию. Представьте, что игрок (или аналитик) начинает на том краю дерева, где отображены все возможные результаты игры, а потом двигается в обратном направлении, пытаясь определить стратегии, которые к ним приводят.
Поскольку функция полезности для игрока указывает на предпочтительные для него результаты, мы также знаем, какой путь он изберет. Конечно, не все из этих путей будут доступны, поскольку другой игрок также участвует в выборе пути и не будет совершать действия, которые ведут к менее желательным результатам. Мы рассмотрим примеры развития игры в ходе подобных интеракций и детально разберем техники рассуждения на этих примерах после того, как опишем ситуацию, для моделирования которой мы можем использовать деревья.
Деревья используются для репрезентации последовательных игр, поскольку показывают порядок действий игроков. Однако игры иногда изображаются на матрицах, а не деревьях. Это второй тип математических объектов, которые используются для репрезентации игр. Матрицы, в отличие от деревьев, просто показывают результаты — представленные в терминах функции полезности — каждой возможной комбинации стратегий игроков. Например, можно отобразить игру с переправой через реку из первого раздела на матрице, поскольку в этой игре и у беглеца, и у преследователя есть только один ход, и оба игрока принимают свое решение, не зная, какое решение примет другой. Соответственно, вот часть матрицы:

Доступные беглецу стратегии: перейти по безопасному мосту, пойти на риск быть раздавленным камнями или риск быть искусанным кобрами — мы отобразим на соответствующих строках матрицы. Соответственно, на столбцах отобразим опции преследователя — ждать на безопасном посту, ждать на каменистом мосту и ждать на мосту с кобрами. Каждая из ячеек матрицы показывает — или, скорее покажет, как только наша матрица заполнится — результаты в терминах выигрыша, которую придется понести игрокам. Выигрыш для игрока — это просто число, присваиваемое порядковой функцией полезности положению дел, соответствующих результатам игры.
Для каждого результата выигрыш Строки всегда отображается до выигрыша Столбца. Так, например, верхний левый угол нашей матрицы показывает, что если беглец переправляется через реку по безопасному мосту, а преследователь его там ожидает, то выигрыш беглеца 0, а преследователя 1. Мы интерпретируем выигрыши через функции полезности игроков, которые в этой игры очень просты. Если беглец безопасно перебирается через реку, он зарабатывает 1, если нет, то 0. Если беглец не справится с переправой, потому ли, что его пристрелит охотник, завалит камнями или укусит кобра, охотник зарабатывает 1, а беглец 0.
Мы коротко пройдемся по заполненным ячейкам матрицы, а потом объясним, почему мы пока не можем заполнить остальные ячейки. Когда преследователь встречает беглеца на мосту, который последний избрал для переправы, беглец гибнет. Все эти результаты приводят к вектору выигрышей (0,1). Вы можете видеть его по диагонали, пересекающей матрицу с левого верхнего угла по правый нижний. Когда беглец выбирает безопасный мост, а преследователь ждет его на каком-то другом, беглец успешно переправляется через реку — а мы получаем вектор (1,0). Эти результаты отображены во всех оставшихся двух ячейках верхней строки. Все остальные ячейки пока что заполнены вопросительными знаками. Почему? Дело в том, что если беглец выбирает мост с камнепадами или кобрами, он вводит в игру параметрические факторы. В этих случаях он рискует быть убитым и прийти к развязке типа (0,1) независимо от выбора преследователя. А нам пока не хватает понятий для того, чтобы корректно отобразить эти результаты при помощи функций полезности — но вскоре они у нас появятся, и это даст нам ключ для решения трудности, обсуждавшийся в разделе 1.
Матричные игры обычно называют «нормальной формы игры» или «стратегической формы игры», а древовидные игры называют «развернутой формой игры». Эти типы игр не эквивалентны, поскольку в играх развернутой формы есть информация, которой нет в играх стратегической формы — это информация о последовательности ходов в игре и объеме знания игроков о структуре самой игры. В целом, игры стратегической форм могут репрезентировать любую из игр развернутой формы, так что стратегическую форму можно рассматривать в качестве множества игр развернутой формы. Когда порядок ходов не имеет значения для результата игры, вам следует рассматривать стратегическую форму игры, поскольку она содержит все то, о котором вам стоит беспокоиться. Когда же порядок ходов важен, развернутая форма строго необходима, в противном случае ваши выводы будут ненадежны.
Дилемма заключенного как пример представления игры в стратегической и развернутой форме
Различия, описанные выше, сложно понять, если опираться только на абстрактные описания. Лучше всего проиллюстрировать их примером. Для этого мы возьмем самую известную изо всех игр: дилемму заключенного. Она позволяет проиллюстрировать логику проблемы Кортеса и солдат Генри V из первого раздела, а также гоббсовских людей до момента создания Левиафана.
Однако по причинам, которые станут вам ясны позже, не стоит воспринимать дилемму заключенного (ДЗ) как типичную игру: она таковой не является. Мы используем ее в качестве развернутого примера тут только потому, что она хорошо подходит для иллюстрации отношений между стратегической и развернутой формами игр, а позже — для иллюстрации отношений между однократными и повторяющимися играми (см. часть 4 ниже).
Своим названием эта игра обязана ситуации, которой обычно ее иллюстрируют. Предположим, что полицейские задерживают двух людей, которых подозревают в совершении вооруженного ограбления. Однако у правоохранителей нет доказательной базы для того, чтобы предъявить задержанным обвинение в суде. Однако у них достаточно доказательств для того, чтобы упрятать каждого из них за решетку за угон машины. Поэтому следователь делает каждому заключенному следующее предложение: если тот чистосердечно сознается в ограблении и даст показания против своего сообщника, а второй откажется признать свою вину, то первый выйдет на свободу, а второй получит десять лет тюрьмы. Если признательные показания дадут оба, то каждый получит по 5 лет. Но если же оба изберут хранить молчание, то получат по два года за угон.
Первый шаг в моделировании игры с двумя заключенными — представить ситуацию с помощью функции полезности. Следуя традиции, назовем заключенных «Игрок 1» и «Игрок 2». Для обоих игроков порядковая функция полезности одинакова:
Свобода ≫ 4
2 года ≫ 3
5 лет ≫ 3
10 лет ≫ 0
Числа в вышеприведенной функции нам нужны для выражения выигрыша каждого игрока при различных возможных результатах в данной ситуации. Мы можем изобразить их проблему на матрице, которая описывает, как взаимодействуют отдельные варианты — это их игра в стратегической форме:

Каждая из ячеек матрицы отображает выигрыш каждого игрока для каждой комбинации действий. Выигрыш Игрока I — первое число в каждой паре, Игрока II — второе. Итак, если оба игрока дадут показания, то каждый выиграет 2 очка (5 лет тюрьмы). Мы видим это в верхней левой ячейке нашей матрицы. Если ни один из них не даст показаний, то каждый выиграет по 3 очка (два года тюрьмы). Мы видим это в нижней правой ячейке. Если Игрок I дает показания, а игрок II нет, Игрок I выигрывает со счетом 4,0 (свобода против десяти лет заключения), что можно видеть в верхней правой ячейке. Обратная ситуация, в которой Игрок II признается, а Игрок I молчит — в нижней левой ячейке.
Каждый игрок оценивает здесь два доступных ему действия, сравнивая свои личные выигрыши в каждом столбце — это позволяет им судить, какое из действий предпочтительнее, предпочтительнее для них, относительно каждого возможного действия их партнера. Если Игрок II даст показания, то Игрок I получает 2 очка за свои показания и 0 в случае молчания. Если Игрок II молчит, то Игрок I получает 4 очка за показания и 3 за молчание. Поэтому Игроку I лучше признаться, независимо от того, что сделает Игрок II.
Игрок II, тем временем, сравнивает свои выигрыши по каждой строке и приходит к точно такому же выводу, что и Игрок I. Везде, где конкретное действие игрока превосходит все другие для каждого возможного действия оппонента, мы говорим, что первое действие строго доминирует над вторым. В ДЗ признание строго доминирует над молчанием для обоих игроков. Оба игрока понимают это и тем самым полностью отбрасывают искушение отклониться от строго доминируемого пути. Соответственно, они оба признаются — и оба сядут в тюрьму на 5 лет.
Игроки, равно как и аналитики, могут предсказать подобный итог, используя механическую процедуру, известную как последовательное исключение строго доминируемых стратегий. Первый игрок, изучив матрицу, может увидеть, что его выигрыш в каждой ячейке первой строки выше, чем его выигрыш в ячейках строкой ниже. Следовательно, игра по нижнему ряду (т.е. хранение молчания) не может максимизировать его полезность, независимо от того, что делает второй игрок. Поскольку первый игрок никогда не будет использовать стратегию по нижней строке, мы можем просто удалить нижнюю строку из матрицы. Теперь очевидно, что второй игрок не будет отказываться от признания, поскольку его выигрыш от признания в двух оставшихся ячейках выше, чем выигрыш от молчания. Так что теперь мы можем удалить правый столбец из игры. У нас осталась только одна ячейка, которая соответствует обоюдному признанию вины.
Поскольку рассуждение, которое привело нас к исключению всех остальных возможных результатов, на каждом шаге отталкивалось от предпосылки, что оба игрока экономически рациональны — иными словами, мы выбирали стратегии, которые приводили к более высокому выигрышу по сравнению с другими — у нас есть сильные основания рассматривать взаимное признание вины как решение игры, т.е. результат, к которому она должна прийти, если экономическая рациональность является корректной моделью для поведения игроков. Стоит отметить, что порядок удаления строго доминируемых строк и столбцов неважен. Если бы мы сначала удалили правый столбец, а потом нижнюю строку, мы бы пришли к тому же решению.
Мы уже неоднократно говорили о том, что дилемма заключенного во многих отношениях нетипична. Так, все ее столбцы или строки или строго или строго доминируемые, или строго доминирующие. Для любой игры в стратегической форме верно, что последовательное исключение строго доминируемых стратегий гарантированно приведет вас к уникальному решению. Однако, как мы покажем позже, для многих игр это условие не применяется, и решение нашей аналитической задачи становится менее прямолинейным.
Читатель, возможно, заметил нечто тревожащее в результатах игры заключенных. Если бы оба игрока решили хранить молчание, они бы пришли к результату в нижней правой ячейке, при котором оба бы получили лишь два года тюрьмы, и, соответственно, больше полезности, чем в случае признания. Это самый важный аспект ДЗ, и в теории игр он довольно распространен. Мы вернемся к этому, когда будем обсуждать равновесные состояния. Пока что, однако, давайте продолжим рассматривать разницу между играми в стратегической и развернутой форме.
Когда дилемму заключенного выносят на суд неспециалистов, часто можно услышать, что следователю нужно развести подозреваемых по разным камерам, чтобы они не могли общаться друг с другом. Причины тому кажутся самоочевидными: если бы игроки могли общаться, они бы увидели, что им обоим выгодно хранить молчание, и, соответственно, договорились бы об этом, не так ли? Может показаться, что это позволит игрокам избавиться от убеждения в необходимости сознаться, опережая возможное предательство другого. В действительности же эта интуиция обманчива, а вывод из нее ложен.
Когда мы рассматриваем дилемму заключенного как игру в стратегической форме, мы неявно предполагаем, что заключенные не могут прийти к взаимовыгодному соглашению, поскольку они выбирают свои действия одновременно. В этом случае предварительная договоренность никак им не помогает. Если первый игрок убежден, что его партнер будет придерживаться условий сделки, он может воспользоваться возможностью выйти на свободу, дав показания. Конечно же, он поймет, что то же самое искушение встанет и перед вторым игроком; и в этом случае он тем более должен будет признаться, дабы избежать наихудшего для себя исхода. Соглашение заключенных ни к чему не приводит оттого, что у них нет способа принудить друг друга к его исполнению; их данные друг другу обещания представляют собой то, что теоретики игр называют «пустым разговором».
Но теперь предположим, что заключенные принимают решения не одновременно. То есть предположим, что игрок II может сделать выбор после наблюдения за действиями игрока I. Это та ситуация, которую люди, уверенные в необходимости отсутствия коммуникации, должны иметь в виду. Теперь игрок II сможет увидеть, что игрок I остался непоколебим, когда дело дошло до выбора игроком I, и ему не следует беспокоиться о том, что его обманут. Однако это ничего не меняет, лучше всего повторно представить игру в развернутой форме. Это позволит нам ввести деревья игры и соответствующий им метод анализа.
Прежде всего, рассмотрим определения основных понятий, которые будут полезны при анализе игровых деревьев:
Вершина: точка, в которой игрок принимает решение.
Начальная вершина: точка, в которой происходит первое действие игры.
Терминальная вершина: любая вершина, достижение которой оканчивает игру. Каждой терминальной вершине соответствует результат.
Подыгра: любое связанное множество вершин и разбиений, отходящих из одной единственной вершины.
Выигрыш: количество порядковой полезности, которую игрок извлекает из того или иного результата.
Результат: приписывание множества выигрышей, по одному на каждого игрока в игре.
Стратегия: программа, предписывающая игроку, какое действие следует совершать на каждой из вершин игрового древа, где он может сделать выбор.
Эти краткие определения могут быть не очень ясны до тех пор, пока вы не начнете их использовать по ходу нашего анализа деревьев. Вам, пожалуй, лучше всего возвращаться к этому списку, пока мы будем обсуждать примеры. К тому времени, как вы разберетесь с каждым из примеров, эти понятия и их значение станут для вас интуитивно ясны.
Чтобы сделать это упражнение максимально поучительным, давайте предположим, что заключенные изучили нашу матрицу и, увидев, что для них обоих наилучшим является результат из нижней правой ячейки, заключили соглашение о сотрудничестве. Первый игрок должен сохранить молчание первым, после чего второй поступит также, когда полиция попросит его сделать выбор. Мы назовем стратегию соблюдения соглашения «сотрудничеством» и пометим его на дереве ниже литерой «С» (от «cooperation»). Стратегию же нарушения договора мы назовем «отступничеством» и обозначим его литерой «D» (от «defection»). Каждая вершина пронумерована 1, 2, 3, …, сверху вниз, для удобства использования в обсуждении.
Итак, вот наше дерево:
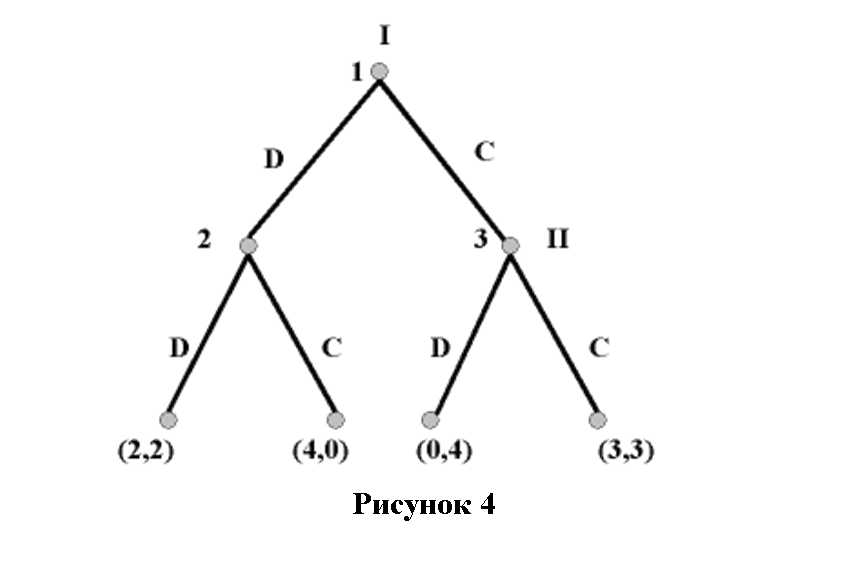
Давайте взглянем на терминальные вершины (они расположены внизу). Они отражают возможные результаты. Каждая из них связана с раздачей выигрышей: как и при игре в стратегической форме, сначала указан выигрыш первого игрока, затем второго. Каждая из структур, что берет начало в вершинах 1, 2 и 3, является подыгрой.
Мы начнем наш обратно-индуктивный анализ с подыгр, которые возникают последними в игре — и будем использовать технику алгоритма Цермело. В подыгре, начинающейся от вершины 3, второй игрок должен выбрать между выигрышем 4 и 3 очков. (Обратите внимание на второе число, обозначающее выигрыш второго игрока в каждом множестве на терминальной вершине, спускающейся от вершины 3). Второй игрок выигрывает больше, играя D. Поэтому мы можем заменить всю подыгру назначением выигрыша (0,4) непосредственно вершине 3, так как именно этот результат будет реализован, если игра достигнет этой вершины.
Теперь рассмотрим подыгру, берущую начало от вершины 2. Здесь второй игрок выбирает между 2 и одним из нулей. Он получит более высокий выигрыш, играя D. Мы можем поэтому присвоить выигрыш (2,2) непосредственно вершине 2. Теперь мы переходим к подыгре, идущей от вершины 1. (Эта подыгра, конечно, тождественна самой игре; все игры являются подыграми самих себя). Теперь первый игрок выбирает между результатами (2,2) и (0,4). Сравнив первые числа в каждом из этих множеств, он видит, что, играя D, он получает более высокий выигрыш — 2. D — это значит дать показания. Таким образом, первый игрок дает показания, а затем их дает и второй, приводя нас к тому же результату, что и при игре в стратегической форме.
Интуитивно ясно, что произошло: первый игрок понял, что если он сыграет C (промолчит) в вершине 1, тогда второй сможет максимизировать свою полезность, предав его и сыграв D. (На дереве это происходит на вершине 3). Это оставляет первого игрока с выигрышем 0 (десять лет в тюрьме), чего он может избежать, только с самого начала играя D. Поэтому он нарушает соглашение.
Таким образом, мы видим, что в случае дилеммы заключенного, будь она игрой хоть с одновременным, хоть с последовательным ходом, обе версии дают один и тот же результат. Однако в других играх это не всегда так. Кроме того, с помощью алгоритма Цермело можно решать только (последовательные) игры с полной информацией в развернутой форме.
Как мы уже упоминали в этой главе, иногда мы должны представлять одновременные действия внутри игр с последовательной очередностью хода на всех остальных этапах. (Во всех таких случаях игра в целом будет игрой с неполной информацией, поэтому мы не сможем ее решить с помощью алгоритма Цермело). Мы представляем такие игры с использованием информационных множеств. Рассмотрим следующее дерево:
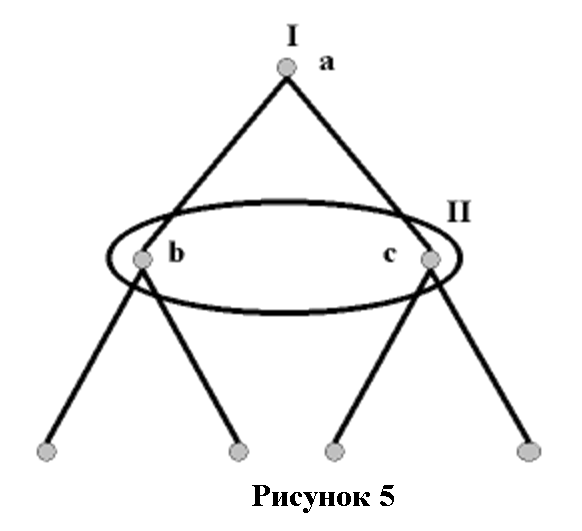
Овал, нарисованный вокруг вершин b и c, указывает, что они принадлежат одному информационному множеству. Это означает, что на этих вершинах игроки не могут отследить путь, который их сюда привел. При выборе стратегии игрок II не знает, находится ли он в b или c. (По этой причине в развернутых играх фактически нумеруются информационные множества, которые понимаются как «точки действия», а не сами вершины — поэтому вершины внутри овала обозначены буквами, а не цифрами). Иначе говоря, игрок II, делая свой выбор, не знает, что сделал первый на вершине a. Как вы помните, именно это определяет два хода как одновременные. Таким образом, мы можем видеть, что метод представления игр на деревьях является полностью общим. Если ни одна вершина после начальной не принадлежит отдельному информационному множеству на своем дереве, то в игре есть только одна подыгра (она сама), а вся игра является одновременной. Если хотя бы одна вершина принадлежит тому же информационному множеству, что и какая-либо другая, в то время как все остальные остаются обособленными, то наша игра включает в себя как одновременные, так и последовательные ходы и по-прежнему остается игрой с неполной информацией. Игра с полной информацией имеет место лишь тогда, когда все информационные множества содержат только одну вершину.
Концепции решения и равновесие
Результат, обозначенный нами как (2,2) в дилемме заключенного и соответствующий взаимному предательству, был назван «решением» игры. Следуя принятой в экономике практике, специалисты в области теории игр именуют решения игр равновесиями. Философски подкованные читатели наверняка захотят задать концептуальный вопрос: что именно «уравновешивается» в результатах игр, позволяя нам, таким образом, называть их «решениями»? Когда мы говорим, что физическая система находится в равновесии, мы имеем в виду, что она находится в устойчивом состоянии, при котором все каузальные силы внутри системы уравновешивают друг друга и таким образом оставляют систему «в покое» до тех пор, пока в нее не проникнет некая экзогенная (т. е. внешняя) сила. Именно это традиционно имеют в виду экономисты, когда говорят о «равновесии»; они рассматривают экономические системы точно так же, как и физические: как совокупности взаимно ограничивающих (часто каузальных) отношений. Равновесия таких систем являются их эндогенно стабильными состояниями. (Следует отметить: бывает так, что эндогенно стабильные состояния для некоторых физических, так и экономических систем оказываются недоступны прямому наблюдению, поскольку никогда не бывают изолированы от экзогенных воздействий, что смещают и дестабилизируют их. В классической механике, как и в экономике, понятия равновесия используются в качестве инструментов анализа, а не предсказаний относительно того, что мы ожидаем как наблюдатели). Как мы увидим в последующих разделах, мы можем пользоваться таким пониманием равновесия в теории игр.
Однако, как мы отметили в разделе 2.1, некоторые рассматривают теорию игр как теорию, объясняющую стратегическое мышление. Для них решением игры должен быть результат, который рациональный агент мог бы предсказать, опираясь только на средства рационального вычисления. Для таких теоретиков затруднения, связанные с концепциями решения не так важны, как для тех, кто не пытается использовать теорию игр в качестве вспомогательного инструмента в рамках общего анализа рациональности. Но интерес философов к теории игр чаще всего вызван именно этим стремлением, в отличие от интереса экономистов и других ученых.
Полезно начать наше обсуждение, вернувшись к дилемме заключенного, ввиду ее необычайной простоты с точки зрения проблем с концепциями решения. То, что мы назвали тогда «решением», было уникальным равновесием Нэша для этой игры (названо в честь Джона Нэша, математика, лауреата премии по экономике памяти А. Нобеля, очень много сделавшего для расширения и обобщения новаторской работы фон Неймана и Моргенштерна в Nash 1950).
Равновесие Нэша (далее «РН») применяется к наборам стратегий, по набору для каждого участника игры. Набор стратегий — это РН в том случае, если ни один игрок уже не может, сменив стратегию и учтя стратегии своих партнеров по игре, увеличить свой выигрыш. Обратите внимание на то, насколько близка эта идея идее строгого доминирования: никакая стратегия не может быть РН-стратегией, если она строго доминируема. Поэтому, если последовательное исключение строго доминируемых стратегий приводит нас к уникальному результату, мы знаем, что этот вектор приводит к уникальному РН. Сейчас почти все теоретики согласны с тем, что избегание строго доминируемых стратегий является минимальным требованием к агенту, который претендует на экономическую рациональность. Игрок, который сознательно выбирает строго доминируемую стратегию, прямо нарушает пункт (iii) определения экономической агентности из раздела 2.2. Это означает, что если игра имеет результат, который является уникальным РН — как в случае обоюдной дачи показаний в дилемме заключенного, — он должен быть ее уникальным решением. Это одна из самых главных причин, по которой дилемма заключенного является «легкой» (и нетипичной) игрой.
Мы можем указать еще один класс игр, в котором РН всегда не только необходимая, но и достаточная концепция решения. Это конечные игры с совершенной информацией и нулевой суммой. Игра с нулевой суммой (в случае игры с участием всего двух игроков) — это игра, в которой игрок не может улучшить свое положение, не ухудшив положение другого (простейший пример тут — крестики-нолики: любой ход, который приближает одного игрока к победе, приближает противника к проигрышу, и наоборот).
Мы можем определить, является ли некая игра игрой с нулевой суммой, изучив функции полезности игроков: в играх с нулевой суммой они будут зеркальными отображениями друг друга, а результатам с высоким рейтингом для одного игрока будут соответствовать результатам с низким рейтингом для другого, и наоборот.
В такой игре, если я разыгрываю стратегию, при которой, с учетом вашей стратегии, я не могу сделать ничего лучше, и если вы также разыгрываете подобную стратегию, то, поскольку предпринятая мной смена стратегии должна поставить вас в худшее положение и наоборот, наша игра не может иметь никакого решения, совместимого с нашей общей экономической рациональностью, отличной от ее уникального РН.
Иначе говоря, в игре с нулевой суммой моя стратегия, максимизирующая мой минимальный выигрыш, если вы играете наилучшим возможным образом и одновременно делаете то же самое, просто эквивалентна применению наших наилучших стратегий. Поэтому эта пара так называемых «максимин» процедур гарантировано приводит к уникальному решению игры, которое одновременно будет его уникальным РН. (В крестиках-ноликах это просто ничья: ни вы, ни я не можем получить ничего больше ничьей, если мы оба пытаемся победить и стремимся не проиграть.)
Однако большинство игр не обладают этим свойством. В этой статье невозможно перечислить все типы затруднений, делающие игру проблематичной с точки зрения возможных решений. (Во-первых, крайне маловероятно даже то, что теоретики уже нашли всех возможные проблемы). Однако мы можем попытаться рассмотреть это все немного обобщенно.
Во-первых, есть проблема с тем, что большинство игр с ненулевой суммой имеют больше одного РН, но не все РН выглядят одинаково удовлетворительными решениями для стратегически осмотрительных игроков. Взгляните на игру в стратегической форме (взято из Kreps 1990: 403):

В этой игре есть два РН: s1-t1 и s2-t2. (Следует обратить внимание на то, что ни одна строка или столбец не являются здесь строго доминируемыми, но если I играет s1, то II не может сделать ничего лучше t1, и наоборот; то же верно и для пары s2-t2). Если РН — это наша единственная концепция решения, то мы будем вынуждены признать, что любой из этих результатов в равной степени убедителен в качестве решения. Однако, если теория игр рассматривается как объяснительная и/или нормативная теория стратегического мышления, то видно, что тут чего-то не хватает: не сойдутся ли рассудительные и полностью информированные игроки на s1-t1? (Заметьте, что это не похоже на ситуацию с дилеммой заключенного, в которой социально наилучшая ситуация недостижима, поскольку не является РН. А в игре выше у обоих игроков есть все основания стремиться сойтись на РН, которое для них выгодно).
Это иллюстрирует тот факт, что РН является относительно (с точки зрения логики) слабой концепцией решения, часто не способной предсказать интуитивно разумные решения, применение одного лишь РН не позволяет игрокам использовать принципы равновесного выбора, которые если и не обязательны с точки зрения экономической рациональности (или какой-ли еще более философски амбициозной концепции рациональности), то по меньшей мере представляются как разумными, так и вычислимыми. Рассмотрим другой пример (Kreps 1990: 397):
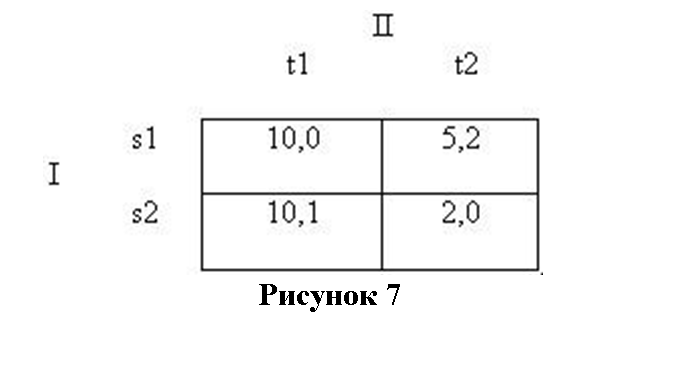
Здесь ни одна стратегия не доминирует строго над другой. Однако s1 слабо доминирует над s2, так как I преуспевает по меньшей мере в той же степени, разыгрывая s1 вместо s2 для любого хода II, и выигрывает больше, если II отвечает ходом t2. Так не следует ли игрокам (и аналитикам) просто удалить слабо доминируемую строку s2? Если сделать это, то t1 станет строго доминируемым, а РН s1-t2 остается единственным решением.
Однако, как показывает на этом примере Крепс, у идеи, что слабо доминируемая стратегия должна удаляться так же, как и строго доминируемая, есть любопытные последствия. Давайте немного изменим выигрыши игры:

s2 по-прежнему слабо доминируема; но из двух нэшевский равновесий вариант s2-t1 теперь становится наиболее привлекательным для обоих игроков. Так почему же аналитику исключать эту возможность? (Обратите внимание, что эта игра, опять же, не воспроизводит логику из дилеммы заключенных. Там у исключения наиболее привлекательного результата, молчания, есть смысл, поскольку у обоих игроков есть стимулы для одностороннего отказа от него, так что там мы имеем дело не с РН. Но в случае с s2-t1 в настоящей игре это не так. Вы уже начинаете понимать, почему мы назвали игру заключенных «атипичной»?).
Аргумент в пользу исключения слабо доминируемых стратегий такой: что игрок I может нервничать, опасаясь, что игрок II не обязательно экономически рационален (или II боится, что I может оказаться не рационален экономически, или II переживает, что I опасается того, что II не рационален… и так далее до бесконечности), и поэтому есть некоторая вероятность, что II сыграет t2. Если всерьез принимать возможность того, что игрок может не быть экономически рационален, то у нас появляется аргумент в пользу устранения слабо доминируемых стратегий: игрок I таким образом страхуется от наихудшего для себя результата, s2-t2. Конечно, страхуясь подобным образом, он кое-что теряет, уменьшая свой ожидаемый выигрыш с 10 до 5. С другой стороны, мы можем представить, что игроки поговорили перед игрой и договорились разыгрывать коррелированные стратегии, чтобы сойтись на s2-t1, тем самым устраняя неопределенность, которой вызвано желание исключить слабо доминируемую строку s1 и вместо этого исключить s1-t2 из ряда вероятных решений!
Любой предлагаемый принцип решения игр, который позволил бы нам отбросить одно или несколько РН в качестве возможных решений, называется рафинированием РН. В рассматриваемом случае устранение слабо доминируемых стратегий является одним из возможных рафинирований, поскольку оно исключает РН s2-t1, а корреляция — другим рафинированием, поскольку вместо этого она очищает другое РН, s1-t2. Итак, какое рафинирование является более подходящим в качестве концепции решения? Те, кто рассматривает теорию игры как объяснительную и / или нормативную теорию стратегической рациональности, создали немалый корпус литературы, где обсуждаются достоинства и недостатки большого количества рафинирований. В принципе, нет никаких ограничений на количество возможных рафинирований, так как не может быть никаких ограничений на количество возможных философских позиций относительно того, какими принципами могут или не могут руководствоваться рациональные заинтересованные стороны, либо иметь опасения или ожидания или уверенность в отношении того, каким принципам следуют другие игроки.
Теперь мы ненадолго отвлечемся, чтобы сделать терминологическое замечание. В предыдущих изданиях настоящей статьи мы называли теоретиков, предпочитающих интерпретацию функций полезности в духе RPT, «бихевиористами». Термин подчеркивал, что подход RPT приравнивает выбор к экономически последовательным действиям, а не обращается к ментальным конструктам. Однако это словоупотребление, вероятно, вызовет путаницу из-за недавно вошедшей в моду поведенческой теории игр Колина Камерера (Camerer 2003). Эта исследовательская программа пытается ввести в модели теории игр обобщения, выведенные главным образом из экспериментов с людьми: выводы, которые люди делают из наличной информации, оказываются отличными от тех, которые бы сделали экономические агенты («фрейминг»). Применения теории Камерера также обычно содержат специфические предположения о функциях полезности, также опирающиеся на экспериментальные данные. Например, можно предполагать, что игроки готовы идти на компромиссы между неравенством в распределении выигрышей среди игроков и объемом собственного выигрыша. Мы обсудим поведенческую теории игр в разделах 8.1, 8.2 и 8.3. Пока же обратите внимание, насколько важно для подобного использования теории игр предположение, что психологические представления о ценности едины для всех людей. Потому было бы неверно ссылаться на поведенческую теорию игр как бихевиористскую. Но именование традиционной экономической теории, опирающейся на выявленные предпочтения, «бихевиористской» теорией, создает ненужную путаницу. Поэтому мы будем впредь называть конвенциональную теорию «непсихологической» теорией игр. Под этим мы подразумеваем теорию игр, используемую большинством экономистов, которые при этом не занимаются поведенческой экономикой. Они рассматривают теорию игр как абстрактную математику стратегического взаимодействия, а не как попытку описания особых психологических диспозиций, возможно, типичных для людей.
Специалисты в непсихологической теории игр склонны скептически оценивать большую часть уточнений, привносимых поведенческой теорией игр. Это с очевидностью вызвано тем, что она полагается на интуиции о том, какие выводы люди должны считать разумными. Как и большинство ученых, теоретики непсихологических игр скептически оценивают силу и основания каких бы то ни было философских допущений, взятых в качестве ориентира для эмпирического и математического моделирования.
Однако поведенческую теорию игр можно понимать и иначе: как уточнение теории игр, не обязательно затрагивающее ее концепции решения. Она ограничивает базовые аксиомы теории, чтобы применять ее к особому классу агентов — психологически типичных людей. Ограничение нужно для работы с суждениями и предпочтениями, которые люди находят естественными, независимо от того, кажутся они рациональными или нет (а они зачастую ими не являются). Непсихологическая и поведенческая теории игр едины в том, что ни одна из них не является нормативной — хотя обе они часто используются для описания норм, преобладающих в группах игроков, а также объяснения того, почему нормы могут оставаться неизменными в группах игроков, даже если они оказываются менее рациональными с философской точки зрения. Обе теории, полагают, что задача прикладной теории игр состоит в предсказании результатов эмпирических игр при заданном распределении стратегических диспозиций и распределении ожиданий относительно стратегических диспозиций других игроков, которые оформляются изменениями в окружении игроков, включая институциональное давление, структуры и эволюционный отбор. Поэтому мы объединим исследователей непсихологической и поведенческой теорий игр в группу дескриптивистов лишь затем, чтобы противопоставить их нормативным теоретикам игр.
Дескриптивисты часто склонны сомневаться в том, в поисках общей теории рациональности есть какой-либо смысл. Институты и эволюционные процессы создают множество самых разнообразных условий, и то, что считается рациональной процедурой в одной среде, может не выглядеть предпочтительным в других. С другой стороны, сущность, которая как минимум стохастически (т.е., статистически чаще, чем нет, невзирая на степень зашумленности) не отвечает минимальным требованиям экономической рациональности, не может быть, кроме как случайно, названа как стремящейся к максимизации функции полезности. К таким сущностям теория игр не исходно не применяется.
Это не подразумевает, что теоретики непсихологических игр отвергают все принципиальные способы ограничения множеств РН подмножествами на основании относительной вероятности их возникновения. В частности, теоретики непсихологических игр склонны симпатизировать подходам, которые смещают акцент с рациональности на соображения, касающиеся информационной динамики игр. Возможно, мы не должны удивляться тому, что РН-анализ сам по себе часто мало может нам рассказать о прикладном, эмпирическом интересе в играх стратегической формы (напр., с рис. 6 выше), в которых информационная структура игры не отображается. Вопросы выбора равновесия намного более эффективно решаются для игр в развернутой форме.
Совершенствование подыгр
Для углубления нашего понимания игр с развернутой формой нам нужен пример с более интересной структурой, чем предлагает ДЗ.
Рассмотрим игру, описанную этим деревом:
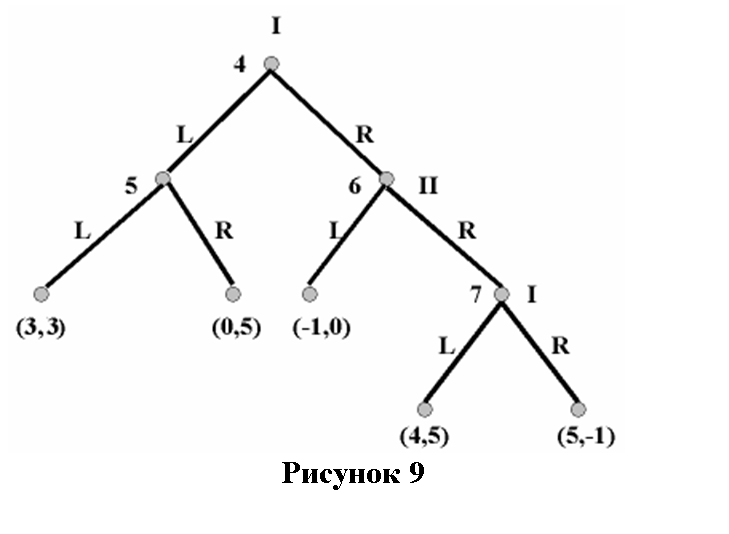
Эта игра не призвана отражать какую-либо вымышленную ситуацию, это просто математический объект. (L и R здесь просто обозначают «левый» и «правый» соответственно.)
Теперь рассмотрим стратегическую форму этой игры:
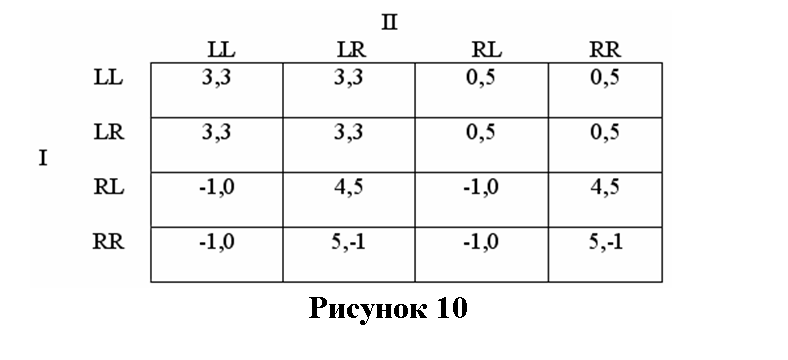
Если вы не очень поняли, почему эта матрица выглядит так, вспомните, что стратегия должна указывать игроку, что делать на каждом информационном множестве, где у игрока есть ход. Поскольку в нашем примере каждый игрок выбирает из двух действий на информационном множестве (которых тоже два), то стратегий у каждого игрока всего четыре. Первая буква в обозначении стратегии сообщает игроку, что делать, когда он достигает первого информационного множества, вторая — когда достигнут второй. Т.е. LR для игрока II говорит ему играть L, если он оказывается перед множеством 5, и R, если он имеет дело со множеством 6.
Если вы рассмотрите изображенную на рисунке 10 матрицу, вы увидите, что среди РН есть (LL, RL). Это немного озадачивает, поскольку если игрок I достигнет своего второго информационного множества (7) в игре с развернутой формой, он вряд ли захочет сыграть там L; он выиграет больше, играя R в вершине 7. Один только поиск нэшевских равновесий не замечает этого, потому что РН нечувствительно к тому, что происходит вне [хода] розыгрыша (off the path of play). Игрок I, выбирая L на вершине 4, гарантирует, что вершина 7 не будет достигнута; собственно, это и значит оказаться «вне розыгрыша». Однако при анализе игр в развернутой форме нам следует интересоваться тем, что происходит вне розыгрыша, поскольку знание об этом оказывает решающее влияние на то, что происходит с самим розыгрышем.
Например, именно тот факт, что Игрок I сыграл бы R на вершине 7, вынуждает Игрока II играть L на вершине 6, и именно поэтому Игрок I не выберет R на вершине 4. Игнорируя результаты вне траектории розыгрыша, мы лишаем себя значимой для решений игры информации, как это делает простой поиск нэшевских равновесий. Обратите внимание на то, что повод сомневаться в том, что РН является полностью удовлетворительной концепцией равновесия само по себе, не имеет ничего общего с представлениями о рациональности, как в случае уточнения концепций, рассмотренных в разделе 2.5.
Теперь применим алгоритм Цермело к развернутой форме нашего примера. Начнем, опять же, с последней подыгры, начинающейся с вершины 7. Это ход игрока I, и он выберет R, потому что предпочитает выигрыш пяти очков выигрышу четырех, которые он получит, сыграв L. Поэтому мы назначаем выигрыш (5, -1) вершине 7. Таким образом, на вершине 6 игрок II должен выбирать между (-1, 0) и (5, -1). Он выбирает L. На вершине 5 игрок II выбирает R (0,5). На вершине 4 игрок I, таким образом, выбирает между (0, 5) и (-1, 0), и поэтому он играет L. Заметим, что, как и в игре заключенных, в терминальной вершине результатом является (4, 5) на вершине 7 — что по Парето предпочтительнее РН. Но, опять же, динамика игры препятствует достижению этого результата.
Тот факт, что алгоритм Цермело выбирает вектор (LR, RL) в качестве уникального решения игры, показывает, что он дает нечто иное, чем просто РН. Фактически, он генерирует идеальное равновесие подыгры (ИРП) для данной игры. Это дает результат, который обеспечивает достижение РН не только для всей игры, но также и для каждой подыгры. Это концепция решения убедительна, потому что, опять же в отличие от рафинирований из раздела 2.5, она не требует «дополнительной» рациональности от агентов, в том смысле что не ожидает, что они будут руководствоваться философскими представлениями о «том, что целесообразно». Однако она предполагает, что игроки не только знают все, что стратегически важно них в этой ситуации, но и используют всю эту информацию. В спорах об основах экономики это часто называют аспектом рациональности, как во фразе «рациональные ожидания». Но, как отмечалось ранее, следует соблюдать осторожность, дабы не спутать общую нормативную идею рациональности с вычислительной мощностью и обладанием запасом времени и энергии, позволяющим использовать ее наиболее полно.
Агент, разыгрывающий совершенную стратегию в подыгре, просто выбирает на каждой вершине путь, который приносит ему самый высокий выигрыш в подыгре, исходящей от этой вершины. ИРП предсказывает результат игры только в случае, если при решении игры игроки предвидят, что все они поступят таким образом.
Главная ценность поиска ИРП для игр расширенной формы в том, что он позволяет определить структурные ограничения социальной оптимизации. В нашем текущем примере игроку I было бы лучше, а игроку II не хуже, оказаться в левой вершине, исходящей из вершины 7, чем на результате ИРП. Однако экономическая рациональность игрока I и осведомленность игрока II об этом блокируют социально эффективный исход. Если наши игроки хотят здесь добиться более социально эффективного результата (4,5), они должны поменять свои установки, дабы изменить структуру игры.
Перестройка институциональных и информационных структур для повышения вероятности эффективных результатов в играх, в которые действительно играют агенты (то есть индивидуумы, корпорации, правительства и т.д.), называется дизайном механизмов и является одной из ведущих областей прикладного использования теории игр. Основные техники дизайна механизмов разбираются в книге Гурвича и Рейтера (Hurwicz and Reiter 2006), первый из которых за свою новаторскую работу в этой области получил Нобелевскую премию.
Интерпретация выигрышей: мораль и эффективность в играх
Многие читатели, но особенно философы, могут задуматься, почему для нашего последнего примера нужен дизайн механизмов, если игроки не являются патологическими социопатами. Разумеется, они могли бы просто увидеть, что результат (4,5) в социальном и моральном отношении превосходит все остальные; и поскольку здесь также принимается за само собой разумеющимся, что они могут проследить последовательность действий, которая приводит к этому эффективному результату, то какой же теоретик игр посмеет заявить, что этот результат недостижим без изменения игры?
Это возражение, что взывает к особой концепции рациональности, на которой настаивал Иммануил Кант, демонстрирует, что многие философы понимают под «рациональностью» нечто большее, чем теоретики игр. Эта тема активно и полемически исследуется Бинмором (Binmore 1994, 1998).
Вся эта сложная философская полемика относительно рациональности иногда порождает заблуждения ввиду неверного истолкования слова «полезность» в непсихологической теории игр.
Чтобы устранить эту ошибку, давайте вновь рассмотрим дилемму заключенного.
Мы видели, что в уникальном нэшевском равновесии ДЗ оба игрока получают меньшую полезность, чем они могли бы получить от сотрудничества. Это может сильно удивить вас, даже если вы не являетесь кантианцем (как это удивило многих комментаторов). Разумеется, можете подумать вы, что это просто итог сочетания эгоизма и паранойи игроков. Они, во-первых, не учитывают общественное благо, а после еще сильнее усугубляют свое положение, будучи слишком ненадежными для соблюдения соглашений.
Подобные соображения широко распространены и крайне запутаны. Чтобы лишить их влияния, давайте для начала введем некую терминологию для обсуждения результатов. Экономисты, изучающие благосостояние, обыкновенно измеряют общественное благо в терминах Парето-оптимальности, или оптимальности по Парето.
Распределение полезности β называется Парето-превосходящим по сравнению с распределением δ в случае, если из состояния δ возможно перераспределить полезность в β так, что по крайней мере один игрок выигрывает больше в β, чем в δ, и никто при этом не выигрывает меньше. Неспособность перейти от неоптимального по Парето к парето-оптимальному распределению неэффективна, поскольку сама возможность β показывает, что в δ некоторая доля полезности теряется впустую. Так вот, результат (3,3), который соответствует сотрудничеству в нашей модели ДЗ, явно превосходит по Парето взаимное предательство; на (3,3) обоим игрокам лучше, чем на (2,2). Поэтому верно, что ДЗ приводит к неэффективным результатам. Это справедливо и для нашего примера в разделе 2.6.
Однако неэффективность не должна ассоциироваться с безнравственностью. Функция полезности для игрока должна отражать все, что волнует игрока — а это может быть что угодно. Мы описали наших заключенных и их ситуацию так, будто они действительно заботятся только об относительной продолжительности сроков своего заключения, но это несущественно. Что делает игру примером ДЗ — так это ее структура выигрышей и только она. Фигурально выражаясь, «заключенными» игроками могут быть две матери Терезы, каждая из которых беспокоится не о себе, а о голодающих детях. Примем, что одна мать — собственно, Тереза — хочет накормить детей Калькутты, в то время как мать Хуанита хочет накормить детей Боготы. И предположим, что международный благотворительный фонд пожертвует максимальную сумму, если обе святых выберут один и тот же город; даст вторую по величине сумму, если они выберут города друг друга (т.е. Тереза — Боготу, а Хуанита — Калькутту) и самую низкую сумму, если каждая из них выберет свой собственный город. Наши святые здесь находятся в ситуации ДЗ, хотя они едва ли эгоистичны или не заботятся об общественном благе.
А теперь вернемся к нашим заключенным и предположим, что, вопреки нашим ожиданиям, они ценят благополучие друг друга так же, как и свое собственное. В этом случае это должно сказываться на их функциях полезности и, следовательно, на их выигрышах. Если их структуры платежей изменятся таким образом, что, например, им будет настолько плохо от своей причастности к неэффективности, что они предпочтут лишние годы заключения стыду, они больше не будут находиться в ДЗ. Но все это демонстрирует? То, что не всякая возможная ситуация — дилемма заключенного; это не показывает, что эгоизм входит в число предпосылок теории игр. Логика ситуации заключенных, а не психология удерживает их в капкане конечной неэффективности, и если они действительно оказались в нем, то из него нет иного выхода (если пренебречь дополнительными трудностями, которые будут обсуждаться ниже). Агентам, которые желают избегать неэффективных результатов, следует просто не допускать возникновения некоторых игр; сторонник кантовской рациональности на самом деле предлагает игрокам попытаться выйти из сложившейся игры, превратившись в агентов другого типа.
Короче, из этого следует, что игра частично определяется выигрышами, которые назначаются игрокам. В любой ситуации приписывания этих выигрышей должны опираться на достоверные эмпирические данные. Если предлагаемое решение подразумевает скрытое изменение выигрышей, то это «решение» на самом деле скрыто подменяет тему и отклоняется от стандартов моделирования.
«Дрожащая рука» и равновесие квантильных откликов (QRE)
Сказанное выше открывает путь к философскому затруднению, над которым работают те, кого все еще интересуют логические основания теории игр. Этот вопрос можно поставить по отношению к любому примеру, но мы обратимся к изящному примеру Кристины Биккьери (Bicchieri 1993). Рассмотрим следующую игру:
Равновесный по Нэшу итог один — он находится в крайней левой вершине, отходящей от вершины 8. Чтобы увидеть это, снова воспользуемся обратной индукцией. В вершине 10 игрок I сыграет L дабы получить 3, оставляя игроку II выигрыш в 1. Игрок II может добиться большего, сыграв L в вершине 9 и оставив I выигрыш в 0. Чтобы избежать этого, I сыграет L в вершине 8; это он и делает — так что игра заканчивается без передачи хода игроку II. Биккьери (наряду с другими авторами, включая Binmore 1987, Pettit and Sugden 1989) ставит следующую проблему. Игрок I играет L в вершине 8, потому что ему известно, что Игрок II экономически рационален, и потому в вершине 9 сыграет L, потому что Игрок II знает, что Игрок I экономически рационален и в вершине 10 сыграет L. Но теперь перед нами возникает следующий парадокс: Игрок I должен предполагать, что Игрок II в вершине 9 предскажет экономически рациональный ход Игрока I на вершине 10, несмотря на то, что он достиг вершины 9 — на которой он мог оказаться только в том случае, если Игрок I не является экономически рациональным! Если Игрок I не является экономически рациональным, Игрок II не может обосновать прогноз, что Игрок I не будет играть R в вершине 10, и в потому не очевидно, что Игрок II не должен играть R в вершине 9; и если Игрок II сыграет R в 9, то Игроку I гарантируется лучший выигрыш, если он сыграет L в вершине 8. Оба игрока используют обратную индукцию для решения игры; обратная индукция требует, чтобы Игрок I знал, что игрок II знает, что игрок I является экономически рациональным; но игрок II может решить игру только с помощью аргумента обратной индукции, который предполагает, что Игрок I ведет себя экономически рационально. Это парадокс обратной индукции.
Стандартный способ обойти этот парадокс, описанный в исследовательской литературе, — обратиться к идее «дрожащей руки», предложенной Зельтеном (Selten 1975). Она состоит в том, что решение и его последствия могут быть «разнесены» с некоторой ненулевой вероятностью, сколь бы малой она ни была. То есть игрок может желать предпринять некое действие, но затем ошибиться в розыгрыше и направить игру по другому пути. Если есть даже отдаленная возможность, что игрок может совершить ошибку, — его «рука может дрогнуть», — то игрок, используя аргумент от обратной индукции, не впадает в противоречие, предполагая, что другой игрок изберет путь, который экономически рациональный игрок выбрать не может. В нашем примере Игрок II мог размышлять о том, что делать в вершине 9, исходя из предположения, что Игрок I выбрал L в вершине 8, но затем пошел по другому пути.
Гинтис (Gintis 2009) указывает, что кажущийся парадокс возникает не только из-за нашего предположения об экономической рациональности обоих игроков. Он также опирается на предпосылку, что каждый игрок знает и руководствуется в своих размышлениях тем, что другой игрок экономически рационален. Из-за этой предпосылки догадки каждого игрока о том, что происходит вне пути к равновесию игры, становятся противоречивы. У игрока есть основания учитывать неравновесные возможности, если: а) он считает, что его противник экономически рационален, но его рука может дрогнуть; б) допускает ненулевую вероятность того, что противник не является экономически рациональным; в) сомневается в том, что он верно понимает функцию полезности противника.
Как подчеркивает Гинтис, в общем виде эта проблема при решении игр в развернутой форме по алгоритму Цермело для игр с ИРП такова: у игрока нет причин разыгрывать даже равновесную по Нэшу стратегию, если он не ожидает от других игроков, что они также будут придерживаться нэшевской стратегии. Мы вернемся к этому вопросу ниже, в разделе 7.
Парадокс обратной индукции, подобно затруднениям, связанным с рафинированием равновесия, проблематичен главным образом для тех, кто рассматривает теорию игр как часть нормативной теории рациональности (а именно, как часть более широкой теории стратегической рациональности).
Мнения специалистов в области непсихологической теории игр об «иррациональном» поведении и осторожности, которую она провоцирует, могут разниться.
Некоторые указывают на эмпирический факт, что реальные агенты, в том числе люди, должны осваивать равновесные стратегии игр, в которые они играют, по крайней мере, когда игры хоть сколько-нибудь сложны. Исследования показывают, что даже столь простые игры, как дилемма заключенного, требуют обучения (Ledyard 1995, Sally 1995, Camerer 2003).
Сказать, что люди должны изучать равновесные стратегии, значит сказать, что нам следует быть несколько более искушенными, чем было указано ранее, в построении функций полезности из поведения при применении теории выявленных предпочтений (RPT).
Вместо построения функции полезности на основе отдельных эпизодов, нам следует делать это на основе наблюдений за регулярными паттернами стабилизировавшегося поведения, т.е. после того, как субъекты уже изучили игру.
И вновь, дилемма заключенного здесь будет нам хорошим примером. В повседневной жизни люди редко сталкиваются с однократными ДЗ, им куда чаще приходится иметь дело с повторяющимися дилеммами, участники которых не случайные друг другу люди. В результате, когда экспериментаторы заставляют их играть однократную ДЗ, испытуемые обычно начинают играть так, как если бы эта игра была одним раундом повторяющейся ДЗ. Повторяющаяся ДЗ имеет множество равновесий Нэша, которые предполагают сотрудничество, а не отступничество.
Таким образом, экспериментальные субъекты, как правило, вначале сотрудничают, но после нескольких раундов научаются предавать. Экспериментатор не может сделать вывод, что он успешно воспроизводит однократную ДЗ в своем эксперименте, пока не убедится в стабилизации такого поведения.
Если игроки понимают, что другим игрокам нужно сначала разобраться в структуре игры и ее равновесиях опытным путем, это дает им основание учитывать также и то, что происходит вне равновесных путей решения игры в развернутой форме. Конечно, если игрок опасается, что другие игроки не изучили равновесие, это вполне может лишить его стимула разыгрывать стратегию равновесия.
Это порождает множество серьезных проблем социального обучения (Fudenberg and Levine 1998). Как несведущим игрокам научиться разыгрывать равновесие, если искушенные игроки им это не показывают, поскольку у искушенных игроков нет мотивации играть в стратегии равновесия, пока неискушенные этому не научились? Ключевой ответ для прикладного применения теории игр к взаимодействию между людьми гласит: молодежь социализируется, пока растет в институциональных сетях, у которых есть культурные нормы. Большинство сложных игр, в которые играют люди, разыгрывают те, кто уже был социализирован, то есть освоил игровые структуры и равновесия (Ross 2008a). Новички вынуждены в этом случае лишь копировать тех, чья игра кажется ожидаемой и понятной для остальных. Институты и нормы насыщены напоминаниями, типа нравоучений и легко запоминающихся «правил большого пальца», которые помогают людям помнить о том, чем они вообще занимаются (Clark 1997).
Как отмечалось в разделе 2.7, если наблюдаемое поведение не стабилизируется вокруг равновесных состояний игры, и нет никаких свидетельств тому, что обучение все еще продолжается, аналитику следует сделать вывод, что он неправильно смоделировал изучаемую им ситуацию. Вероятно, он либо неправильно задал функции полезности игроков, либо доступные игрокам стратегии, либо доступную для них информацию. Учитывая сложность многих изучаемых социологами ситуаций, не следует удивляться тому, что модели часто оказываются неправильными. Теоретики, занимающиеся прикладными играми, должны тратить много сил на обучения, точно так же, как и их испытуемые.
Таким образом, парадокс обратной индукции — лишь видимость. Если игроки не имеют опыта равновесной игры друг с другом в прошлом, даже если они экономически рациональны и уверены в рациональности партнера, мы должны понимать, что они допускают, что другие игроки могут не вполне понимать структуры игры. Это объясняет, почему люди, даже если они являются экономически рациональными агентами, могут зачастую — или даже обыкновенно — играть так, будто они верят в «дрогнувшую руку».
Изучение равновесий может принимать различные формы для разных агентов, а также для игр различного уровня сложности и риска. Включение этого фактора в теоретико-игровые модели взаимодействий, соответственно, открывает перед нами огромное множество новых технических решений. Наиболее развитая общая теория изложена Фуденбергом и Левиным (Fudenberg and Levine 1998).
Выше мы уже упоминали, что люди обыкновенно играют так, будто они верят в «дрожание рук». Причина этого заключается в том, что при взаимодействии людей мир не дает им подсказок, которые бы поясняли им структуру игры, в которую они играют. Они вынуждены строить и проверять гипотезы относительно структуры игры, опираясь на социальный контекст. Иногда контекст задают институциональные правила. Например, когда человек входит в магазин и видит ценник на что-то, что он хотел бы иметь, он знает, не нуждаясь в догадках или обучении чему-либо, что он участвует в простой игре «либо да, либо нет». А оказавшись на рынке, например, он может знать, что может торговаться, и также знает правила для этого.
Учитывая сложные взаимоотношения между теорией обучения и теорией игр (все еще нерешенные), приведенное выше рассуждение может привести к мысли, что теория игр никогда не сможет быть применена к ситуациям с участием новичков. К счастью, это, однако, не так. Маккелви и Палфри в двух своих весьма влиятельных работах середины-конца 1990-х (McKelvey and Palfrey 1995, 1998) разработали концепцию решения равновесия дискретного отклика (QRE), или просто дискретного равновесия. QRE не является рафинированием нэшевского равновесия, в том смысле, что оно не является философски мотивированной попыткой усилить РН с опорой на нормативные стандарты рациональности. Это, скорее, метод расчета равновесных свойств выборов, сделанных игроками, предположения которых о возможных ошибках в выборе других игроков не определены. Таким образом, QRE является стандартным средством в инструментарии экономистов-экспериментаторов, которые пытаются оценить распределение функций полезности в популяциях реальных людей, помещенных в модельные игровые ситуации. Таким образом, QRE нельзя было бы применить на практике до разработки эконометрических пакетов, таких как Stata, позволяющих вычислять QRE по адекватным информативным записям наблюдений за сложными играми. QRE редко используется поведенческими экономистами и почти никогда не используется психологами при анализе лабораторных данных. Вследствие этого многие исследователи из этой группы делают крайне драматичные риторические заявления, «открывая», что реальные люди в экспериментальных играх часто не сходятся на РН. Но хотя РН и представляет собой в некотором смысле минималистскую концепцию решения, поскольку достаточно сильно абстрагируется от информационной структуры, в своей категорической форме одновременно является сильным эмпирическим ожиданием (то есть если ожидается, что игроки будут играть так, как если бы они были уверены, что все остальные игроки также сыграют стратегии РН). Прогнозирование розыгрыша, соответствующего QRE, согласуется — а, точнее, мотивировано — с точкой зрения, согласно которой РН воплощает центральную идею стратегического равновесия. С философской точки зрения отношение между РН и QRE можно описать следующим образом. РН определяет логический принцип, который хорошо подходит для «настройки» нашего мышления и разработки типовых стратегий для моделирования новых классов социальных явлений. Для оценки же реальных эмпирических данных необходимо иметь возможность определить равновесие статистически. QRE представляет собой способ сделать это сообразно логике РН. Эта идея настолько масштабна, что в теории игр она все еще остается малоисследованной. Современные способы истолкования QRE представлены в работе Гори, Холта и Палфри (Goeree, Holt and Palfrey 2016).
Неопределенность, риск и секвенциальное равновесие
Во всех играх, которые мы моделировали до этого момента, участвовали игроки, выбиравшие из чистых стратегий, в которых каждый искал на каждой вершине один оптимальный курс действий, представляющий собой наилучшую реакцию на действия других.
Однако часто полезность для игрока оптимизируется при помощи смешанной стратегии, которая выглядит как выбор одного из возможных действий посредством подбрасывания «нечестной» монетки. (Позже мы увидим, что существует альтернативная интерпретация смешивания, не предполагающая рандомизации в определенном информационном множестве, но мы начнем здесь с интерпретации подбрасывания монетки, а затем продолжим в части 3.1).
Если ни одна чистая стратегия не максимизирует полезность игрока по отношению ко всем стратегиям противника, используется смешивание. Примером подобного является игра с преодолением реки, описанная в разделе 1. Как мы видели, задача в этой игре состоит в том, что если в ходе размышления беглец выбирает некоторый мост в качестве оптимального, то следует допустить, что его преследователь сможет воспроизвести тот же самый ход мысли. Беглец может уйти от погони только в том случае, если охотник не может однозначно предсказать, по какому мосту будет переправляться беглец. Симметрия логического рассуждения упирается в то, что беглец сможет удивить преследователя только в том случае, если он окажется способен удивить себя.
Давайте забудем на мгновение про камнепады и кобр и представим, что все мосты безопасны в равной степени. Предположим также, что беглец не имеет особых сведений о своем преследователе, которые позволили ему отважиться на то, чтобы построить специфическое распределение вероятностей для доступных стратегий преследователя. В этом случае лучшим вариантом для беглеца будет бросок трехгранной кости, в которой каждая сторона представляет один из мостов (или шестигранного кубика, на котором каждый мост представлен двумя гранями). Он также должен предварительно взять на себя обязательство использовать мост, выбранный с помощью данного средства рандомизации. Это закрепляет шансы его выживания независимо от того, как поступит преследователь; но поскольку у преследователя нет оснований предпочесть какую-либо доступную ему — чистую или смешанную — стратегию, и поскольку мы в любом случае предполагаем, что его эпистемическая ситуация симметрична ситуации беглеца, мы можем предположить, что преследователь также сделает свой выбор на основании броска трехгранной кости. Теперь вероятность успеха для беглеца составляет 2/3, а вероятность преследователя поймать его — 1/3. Ни беглец, ни преследователь не могут улучшить свои шансы, учтя рандомизирующее смешение другого, поэтому две стратегии рандомизации находятся в равновесии Нэша. Обратите внимание на то, что если один игрок рандомизирует, то другой преуспеет одинаково при любом смешении вероятностей для мостов, поэтому комбинаций наилучших ответов бесконечно много. Тем не менее каждый игрок вынужден беспокоиться о том, что любая неслучайная стратегия будет увязана с некоторым фактором, который другой игрок может обнаружить и использовать. Поскольку любую неслучайную стратегию можно таким образом обыграть при помощи другой неслучайной стратегии, то в игре с нулевой суммой, к каковой относится наш пример, равновесным по Нэшу будет только вектор рандомизированных стратегий.
Теперь повторно введем параметрические факторы, т.е. падающие камни на мосту №2 и кобр на мосту №3. Опять же, предположим, что беглец точно переправится по мосту №1 успешно, сделает это 90-процентным шансом на успех по мосту №2 и 80-процентным — по мосту №3. Мы можем решить эту игру, если сделаем определенные предположения о функциях полезности двух игроков. Предположим, что игрок 1, беглец, заботится только о жизни или смерти (предпочитая жизнь смерти), в то время как преследователь просто хочет доложить, что беглец мертв, и предпочитает это докладу о том, что беглец ушел. (Иными словами, ни один из игроков не заботится о том, как именно выживет или погибнет беглец). Предположим также, что ни один из игроков не получает ни пользы, ни вреда от того, что решается рисковать. В этом случае беглец просто берет свою первоначальную формулу рандомизации и взвешивает ее в соответствии с различными уровнями параметрической опасности на трех мостах. Каждый мост следует рассматривать как лотерею возможных результатов беглеца, в которых каждая лотерея имеет иную ожидаемую выгоду с точки зрения позиций в своей функции полезности.
Рассмотрим ситуацию с точки зрения преследователя. Выбирая сочетание вероятностей для мостов, он будет использовать свою равновесную по Нэшу стратегию, так что беглецу при выборе между чистыми стратегиями позиция оппонента безразлична. Мост с камнепадами для него в 1,1 раза опаснее, чем безопасный мост. Поэтому он будет безразличным к выбору между ними, если вероятность встретить на безопасном мосту охотника будет в 1,1 раза выше, чем на мосту под осыпающейся скалой. Мост с кобрами в 1,2 раза опаснее для беглеца, чем безопасный мост. Поэтому он будет безразличен к выбору между этими мостами, если вероятность встретить преследователя на безопасном мосту в 1,2 раза выше, чем на мосту с кобрами. Предположим, мы используем параметрическую выживаемость беглеца на каждом мосту s1, s2 и s3. Преследователь снижает чистую выживаемость беглеца для любой пары мостов тем, что может ожидать его на каждом из них — это выражается через p1 и p2, так, что
s1 (1 − p1) = s2 (1 − p2)
Поскольку p1 + p2 = 1, мы можем переписать это так:
s1 × p2 = s2 × p1
так что
p1/s1 = p2/s2.
Таким образом, преследователь находит свою равновесную по Нэшу стратегию, решая следующую систему одновременных уравнений:
1 (1 − p1) = 0,9 (1 − p2)
= 0,8 (1 − p3)
p1 + p2 + p3 = 1.
Тогда
p1 = 49/121
p2 = 41/121
p3 = 31/121
Теперь введем f1, f2, f3 для обозначения вероятностей, с которыми беглец выбирает каждый соответствующий мост. Тогда беглец находит свою стратегию РН, решая
s1 × f1 = s2 × f2
= s3 × f3
так что
1 × f1 = 0.9 × f2
= 0.8 × f3
одновременно с
f1 + f2 + f3 = 1.
Тогда
f1 = 36/121
f2 = 40/121
f3 = 45/121
Эти два набора РН-вероятностей сообщают каждому игроку, как задать вес игрального кубика перед броском. Обратите внимание — возможно, к своему удивлению, — что беглец, хотя и не получает по условиям нашей игры удовольствия от азартных игр, выбирает более рискованные мосты с большей вероятностью. Это единственный способ сделать преследователя безразличным к тому, на какой мост ему делать ставку, что, в свою очередь, максимизирует вероятность счастливого исхода для беглеца.
Мы смогли решить эту игру напрямую, потому что мы задаем функции полезности так, чтобы сделать ее игрой с нулевой суммой или строго конкурентной. Это значит, что любой прирост ожидаемой полезности для одного игрока представляет собой точно симметричную потерю для другого. Однако часто это условие может не выполняться. Предположим теперь, что функции полезности более сложны. Преследователь больше всего предпочитает результат, при котором он пристрелит беглеца, тому, где беглец погибнет самостоятельно — под камнепадом или от укуса кобры; а самостоятельную смерть беглеца он предпочитает удачному побегу. Беглец же предпочитает быструю смерть от выстрела долгим мукам под камнепадом или ужасу встречи с коброй. А больше всего, конечно, он предпочитает спастись. Предположим, что беглец намного больше заботится о своем выживании, чем тем, каким именно способом ему погибнуть. Мы не можем решить эту игру, как и прежде, только с опорой на порядковые функции полезности игроков, поскольку интенсивность их относительных предпочтений теперь будет соответствовать их стратегиям.
До 1947 года (работы фон Неймана и Моргенштерна) подобные ситуации по своей сути были непонятны аналитикам, потому что полезность не отражает такую скрытую психологическую переменную, как удовольствие.
Как мы уже говорили в разделе 2.1, полезность является лишь мерой относительных поведенческих склонностей, с учетом когда нам точно известны отношения между предпочтениями и выборами. Поэтому нет смысла сравнивать кардинальные — т.е. чувствительные к интенсивности — предпочтения наших игроков, поскольку не существует независимой, для всех одинаковой линейки, которую бы мы могли использовать. Как же тогда моделировать игры, в которых важна кардинальная информация?
В конце концов, для моделирования игр требуется, чтобы все полезности для игроков учитывались одновременно.
Важнейшей результатом работы фон Неймана и Моргенштерна было решение этой проблемы. Здесь мы кратко изложим предложенную ими оригинальную технику получения кардинальных функций полезности из порядковых. Следует подчеркнуть, что изложенное ниже является лишь наброском, необходимым для того, чтобы демистифицировать кардинальную полезность для вас как для того, кто заинтересован в философских основаниях теории игр и круге проблем, к которым она может быть применена. Составление руководства, по которому вы могли бы строить кардинальные функций самостоятельно, потребовало бы многих страниц. Такие руководства доступны во многих учебниках.
Предположим, что мы теперь назначаем следующую порядковую функцию полезности беглецу, пересекающему реку:
Спасение ≫ 4
Смерть от выстрела ≫ 3
Смерть от камнепада ≫ 2
Смерть от укуса змеи ≫ 1
Мы полагаем, что он предпочитает свободу смерти в большей степени, чем любую из форм смерти другой. Это должно отражаться на том, какое поведение он предпочтет, следующим образом. В игре с переправой его готовность рискнуть, дабы усилить относительную вероятность побега по сравнению с вероятностью быть застреленным, будет выше, чем в ситуации, когда он оценивает риски попытки усилить относительную вероятность быть застреленным по сравнению с вероятностью умереть от змеиного укуса. Эта логика — важнейший элемент решения проблемы кардинализации, предложенного фон Нейманом и Моргенштерном.
Предположим, что мы попросили беглеца выбрать из доступного набора результатов лучший и худший. «Лучший» и «худший» определяются при помощи ожидаемых выигрышей, как показано на примере нашей игры с нулевой суммой: игрок максимизирует свой ожидаемый выигрыш, если при выборе лотерей, содержащих только два возможных приза, его выбор всегда устремлён к максимизации вероятности наилучшего результата — назовем его W — и минимизации вероятности наихудшего — назовем его L.
Теперь расширим множество возможных призов, чтобы оно включало призы, которые агент оценивает как промежуточные между W и L.
Мы обнаруживаем, что для набора результатов, содержащих такие призы, имеется такая лотерея, что наш агент не видит отличий между ней и лотереей, включающей только W и L.
В нашем примере это лотерея, включающая в себя смерть от пули и смерть от камня. Назовем эту лотерею T. Мы определим q = u(T) как функцию полезности от результатов на ряд действительных чисел (в отличие от порядкового), так что если q — ожидаемый выигрыш в T, то агенты не видят различий между выигрышем T и выигрышем лотереи T*, в которой W встречается с вероятностью u(T), а L встречается с вероятностью 1–u(T).
Если поведение агентов соблюдает принцип сокращения сложных лотерей (reduction of compound lotteries, ROCL) — т.е. не получает или не теряет в полезности от рассмотрения более сложных лотерей, — то набор отображений результатов в T в uT* дает функцию полезности фон Неймана-Моргенштерна (vNMuf) с кардинальной структурой по всем результатам в T.
Что именно мы здесь сделали? Мы предоставили нашему агенту выбор из лотерей, вместо того чтобы дать ему выбирать результаты, и увидели, какому именно дополнительному риску смерти он готов подвергнуться, чтобы изменить свои шансы на одну смерть по отношению к другой. Отметим, что это кардинализирует структуру предпочтений агента только по отношению к специфичным для этого агента точкам сравнения W и L; процедура никак не сравнивает экстра-порядковые предпочтения между агентами, что позволяет ясно показать, что построение функции vNMuf не вводит никакого потенциально объективного психологическего элемента. Более того, два агента в рамках одной игры или один агент в различных обстоятельствах могут по-разному относиться к риску. Возможно, в игре с переправой преследователь, чья жизнь не поставлена на карту, будет азартен, в то время как беглец осторожен. Однако при анализе этой игры мы не должны сравнивать кардинальную полезность для преследователя с кардинальной полезностью для беглеца. Оба агента, в конце концов, могут достичь своих равновесных по Нэшу стратегий, если смогут оценить вероятности, которые каждая сторона присваивает действиям другой. Это значит, что каждый агент должен знать обе функции vNMuf; но ни один из них не нуждается в том, чтобы сравнить ценность результатов, из которых они выбирают.
Теперь мы можем заполнить остальную часть матрицы для игры с переправой, которую мы нарисовали в разделе 2. Если оба игрока не питают страсти к риску и их выявленные предпочтения учитывают ROCL, то у нас имеется достаточно информации, чтобы распределить ожидаемую полезность, выражая ее путем умножения исходных выигрышей на соответствующие вероятности, как результаты в матрице. Предположим, что охотник ждет на мосту со кобрами с вероятностью x, а на скалистом мосту с вероятностью y. Поскольку сумма его вероятностей для трех мостов должна быть равна 1, это означает, что он должен ждать на безопасном мосту с вероятностью 1 — (x + y). Назначая выигрыш беглецу за смерть 0, и 1, если он уйдет от погони, а выигрыши преследователя противоположным образом, получаем полную матрицу следующего вида:
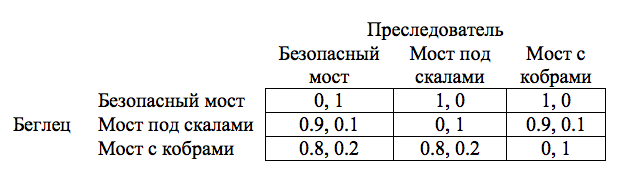
Теперь мы можем непосредственно по матрице узнать об игре следующие факты: ни одна пара чистых стратегий не является парой лучших ответов друг на друга. Таким образом, единственное РН в игре требует, чтобы по меньшей мере один игрок использовал смешанную стратегию.
Убеждения и субъективные вероятности
Во всех наших примерах до этого момента мы предполагали, что убеждения игроков относительно вероятностей в лотереях соответствуют объективным вероятностям. Но в реальных ситуациях интерактивного выбора агенты часто вынуждены полагаться на свои субъективные оценки или восприятие вероятностей. Автор одной из величайших работа по поведенческим и социальным наукам XX века Леонард Сэвидж показал (Savage 1954), как можно включить субъективные вероятности и их отношения к предпочтениям в теорию ожидаемой полезности фон Неймана-Моргенштерна. Действительно, с достижением Сэвиджа теория ожидаемой полезности (EUT) была, наконец, полностью формализована. Затем, чуть более десятилетия спустя, Джон Харсаньи (Harsanyi 1967) показал, как решать игры с использованием максимизаторов ожидаемой полезности Сэвиджа. Принято считать, что с этого момента теория игр наконец созрела для того, чтобы стать прикладным инструментом поведенческих и социальных наук, и была признана как таковая, когда Харсаньи вместе с Нэшем и Зельтеном в 1994 году стали первыми теоретиками игр, получившими Нобелевскую премию.
Как мы уже видели, — рассматривая необходимость того, чтобы играющие в игры люди освоили равновесие «дрожащей руки» и QRE, — при моделировании стратегических взаимодействий людей, мы должны допускать тот факт, что люди, как правило, не уверены в том, что их модели других игроков верны. Эта неуверенность проявляется в том, как они выбирают стратегии. Более того, некоторые действия могут быть предприняты специально лишь для того, чтобы проверить точность предположений игрока относительно других игроков. Расширенная Харсаньи теория игр включает в себя эти важнейшие элементы.
Рассмотрим игру с неполной информацией на трех игроков, известную как «лошадь Зельтена» (получившую такое имя в честь ее изобретателя Рейнхарда Зельтена, нобелевского лауреата по экономике, — и из-за формы ее дерева; взято из Kreps 1990: 426):
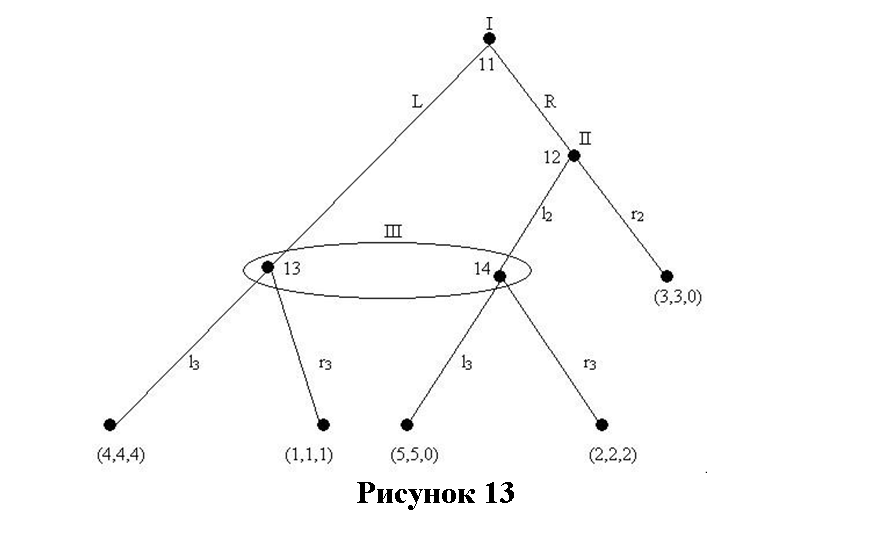
У этой игры есть четыре равновесия по Нэшу: (L, l2, l3), (L, r2, l3), (R, r2, l3) и (R, r2, r3). Рассмотрим четвертое. Оно возникает, когда игрок I играет R, а игрок II играет r2; все информационное множество игрока III оказывается вне пути игры, и для результата действия игрока III не имеют значения. Однако игрок I не играл бы R, если бы игрок III видел разницу между позицией в вершине 13 и позицией в вершине 14. Структура игры благоприятствует усилиям игрока I предоставить игроку III информацию, которая вскрыла бы его закрытое информационное множество. Игроку III следует поверить этим данным, поскольку структура игры показывает, что у Игрока I есть стимул говорить правду. Тогда решением игры будет ИРП для игры с (теперь) совершенной информацией: (L, r2, l3).
Теоретики, рассматривающие теорию игр как часть нормативной теории общей рациональности, например, большинство философов, а также сторонники программы уточнения понятия равновесия среди экономистов, разработали стратегию, которая бы определяла это решение на общих принципах. Обратите внимание: игрок III в «лошади Зельтена» может задуматься, выбирая стратегию: «Если я получил ход, была ли вершина моего действия достигнута из вершины 11 или вершины 12?» Иными словами, каковы условные вероятности того, что Игрок III находится в вершине 13 или 14, учитывая, что ход перешел к нему? Теперь, если Игрок III размышляет об условных вероятностях, тогда игрок I и игрок II, выбирая свои стратегии, думают об убеждениях Игрока III относительно этих условных вероятностей. В этом случае Игрок I должен строить догадки об убеждениях Игрока II по поводу убеждений Игрока III и убеждениях Игрока III по поводу убеждений игрока II, и т.д. Эти убеждения здесь не просто, как прежде, стратегические, поскольку они касаются не только того, что будут делать игроки при данных наборах выигрышей и в таких игровых структурах, но и о том, какого понимания условной вероятности они должны ожидать от других игроков.
Каких убеждений относительно условной вероятности игрокам разумно ожидать друг от друга? Если бы мы последовали за Сэвиджем (Savage 1954), мы бы предположили в качестве нормативного принципа, что они должны рассуждать сами и ожидать от других рассуждений в соответствии с правилом Байеса. Это подскажет им, как вычислить вероятность события F при информации E (обозначается «pr (F / E)»):
pr(F/E) = [pr(E/F) × pr(F)] / pr(E)
Если предположить, что убеждения игроков всегда согласуются с этим равенством, то мы можем определить последовательное равновесие (sequential equilibrium). Оно состоит из двух частей: (1) профиля стратегии § для каждого игрока, как и раньше, и (2) системы убеждений μ для каждого игрока. μ присваивает каждому информационному множеству h распределение вероятностей по вершинам в h с интерпретацией, что это убеждения игрока i(h) о том, где в его информационном множестве он находится, при условии, что информационное множество h достигнуто. Тогда последовательное равновесие является совокупностью профиля стратегий § и системы убеждений μ, согласующейся с правилом Байеса таким образом, что, начиная с любого информационного множества h на дереве, игрок i(h) играет в дальнейшем оптимально, учитывая, что, по его мнению, то, что происходило ранее, дано в μ(h), а то, что будет происходить при последующих ходах, дано посредством §.
Применим эту концепцию решения к игре «лошадь Зельтена». Вновь рассмотрим РН (R, r2, r3). Предположим, что игрок III назначает pr(1) своему убеждению в том, что если он получит ход, то он находится в вершине 13. Тогда игрок I, учитывая непротиворечивое μ(I), должен полагать, что игрок III будет играть l3, и в этом случае его единственная стратегия ПР — это L. Поэтому, хотя (R, r2, l3) и является РН, это не ПР.
Использование требования непротиворечивости в этом примере несколько тривиально, поэтому рассмотрим теперь второй случай (также взятый из Kreps 1990: 429):
Предположим, что игрок I играет L, игрок II играет l2, а игрок III играет l3. Предположим также, что μ(II) присваивает pr(0,3) вершине 16. В этом случае l2 не является стратегией ПР для игрока II, так как l2 приносит ожидаемый выигрыш 0,3(4) + 0,7(2) = 2,6, а r2 — ожидаемый выигрыш 3,1. Обратите внимание, что если мы повозимся со стратегическим профилем игрока III, оставив все остальное неизменным, l2 может стать стратегией ПР для игрока II. Если §(III) приводит к розыгрышу l3 с pr(0,5) и r3 с pr(0,5), то если игрок II сыграет r2, его ожидаемый выигрыш будет уже 2,2, поэтому (Ll2l3) будет последовательным равновесием. Теперь представим, что мы откатили μ(III) обратно, но изменили μ(II) так, чтобы игрок II считал, что условная вероятность находиться в вершине 16 больше 0,5; в этом случае l2 вновь не является стратегией ПР.
Идея последовательного равновесия, как мы надеемся, теперь ясна. Мы можем применить его к игре с переправой таким образом, чтобы преследователю не пришлось подбрасывать какие-либо монетки, для чего мы немного модифицируем игру. Предположим теперь, что охотник может дважды поменять мост, пока беглец переправляется, и поймает его, если встретится с ним на выходе с моста. Тогда стратегия ПР для преследователя заключается в том, чтобы разделить время своего пребывания на трех мостах в соответствии с пропорцией, заданной выше уравнением в третьем абзаце раздела 3.
Следует отметить, что, поскольку правило Байеса нельзя применить к событиям с вероятностью 0, его применение к ПР требует, чтобы игроки назначали ненулевые вероятности всем действиям, доступным в развернутой форме. Это требование закрепляется предположением, что все профили стратегии строго смешаны, т.е. что каждое действие в каждом информационном множестве имеет положительную вероятность. Мы увидим, что это просто эквивалентно предположению, что все руки иногда дрожат, или же что никакое ожидание не может быть определенным в достаточной мере. Говорят, что ПР является совершенной дрогнувшей рукой (trembling-hand perfect), если все равновесные стратегии являются наилучшими ответами на строго смешанные стратегии. Мы также не должны удивляться тому, что ни одна слабо доминируемая стратегия не может быть совершенной дрогнувшей рукой, поскольку вероятность дрогнувшей руки является для игроков наиболее убедительной причиной для того, чтобы избегать подобных стратегий.
Как может специалист в области теории непсихологических игр понять концепцию РН, которая является равновесием как действий, так и убеждений? Десятилетия экспериментов показали, что когда люди играют в игры, особенно в те, что в идеале требуют применения правила Байеса при выдвижении предположений об убеждениях других игроков, мы должны ожидать, что стратегические ответы будут в значительной степени гетерогенны. Множество видов информационных каналов обычно связывают разных агентов со структурами стимулов в их среде. Некоторые агенты действительно способны вычислять равновесия с той или иной погрешностью. Другие агенты в результате более или менее упрощенного условного обучения могут удовлетвориться диапазонами ошибок, стохастически дрейфующими вокруг равновесных значений. Третьи могут выбирать шаблонные ответы, копируя поведение других агентов или следуя эмпирическим правилам, встроенным в культурные и институциональные структуры и репрезентирующими коллективную историческую память.
Следует обратить внимание на то, что это весьма специфичная для теории игр проблема, а не простая реитерация более общего тезиса, верного для любой науки о поведении и гласящего, что с точки зрения идеальной теории поведение людей зашумлено.
В данной игре рациональность разыгрывания РН для агента — даже натренированного, осознающего свое положение, обеспеченного вычислительными ресурсами — будет зависит от частоты, с которой, как он ожидает, другие будут поступать аналогичным образом. Ожидая, что другие игроки отклонятся от равновесной по Нэшу игры, он может и сам в итоге отклонится от этой стратегии.
Вместо того, чтобы предсказывать, что игроки будут сами раскрывать строгие стратегии РН, опытный экспериментатор или специалист по моделированию будет ожидать, что между розыгрышем и ожидаемыми затратами на отклонение от РН будет какая-то связь.
Следовательно, оценка наиболее вероятного развития наблюдаемых действий, как правило, указывает на дискретное равновесие как на наилучший вариант по сравнению с любым РН.
Не надо думать, что аналитик, рассматривающий эмпирические данные таким образом, занимается «проверкой гипотезы» о том, что анализируемые агенты «рациональны». Скорее, он предполагает, что они являются агентами, то есть что существует систематическая взаимосвязь между статистическими изменениями паттернов их поведения и некоторыми взвешенными по риску кардинальными рейтингами возможных итоговых состояний. Если агенты являются людьми или институционально структурированными группами людей, которые наблюдают друг за другом и у которых есть стимулы пытаться действовать коллективно, критики будут считать эти гипотезы разумными, или даже прагматически не подлежащими сомнению — даже если они всегда могут быть отброшены с оглядкой на ненулевую вероятность каких-либо внезапных и необычных обстоятельств вроде тех, что иногда рассматривают философы (например, люди окажутся заранее запрограммированными неразумными механическими симулякрами, которые будут раскрыты, только если обстоятельства вызовут в них реакцию, которая не была заложена в их программу). Аналитик будет предполагать, что агенты будут реагировать на стимульные изменения в соответствии с теорией ожидаемой полезности Сэвиджа, особенно если агенты являются фирмами, изучившими ответные действия в условиях нормативно взыскательных условий рыночной конкуренции со многими игроками. Если субъекты аналитика являются отдельными людьми и, в особенности, если они находятся в нестандартной ситуации (относительно их культурного и институционального опыта), аналитик тогда допустит максимально правдоподобную модель, которая допускает, что спектр различных структур обеспечения полезности управляет различными подмножествами его данных. Все это говорится для того, чтобы подчеркнуть: применение теории игр не заставляет ученого эмпирически применять модель, которая, по всей вероятности, будет слишком точной и узкой по своей спецификации, чтобы правдоподобно соответствовать сложным хитросплетениям реального стратегического взаимодействия. Хороший специалист по прикладной теории игр также должен быть хорошо подготовленным эконометристом.
Повторяющиеся игры и координация
До сих пор мы ограничивались лишь однократными играми, то есть играми, в которых стратегические интересы игроков распространяются не далее, чем терминальные вершины их однократного взаимодействия. Однако игры часто проходят с учетом будущих игр, и это может значительно влиять на их результаты и равновесные стратегии. В этом разделе мы будем рассматривать повторяющиеся игры, то есть игры, в которых множества игроков предполагают встретить друг с друга в схожих ситуациях несколько раз. Вначале рассмотрим этот класс игр в ограниченном контексте многократно повторяющихся дилемм заключенного.
Мы видели, что в однократной ДЗ единственным нэшевским равновесием является взаимное отступничество. Однако это может больше не выполняться, если игроки ожидают встречи друг с другом в следующей ДЗ. Представим себе, что четыре фирмы, изготавливающие какие-то штуковины, договариваются поддерживать высокие цены путем совместного ограничения поставок. (То есть формируют картель). Это будет работать только в том случае, если каждая фирма будет сохранять согласованную квоту на производство. Обычно в таких ситуациях верно то, что каждая фирма может максимизировать свою прибыль, если она отклонится от квоты, в то время как другие продолжат соблюдать свои, так как она продаст больше штуковин по завышенной цене, созданной пока еще действующим картелем. В однократном примере все фирмы разделяют этот стимул на отступничество, потому картель незамедлительно распался бы. Однако фирмы в действительности ожидают, что они будут конкурировать друг с другом в течение длительного времени. Потому каждая фирма знает, что если она нарушит картельное соглашение, другие могут наказать ее путем достаточно долгого демпинга для того, чтобы погасить полученную ей краткосрочную выгоду. Разумеется, карающие фирмы будут также понесут убытки в период снижения цен. Но эти потери могут окупиться, если они восстановят картель, который обеспечит максимальные цены на длительный срок.
Одна простая и известная (но, вопреки широко распространенному мифу, необязательно оптимальная) стратегия сохранения кооперации в повторяющихся ДЗ называется «зуб за зуб». Эта стратегия гласит, что каждый игрок должен вести себя следующим образом:
i. Всегда сотрудничать в первом раунде.
ii. Далее действовать также, как и ваш противник в предыдущем раунде.
Если все члены группы будут играть по принципу «зуб за зуб», они никогда не столкнутся с отступничеством.
Поэтому в популяции, где все остальные разыгрывают стратегию «зуб за зуб», «зуб за зуб» является рациональным ответом для каждого игрока; всеобщий розыгрыш «зуб за зуб» есть нэшевское равновесие. Вы можете часто слышать от людей, которые знают немного (но недостаточно) о теории игр, что на этом история заканчивается. Однако это не так.
Есть две сложности.
Во-первых, игроки не должны быть знать о том, когда именно закончится их взаимодействие. Предположим, игроки знают, какой раунд будет последним. В этом раунде можно будет максимизировать полезность отступничеством, они не понесут наказание. Теперь рассмотрим предпоследний раунд. В этом раунде игроки также не подвергаются наказанию за отступничество, так как в любом случае они собираются отступиться в последнем раунде. Так что они отступаются в предпоследнем раунде. Но это означает, что они не рискуют быть наказанными в предпредпоследнем раунде и отступаются и в нем. Мы можем прошагать так по дереву игры до первого раунда. Поскольку в этом раунде сотрудничество не является равновесной по Нэшу стратегией, принцип «зуб за зуб» больше не является стратегией РН в повторяющейся игре, и мы получаем тот же результат — взаимное отступничество, — что и при однократной ДЗ. Поэтому сотрудничество возможно только в повторяющихся ДЗ, где ожидаемое количество повторений не определено. (Разумеется, это относится ко многим играм в реальной жизни). Заметьте, что в этом контексте любой объем неопределенности ожиданий или возможность дрожащей руки будут способствовать сотрудничеству, по крайней мере, некоторое время. Когда люди в экспериментах играют повторяющиеся ДЗ с известным числом ходов, они действительно склонны сотрудничать некоторое время, но потом, с опытом, научаются отступаться чуть раньше.
Теперь введем второе осложнение.
Предположим, что способность игроков отличать отступничество от сотрудничества несовершенна. Рассмотрим наш случай картеля штуковин. Предположим, что игроки наблюдают падение рыночной цены на штуковины. Возможно, это объясняется обманом одного из членов картеля. Или, возможно, это вызвано экзогенным падением спроса. Если руководствующиеся принципом «зуб за зуб» игроки ошибочно примут второе за первое, они нарушат договоренность, тем самым вызвав цепную реакцию взаимных отступничеств, из которой они никогда не смогут выбраться, поскольку каждый игрок будет отвечать на первое обнаруженное отступничество взаимностью, тем самым инициируя дальнейшие, и т.д.
Если игроки знают, что такое недопонимание возможно, у них есть стимул прибегнуть к более сложным стратегиям. В частности, они могут быть готовы иногда рисковать после нарушений и вновь кооперироваться, чтобы проверить свои выводы. Однако, если они слишком благосклонны, тогда другие игроки могут использовать это и отступиться снова. В общем, сложные стратегии сталкиваются с проблемой. Поскольку другим игрокам сложнее их прочесть, использование сложных стратегий увеличивает вероятность взаимного недопонимания. Но недопонимание приводит к развалу кооперативных равновесий в повторяющихся играх. Сложности, связанные с передачей информации, ее оценкой и выводами в повторяющихся ДЗ помогают интуитивно объяснить народную теорему, называемую так, потому что никто не знает наверняка, кто первый ее сформулировал. Согласно этой теореме в повторяющихся ДЗ для любой стратегии S существует такое распределение стратегий других игроков, что вектор S и этих стратегий является РН. Так что ничего особенного в принципе «зуб за зуб» на самом деле нет.
Реальные, сложные, социальные и политические драмы редко бывают реализациями простых игр типа ДЗ. Хардин (Hardin 1995) анализировал два трагически реальных политических кейса: гражданской войны в Югославии 1991–1995 годов и геноцида в Руанде в 1994 году как ДЗ, которые были встроены в координационные игры.
Координационная игра возникает всякий раз, когда полезность двух или более игроков максимизируется тем, что они делают одно и то же, и когда сам по себе факт наличия такой согласованности им важнее, чем содержательная сторона того, что они оба делают. Стандартный пример заимствуется из правил дорожного движения: «все движение левостороннее» и «все движение правостороннее» являются РН, и ни одно из них не эффективнее, чем другое. В играх с «чистой» координацией не помогают даже более точные критерии равновесия.
Например, предположим, что мы требуем от наших игроков размышлять по правилу Байеса (см. раздел 3 выше).
В этих обстоятельствах любая стратегия, являющаяся наилучшим ответом на любой вектор доступных в РН смешанных стратегий, считается рационализируемой. То есть игрок может найти такой набор систем убеждений других игроков, что любой розыгрыш равновесной партии соответствовал бы этому набору систем.
Чистые координационные игры характеризуются неуникальными векторами рационализируемых стратегий. Нобелевский лауреат Томас Шеллинг (Schelling 1978) предположил и эмпирически продемонстрировал, что в подобных ситуациях игроки могут попытаться предсказать равновесие путем поиска фокальных точек, т.е. особенностей некоторых стратегий, которые, по их мнению, бросаются в глаза другим игрокам, и будут верить, что другие игроки будут считать эти особенности ключевыми. Например, если два человека хотят встретиться в определенный день в большом городе, но не могут связаться друг с другом, чтобы согласовать определенное время и место, оба могут разумно отправиться на самую известную городскую площадь города в полдень. В целом, хорошие игроки знакомы, или чем чаще они имели возможность наблюдать стратегическое поведение друг друга, тем вероятнее им удастся найти фокальные точки, по которым они смогут скоординироваться.
Координация была, действительно, первой темой теоретико-игрового применения, которая привлекла широкое внимание философов. В 1969 году философ Дэвид Льюис (Lewis 1969) опубликовал работу «Условие» (Convention), в которой концептуальный каркас теории игр был применен к фундаментальной проблеме эпистемологии ХХ века — вопросу о природе и пределах конвенций, управляющих семантикой, и их взаимосвязи с обоснованием пропозициональных убеждений. Базовую интуицию этой работы можно показать на простейшем примере.
Слово «цыпленок» обозначает цыплят, а «страус» обозначает страусов. Нам не было бы лучше или хуже, если бы слово «цыпленок» обозначало страусов, а слово «страус» обозначало бы цыплят. Однако нам было бы хуже, если бы половина из нас использовала эту пару слов первым способом, а другая половина — вторым, или все мы использовали оба слова произвольным образом в качестве общего термина для нелетающих птиц.
Конечно, об этом догадывались и до Льюиса; но он признал, что эта ситуация имеет логическую форму координационной игры. Таким образом, хотя конкретные конвенции могут быть произвольными, интерактивные структуры, которые стабилизируют и поддерживают их, таковыми не являются. Кроме того, равновесия, связанные с координацией значений существительных, как представляется, произвольны только потому, что мы не можем ранжировать их по Парето; но Рут Милликен (Millikan 1984) имплицитно показала, что в этом отношении они нетипичны для лингвистических координаций. Они, определенно, нетипичны для координирующих конвенций вообще, в то время как Льюис ошибся, переоценив «семантические интуиции» о «значении» «конвенции» (Bacharach 2006, Ross 2008).
Росс и Лакасс (Ross and LaCasse 1995) представили жизненный пример координационной игры, в которой РН не являются Парето-безразличными, но мы чаще имеем дело с Парето-доминируемыми РН. В городе водители должны координировать свое поведение на светофорах согласно одному из двух РН. Либо все должны следовать стратегии спешки, пытаясь проехать на желтый свет и притормаживать при переключении красного сигнала на зеленый, или все должны следовать стратегии торможения при желтом сигнале и стартовать при смене на зеленый. Оба шаблона — РН, и так как когда-то общество скоординировалось на одном из них, то у индивида нет стимула отклоняться: те, кто замедляет движение на желтый свет, в то время как другие спешат проехать на него, получат удар сзади, в то время как те, кто спешат на желтый свет в другом равновесии, рискуют столкнуться с теми, кто сразу же стартует на зеленый. Поэтому, как только схема городского движения утвердится на одном из этих равновесий, она там и останется. И действительно, это две модели, которые можно наблюдать в разных странах. Однако два этих равновесия не являются Парето-безразличными, поскольку второе РН позволяет большему числу автомобилей свернуть налево на каждом цикле в странах с левосторонним движением и направо в странах с правосторонним движением, что снижает главную причину пробок на городских дорогах и позволяет всем водителям ожидать более эффективного движения. К сожалению, по причинам, о которых мы можем только догадываться за отсутствием дальнейшей эмпирической работы и анализа, гораздо больше городов ориентированы на Парето-доминируемые, чем на Парето-доминирующие РН.
Конвенции о стандартах доказательств и научной рациональности, — темы из философии науки, задающие контекст анализа Льюиса, — скорее всего, будут иметь ранжируемый по Парето характер. Хотя, как наверняка напомнят нам последователи Томаса Куна, в социальной игре под названием «наука» равновесными по Нэшу могут оказаться самые разнообразные ситуации, очень маловероятно, что все они будут лежать на одной кривой безразличия по Парето. Эти темы, достаточно ярко представленные в современной эпистемологии, философии науки и философии языка, являются, по меньшей мере, неявными приложениями теории игр. (Широкий выбор применений и ссылок на источники по этим вопросам можно найти в Nozick 1998).
Большинство социальных и политических координационных игр, в которые играют люди, также имеют эту особенность. К сожалению для всех нас, в них крайне часты ловушки неэффективности, представленные Парето-доминируемым РН. И иногда динамика такого рода порождает самое страшное из всех рекуррентных человеческих коллективных поведений. Хардиновский анализ двух недавних случаев геноцида опирается на ту мысль, что малозначительные с точки зрения биологии признаки, по которым люди делят друг друга на расовые и этнические группы, крайне эффективно выступают в качестве фокальных точек в координационных играх, которые, в свою очередь, собираются в смертельные ДЗ.
Согласно Хардину, ни югославская, ни руандийская катастрофы не были, во-первых, дилеммами заключенных. То есть ни в одной из ситуаций, ни для одной из сторон большинство людей не начинали с того, что предпочитали уничтожение других для обеспечения взаимного сотрудничества.
Однако смертоносная логика координации, преднамеренно подстрекаемая корыстными политиками, динамично создала ДЗ. Некоторым отдельным сербам (хуту) было предложено воспринимать свои личные интересы как наилучшим образом реализующиеся посредством идентификации с групповыми интересами сербов (хуту). То есть они обнаружили, что некоторые из их обстоятельств, например, связанные с конкуренцией за рабочие места, имеют форму координационных игр.
Таким образом, они поступали так, чтобы создавать ситуации, в которых это будет справедливо и для других сербов (хуту). В конце концов, когда достаточное число сербов (хуту) идентифицировали свои личные интересы с групповыми, это отождествление стало почти универсально верным, потому что
(1) самой важной целью для каждого серба (хуту) стало поступать, как всякий другой серб (хуту), и
(2) наиболее сербским поступком, т.е. совершение которого сигнализирует координации, стало исключение хорватов (тутси).
То есть стратегии, связанные с подобным исключающим поведением, были отобраны постольку, поскольку имели эффективные фокальные точки. Эта ситуация привела к тому, что интерес отдельных — и индивидуально находящихся под угрозой — хорватов (тутси) лучше всего максимизировался путем координации вокруг групповой идентичности хорватов (тутси), что еще больше усилило давление на сербов (хуту) для обеспечения координации, и так далее.
Следует обратить внимание, что данный анализ не предполагает, что все это затеяли именно сербы или хуту; процесс мог быть (даже если не был на самом деле) совершенно обоюдным. Но результат ужасен: сербы и хорваты (хуту и тутси) кажутся все более угрожающими друг для друга, когда собираются вместе для самообороны, и так продолжается до тех пор, пока обе стороны не приходят к мысли о необходимости упреждающего удара по противнику. Если Хардин прав, — и здесь нас не интересует доказательство его правоты, а указание на мировую важность определения того, в какие игры фактически играют агенты, — тогда простое присутствие внешней силы (НАТО?) не изменит игру, что бы ни говорил нам Гоббс, поскольку эта сила не может угрожать ни одной из сторон чем-то страшным, нежели то, чего каждая сторона ждала от другой. Нужно было перекалибровать оценки интересов, что (возможно) и произошло в Югославии, когда хорватская армия начала решительно побеждать и боснийские сербы решили, что их личные/групповые интересы лучше реализовываются вводом натовских миротворцев. Руандийский геноцид был решен военным путем, в данном случае победой тутси. (Но это стало началом самой смертоносной войны с 1945 года — войны в Конго в 1998–2006 годы).
Конечно, это не значит, что большинство повторяемых игр приводят к катастрофам. Биологический базис дружбы у людей и других животных частично функционирует в логике повторяемых игр. Важность выигрышей, достигаемых через сотрудничество в будущих играх, приводит тех, кто ожидает взаимодействия в этих играх, к менее эгоистическому поведению, нежели чем то, к которому они в противном случае склонились бы в настоящих играх. Тот факт, что такие равновесия стабилизируются благодаря обучению, придает дружбе характер и логику накопленных за долгое время инвестиций, которыми большинство людей с удовольствием любуются сквозь розовые очки сентиментальности. Кроме того, культивирование общих интересов и чувств возводит целые сети фокальных точек, вокруг которых координация становится намного более легкой.
Командное мышление и условные игры
После того, как Льюис (Lewis 1969) ввел координационные игры в философию, философ Маргарет Гилберт (Gilbert 1989) заявила, возражая Льюису, что теория игр является неправильной аналитической техникой осмысления человеческих конвенций, поскольку, среди прочего, она слишком «индивидуалистична», тогда как конвенции по существу являются социальными феноменами.
Проще говоря, она утверждала, что конвенции суть не просто продукты решений множества отдельных людей, как мог бы предположить теоретик, который моделирует конвенцию как равновесие игры с участием n человек, в которой каждый игрок является отдельным человеком. Аналогичные опасения по поводу якобы индивидуалистических оснований теории игр озвучивал философ Мартин Холлис (Hollis 1998) и экономисты Роберт Сагден (Sugden 1993, 2000, 2003) и Майкл Бакарак (Bacharach 2006). В частности, это побудило Бакарака предложить теорию командного мышления (team reasoning), которая была завершена Сагденом вместе с Нэтали Голд после смерти Бакарака. Эта теория представляет собой ключевую часть фонового контекста, в котором становится видна ценность недавнего крупного расширения теории игр — теории условных игр Уинна Стирлинга (Stirling 2012).
Рассмотрим снова однократную дилемму заключенного, которую мы обсуждали в разделе 2.4, представленную с инвертированной матрицей для удобства последующего обсуждения:
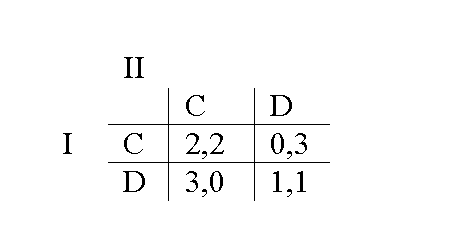
(«С», cooperation обозначает стратегию кооперации с соперником (т.е. отказ дать показания), а «D», defection, обозначает стратегию отступления от сделки с противником (т.е. дать показания)). Многие сильно недоумевают, когда теоретик игр говорит им, что игроки, традиционно носящие почтенный титул «рациональных», должны сделать выбор в этой игре таким образом, чтобы получить результат (D, D). Объяснение, кажется, взывает к весьма сильным формам как дескриптивного, так и нормативного индивидуализма. В конце концов, если игроки приписали бо́льшую ценность общественному благу (для их сообщества из двух воров), чем своему индивидуальному благополучию, тогда они могли бы сделать это и самостоятельно; выдвигается возражение, что теоретико-игровая «рациональность» навязывает поведение, которое является порочным даже с точки зрения увеличения индивидуального благополучия. Сагден (Sugden 1993), по-видимому, был первым, кто предположил, что игроки, которые действительно могут быть названы «рациональными», даже если они не альтруистичны, должны в однократной ДЗ мыслить как команда, то есть избирать ту или иную стратегию путем вопрошания «что лучше для нас?», вместо «что лучше для меня?».
Как утверждал Бинмор (Binmore 1994), и что признали в дальнейшем большинство комментаторов, подобная критика спутала теорию игр как математику с вопросами о том, какие модели теории игр наиболее применимы к ситуациям, в которых оказываются люди. Если игроки ценят полезность команды выше, чем более узкие индивидуалистические интересы, то это должно быть отражено в выигрышах, связанных с теоретико-игровой моделью их выбора. Если в ситуации, моделируемой выше в качестве ДЗ, забота игроков о «команде» достаточно сильна, чтобы переключиться со стратегии D на C, то выигрыши (в кардинальной интерпретации) верхней левой ячейки должны быть подняты как минимум до 3. (При 3 игроки будут безразличны как к сотрудничеству, так и отказу от него). Тогда мы получим следующую игру:
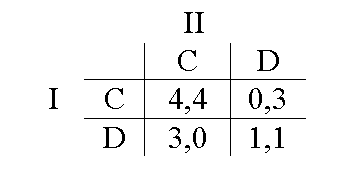
Это уже не ДЗ; это игра на доверие (an Assurance game), в которой есть два нэшевских равновесия (C, C) и (D, D), причем первое из них доминирует по Парето над последним. Таким образом, если игроки находят это равновесие, нам не следует говорить, что они разыграли ненэшевские стратегии в дилемме заключенного. Скорее, мы должны сказать, что ДЗ была неправильной моделью для их ситуации.
Вопрос здесь состоит в том, какая конвенция здесь будет наилучшей, т.е. какую математическую модель следует использовать для описания эмпирической ситуации. Бинмор, несомненно, прав — и большинство комментаторов признали его правоту, — при условии, что мы будем рассматривать выигрыши в играх со ссылкой на функции полезности с неограниченными областями определения. Такова стандартная практика в подавляющем большинстве случаев, как в экономике, так и в формальной теории принятия решений. В течение многих лет этот вопрос считался решенным. Однако Сагден (Sugden 2018) в своей новейшей работе утверждает, что есть основания — не зависящие от технических соображений касательно того, какие конвенции наилучшим образом подходят для репрезентации эмпирических интеракций в виде игр — отказаться от неограниченных областей определения при анализе благосостояния (т.е. при занятии нормативной экономикой). Опираясь на эту идею, Сагден возвращается к теоретико-игровым моделям, где выигрыши ограничены объективными метриками, такими как монетарный доход. Важные вопросы экономики благосостояния, на которые проливает свет Сагден, слишком интересны для критика, чтобы отказываться от их рассмотрения на основании только упрямства в вопросе выбора конвенции для интерпретации игровых репрезентаций. Слишком рано судить, выдерживают ли критику последние новации Сагдена в анализе благосостояния. Если они не выстоят, то и основания для принятия альтернативных конвенций интерпретации выигрышей пропадут. Однако я полагаю, что нас ожидает период крайне интенсивных инноваций в этой области, и в ходе него экономисты и другие аналитики привыкнут работать с двумя разными конвенциями, в зависимости от контекста рассматриваемой проблемы. Если все это и вправду случится, тогда мы можем предвосхитить и дальнейший этап, на котором — поскольку контексты проблемы не имеют обыкновения оставаться изолированными друг от друга — нам потребуется новая формализация, дабы обе конвенции могли быть задействованы в едином применении без какой-либо путаницы. Но эти рассуждения опережают нынешнее состояние теории.
Давайте вернемся к той стадии развития теории, которая последовала за критикой Бинмора. Последователи теории Бакарака, Сагден и Голд (в Bacharach 2006: 171–173), в отличие от Холлиса и Сагдена (Hollis and Sugden 1993), используют конвенциональную интерпретацию выигрыша, при которой смоделированные игроки могут кооперироваться в однократной ДЗ, если по меньшей мере один игрок допускает ошибку. (Для некоторых вариантов ошибок, вариант (C, C) может быть непротиворечив с QRE как концепция решения. Опираясь на эту интерпретацию, Бакарак, Сагден и Голд утверждают, что игроки-люди будут избегать представить ситуации так, будто однократная ДЗ является правильной моделью в их обстоятельствах. Ситуация, которую «индивидуалистичные» агенты будут рассматривать как ДЗ, может казаться «командно мыслящим» агентам упомянутой выше игрой на доверие. Обратите внимание, что командное благополучие может иметь значение для (кардинальных) выигрышей без того, чтобы преодолевать соблазн одностороннего отступничества. Предположим, это поднимет цену кооперации их до 2,5 для каждого игрока; тогда игра останется ДЗ. Этот момент важен, так как в экспериментах, в которых испытуемые разыгрывают последовательности однократных ДЗ (не повторяющихся ДЗ, поскольку от раунда к раунду оппоненты меняются), большинство субъектов начинают с кооперации, но, по мере продолжения эксперимента, осваивают и отступничество. Согласно Бакараку, такие субъекты изначально подходят к игре, руководствуясь «командным мышлением». Однако меньшинство субъектов интерпретируют ее с позиций индивидуалистического мышления и отступаются, получая прибыль «безбилетников». Затем «коллективисты» переоценивают ситуацию, чтобы защититься. Это важный аспект подхода Бакарака. «Индивидуалисты» и «коллективисты» — не разные типы людей. Люди, как подчеркивает Бахарах, переключаются между индивидуалистической и командной агентностями.
Теперь рассмотрим следующую чистую координационную игру:
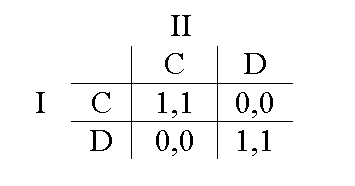
Мы можем интерпретировать это как репрезентацию ситуации, где игроки сугубо индивидуалистичны и где, следовательно, они не видят разницы между двумя нэшевскими равновесиями (верхняя, левая) и (нижняя, правая), или мыслят командно, но не поняли, что для них как для команды лучше, если они стабилизируются вокруг одного из РН, а не другого. Если они это поймут, возможно, найдя фокальную точку, то чистая координационная игра превращается в игру, известную как Hi-Lo:

Важно то, что это преобразование требует не только командного мышления. Игрокам также нужны фокальные точки, чтобы узнать, какое из двух чистой координационных равновесий предлагает менее рискованную перспективу социальной стабилизации (Binmore, 2008). На самом деле, Бакарак и его последователи интересуются отношениями между чистыми координационными играми и играми Hi-Lo по особой причине.
Это не подразумевает критики РН в качестве концепции решения, которое не отдает предпочтение одному вектору стратегии перед другим в игре на чистую координацию. Однако РН также не предпочитает выбор (верхней, левой) выбору (нижней, правой) в игре Hi-Lo, так как (нижняя, правая) также является РН.
Тут Бакарак и его друзья принимают философское обоснование программы уточнения. Несомненно, сетуют они, «рациональность» рекомендует (верхнюю, левую). Поэтому, заключают они, аксиомы командного мышления должны быть встроены в усовершенствованные основы теории игр.
Для того, чтобы оценить идеи Бакарака, нам не обязательно соглашаться с мыслью, что для принятия интуитивно общей концепции рациональности теоретические концепции решения должны быть уточнены. Сторонник непсихологической теории игр может предложить тонкое смещение акцентов: вместо того, чтобы беспокоиться о том, должны ли наши модели следовать командно-ориентированным нормам рациональности, мы можем просто сослаться на эмпирические данные о том, что люди и, возможно, другие агенты часто делают выбор, демонстрирующих наличие предпочтений, обусловленных благополучием групп, с которыми они связаны.
В этом отношении их агентскость частично или полностью — и, возможно, стохастически — отождествляется с этими группами, и это необходимо учитывать, когда мы моделируем их агентность с помощью функций полезностей. Тогда мы могли бы лучше описать нужную нам теорию как теорию командного выбора, нежели чем как теорию как теорию командного мышления. Обратите внимание, что такая философская интерпретация согласуется с идеей, что некоторые наши доказательства и, возможно, даже наше лучшее доказательство существования выбора, ориентированного на команду, является психологическими. Это также согласуется с предположением о том, что процессы переключения агентности людей с индивидуалистической на командную и обратно, частично латентны. Дело просто в том, что нам не нужно следовать Бакараку в его предположении, что теория игр является моделью мышления или рациональности, дабы убедиться в том, что он определил зазор, который мы хотели заполнить при помощи формальных инструментов.
Итак, действительно ли человеческие решения обнаруживают командно-ориентированные предпочтения? Стандартные примеры, в том числе и Бакарака, взяты из командных видов спорта. Члены таких команд испытывают значительное социальное давление, заставляющее их выбирать действия, максимизирующие перспективы команды на победу, вместо действий, повышающих их персональную статистику.
Проблема этих примеров состоит в том, что они встраивают сложные проблемы идентичности в оценку функций полезности; сугубо корыстный игрок, стремящийся завоевать популярность у болельщиков, может вести себя так же, как и командный игрок.
Солдаты в боевых условиях служат более убедительным примером. Хотя попытки убедить солдат пожертвовать своей жизнью в интересах своих стран часто неэффективны, большинство солдат можно убедить идти на чрезвычайный риск при защите своих товарищей, или когда враги непосредственно угрожают их родным городам и семьям. Легко обнаружить другие типы команд, с которыми большинство людей, как правило, идентифицируют себя: проектные группы, небольшие компании, местные профсоюзы, кланы и домашние хозяйства.
Выражено индивидуалистическая социальная теория пытается конструировать такие команды по принципу равновесия в играх между отдельными людьми, но никакие предпосылки теории игр (или, в данном случае, в господствующей экономической теории), не навязывают подобной перспективы (критический обзор различных вариантов см. в Guala 2016). Вместо этого мы можем предположить, что команды часто экзогенно связаны друг с другом сложными взаимосвязанными психологическими и институциональными процессами. Это побуждает теоретика игр задуматься о математической миссии, которая состоит не в моделировании командного мышления, но выбора, обусловленного существованием командной динамики.
Это приводит нас к расширению теории игр Стирлинга (Stirling 2012) для учета таких обусловленных взаимодействий. Цель Стирлинга состоит в том, чтобы формализовать и вывести условия равновесия для понятия группового предпочтения, которое, с одной стороны, не является простой совокупностью индивидуальных предпочтений, но также и не просто предполагает существование трансцендентной коллективной воли, управляющей поведением отдельных лиц. Стерлинг интуитивно метит в процессы, посредством которых люди приходят к своим фактическим предпочтениям, частично с опорой на сравнительные последствия для группового благосостояния различных возможных типов предпочтений, которые участники предположительно могли бы демонстрировать по отдельности. Ключевым ограничением для Стирлинга является то, что концепции решения для теории (т.е. ее равновесия) должны формально обобщать стандартные концепции решения (РН, SPE, QRE), а не заменять их. Теория кондициональной игры должна быть «реальной» теорией игр, а не «псевдо»-теорией игр.
Давайте разовьем интуитивную идею обуславливания предпочтений более подробно. Люди могут часто, — возможно, такое поведение типично, — откладывать всесторонний разбор собственных предпочтений до тех пор, пока не получат больше информации о предпочтениях других людей, являющихся их нынешними или потенциальными напарниками. Сам Стирлинг приводит простой (возможно, слишком простой) пример из книги Р. Кини и Х. Райфы (Keeney and Raiffa 1976), в котором фермер при покупке земли формирует однозначное предпочтение о климатических условиях только после того, как узнает предпочтения своей жены — и даже будет принимать свое решение частично оглядываясь на них. Этот небольшой мысленный эксперимент вполне правдоподобен, хотя и не идеально иллюстративен, поскольку легко смешивается с крайне невнятными соображениями о слиянии агентности в идеальном браке — в то время как важно различать динамику обуславливания предпочтений в командах различных агентов от простого коллапса индивидуальной агентности.
Так что давайте возьмем пример получше.
Представьте председательницу совета корпорации, которая консультируется со своим не склонным к риску советом о том, следует ли им принять опасное и враждебное предложение о поглощении.
Сопоставим две процедуры, которые она могла бы использовать:
(i) направить каждому члену совета директоров личное письмо об этой идее за неделю до собрания;
(ii) огорошить их прямо на заседании.
Большинство согласятся с тем, что эти варианты могут дать различные результаты, в первую очередь потому, что в варианте (i), но не (ii), некоторые члены совета успеют сформировать свое личное мнение и укрепиться в нем — на что у них не будет времени, если они узнают, что кто-то другой хочет оспорить предложение председателя в тот же момент, когда они впервые услышат это предложение. В обоих случаях, на момент голосования множество индивидуальных предпочтений должны быть объединены путем голосования. Но намного более вероятно, что некоторые предпочтения во втором варианте развития событий будут обусловлены предпочтениями других. Обусловленное предпочтение, по определению Стирлинга, это предпочтение, на которое влияет информация о предпочтениях (определенных) других.
Второе понятие, формализованное в теории Стирлинга, — это согласованность (concordance). Оно обозначает степень спорности или разногласий, которую вызывет некий набор предпочтений, включая набор обусловленных предпочтений, если между ними будет достигнуто равновесие. Члены или лидеры команд не всегда хотят максимизировать согласованность, приводя все внутренние игры к виду игры на доверие или Hi-lo (хотя они всегда будут стремиться исключить ДЗ). Например, менеджер может хотеть поощрить конкуренцию между центрами генерации прибыли в фирме, одновременно с этим желая, чтобы центры возникновения затрат (МВЗ) полностью идентифицировались с командой в целом.
Стирлинг формально определяет теоремы репрезентации для трех видов упорядоченных функций полезности: условная полезность, согласованная полезность и условная согласованная полезность. Они могут применяться рекурсивно, т.е. к индивидам, командам и командам команд. Тогда ядром формальной разработки становится теория, объединяющая условные согласованные предпочтения индивидуумов для построения моделей командного выбора, который не налагается экзогенно на членов команды, а вытекает из их отдельных предпочтений. При введении стирлинговской процедуры агрегации в данном контексте полезно изменить его терминологию и, соответственно, перефразировать его, а не цитировать напрямую. Это связано с тем, что Стирлинг говорил о «группах», а не «командах». Стирлинг не упоминает работу Бакарака, поэтому его теория не укладывается в контекст проблематики командного мышления (или того, что мы могли бы интерпретировать как выбор, ориентированный на команду). Но идеи Бакарака задают удобный фон, на котором можно описать технические достижения Стирлинга как расширение области применения теории игр в социальных науках. Затем мы можем перефразировать пять его ограничений на агрегацию предпочтений следующим образом:
(1) Обусловленность. На порядок предпочтений члена команды могут влиять предпочтения других членов команды, то есть они могут быть обусловленными. (Влияние может быть нулевым, и в этом случае задача по ранжированию условных предпочтений сводится к ранжированию категориальных предпочтений к стандартной RPT).
(2) Эндогенность. Упорядоченная согласованность для команды должна определяться социальными взаимодействиями её субкоманд. (Это условие гарантирует, что предпочтения команды не просто накладываются на индивидуальные предпочтения).
(3) Ацикличность. Отношения социального влияния не являются взаимными. (Возможно, на первый взгляд это выглядит странным ограничением: безусловно, большая часть социальных влияний среди людей взаимны. Но, как отмечалось ранее, нам необходимо сделать так, чтобы обусловленное предпочтение отличалось от слияния агентов, и настоящее условие помогает нам это сделать. Что еще более важно, чисто математически это позволяет представлять команды в виде ориентированных графов. Это условие не накладывает столь строгие ограничения на моделирование, как можно было бы предположить изначально, поскольку оно лишь запрещает нам представлять агента j, находящегося под влиянием агента i, как прямо влияющего на i. Нам ничто не мешает представлять j как влияющего на k, который, в свою очередь, влияет на i).
(4) Взаимозаменяемость. Порядок согласованных предпочтений инвариантен при преобразованиях репрезентации, которые эквивалентны по отношению к информации об условных предпочтениях.
(5) Монотонность. Если одна подкоманда предпочитает выбор А выбору В, а все другие подкоманды безразличны к А и В, тогда команда не предпочтет выбор В выбору А.
При этих ограничениях Стирлинг доказывает теорему агрегации, которая соответствует общему результату обновления полезности в свете новой информации, которым занимался Аббас (Abbas 2003). Каждый член команды подсчитывает командные предпочтения, агрегируя условные согласованные предпочтения. Затем аналитик применяет маргинализацию. Пусть Xn — команда. Пусть Xm = {Xj1, …, Xjm}, а X = {Xi1, …, Xik} — непересекающиеся подкоманды Xn. Тогда предельную согласованную полезность Xm по отношению к подкоманде {Xm, Xk} мы получаем суммированием по Ak, что дает
а предельная полезность отдельного члена команды Xi задается через
где означает, что сумма берется по всем аргументам, кроме ai (Stirling 2012: 62). Эта операция дает нам безусловные (non-conditional) предпочтения для каждого i ex post — они будут меняться в зависимости от условных согласованных предпочтений и информации которой они обусловлены, т.е. условных согласованных предпочтений команды. После того, как все ex post предпочтения агентов вычислены, игры, в которых они участвуют, могут быть решены путем стандартного анализа.
Решение Стирлинга, по его словам, является истинным обобщением стандартной теории полезности, позволяющим сделать безусловную («категориальную») полезность специальным случаем. Оно дает основу для формализации командной полезности, которую можно сопоставлять с: предварительно оговоренной категориальной полезностью для игрока или подкоманды; условной полезностью для игрока или подкоманды; условной согласованной полезностью для игрока или подкоманды. После того, как предпочтения каждого индивида в проблеме командного выбора маргинализованы, можно использовать анализ РН, ИРП или QRE для проблемы с полной информацией о социальных влияниях. Ситуации неполной информации могут быть решены с использованием равновесия Байеса-Нэша или последовательного равновесия.
Обязательства
В некоторых играх игрок может улучшить свой результат с помощью действия, которое перекрывает для него путь к тому, что было бы его лучшим действием в соответствующей игре с одновременными ходами. Такие действия называются обязательствами (commitments), и они могут служить альтернативой внешнему принуждению в играх, которые в противном случае решались бы на основе Парето-неэффективного равновесия.
Рассмотрим следующий гипотетический пример (не являющийся ДЗ).
Предположим, у вас есть участок земли, прилегающий к моему, и я бы хотел его купить, чтобы расширить свой участок. К сожалению, вы не хотите продавать свой участок по цене, которую я готов заплатить. Если мы действуем одновременно — вы публикуете свою продажную цену, а я независимо от вас называю своему агенту свою запрашиваемую цену, — то продажа не состоится. Поэтому я мог бы попытаться изменить ваши стимулы, сделав начальный ход, в котором объявлю, что я построю дурно пахнущую установку для очистки сточных вод на своей земле рядом с вами, если вы не продадите мне свой участок, тем самым побуждая вас снизить цену. Теперь я превратил это в игру с последовательными ходами. Однако этот ход пока ничего не меняет. Если вы отказываетесь продавать участок несмотря на мою угрозу, тогда не в моих интересах эту угрозу выполнять, потому что, нанося ущерб вам, я также наношу ущерб себе. Поскольку вы знаете это, вы должны игнорировать мою угрозу. Моя угроза неправдоподобна, это типичный блеф.
Однако я мог бы сделать свою угрозу правдоподобной, взяв на себя обязательства. Например, я мог бы заключить контракт с какими-нибудь фермерами, пообещав снабдить их очищенными сточными водами (удобрениями) с моей установки, но при этом включить в контракт оговорку, согласно которой я освобождаюсь от обязательств, если удвою размер своего земельного участка и, таким образом, смогу использовать его как-либо иначе. Теперь моя угроза вполне правдоподобна: если вы не продадите землю, я буду обязан возвести очистное сооружение. Поскольку вы это знаете, у вас теперь есть стимул продать мне свою землю, чтобы она не погибла.
Этот пример демонстрирует одно из множества принципиальных различий между логикой непараметрической и параметрической максимизации. В параметрических ситуациях увеличение количества вариантов никогда не сможет ухудшить положение агента. (Даже если новая опция хуже, чем изначальные, он может просто ее проигнорировать). Но если обстоятельства не являются параметрическими, можно повлиять на стратегию одного агента в пользу другого, если сократить число вариантов. Предание Кортесом своих кораблей огню (см. раздел 1) — это, несомненно, такой случай.
Другой пример проиллюстрирует сказанное нами, а также продемонстрирует применимость этих принципов в различных типах игр. Мы построим воображаемую ситуацию, которая не является ДЗ, поскольку лишь один игрок имеет стимул к отступничеству — но это социальная дилемма, поскольку ее нэшевское равновесие в отсутствии обязательств, взятых одним из игроков, — Парето-неоптимально по отношению к результатам, достижимых с помощью механизма взятия обязательств (commitment device). Предположим, мы вдвоем хотим похитить редкую антилопу из национального парка для последующей продажи. Один из нас должен погнать животное по направлению ко второму человеку, который ждет в засаде, чтобы застрелить антилопу и погрузить тело на грузовик. Вы обещаете, разумеется, поделиться доходами со мной. Однако ваше обещание не заслуживает доверия. После того, как вы получили тушу, у вас нет причин не сбежать с ней, получив себе полную ее стоимость. В конце концов, я даже не могу пожаловаться в полицию, не подвергая себя риску ареста. Но теперь предположим, что я добавлю в игру следующий вступительный шаг. Перед охотой я оснащу пикап сигнализацией, которую можно отключить только с помощью кода, который знаю только я. Если вы попытаетесь уехать без меня, раздастся звуковой сигнал, и мы оба будем пойманы. Вы это знаете, и потому у вас есть стимул ждать меня. Здесь важно заметить, что вы предпочтете, чтобы сигнализацию настраивал я, так как это делает ваше обещание отдать мне мою долю правдоподобным. Если я этого не сделаю, тем самым оставив ваше обещание неправдоподобным, мы в принципе не сможем договориться пойти на преступление и оба потеряем шанс выиграть от продажи трофея. Таким образом, вы извлекаете пользу из того, что я мешаю вам сделать то, что оптимально для вас в подыгре.
Теперь мы можем совместить наш анализ дилемм заключенного с механизмами принятия обязательств в обсуждении кейса, который впервые сделал теорию игр известной за пределами академического сообщества. Ядерное противостояние между сверхдержавами в период холодной войны всесторонне изучалось первым поколением теоретиков игр, многие из которых работали на американские военные структуры. Паундстоун рассказывает относительно «очищенную» историю участия в происходившем теоретиков игр, которая долгое время была доступна историкам-любителям, готовым положиться на вторичные источники и воспоминания самих исследователей (Poundstone 1992). Недавно было проведено более скептическое и профессиональное историческое исследование (Amadae 2016), которое дает более академический контекст все еще наводящим ужас мемуарам пионера в области прикладной теории игр, участника разработки ядерной стратегии холодной войны, человека, известного благодаря организованной им утечке секретных документов о войне во Вьетнаме, Даниэля Эллсберга (Ellsberg 2017). Историю, согласующуюся с этими воспоминаниями, но в меньшей степени шокирующую читателя, рассказывает и Эриксон (Erickson 2015)
Причины такого диагноза были следующими. Предположим, что СССР наносит первый ядерный удар по США. В этот момент американский президент обнаруживает, что его страна уже уничтожена. Он не вернет ее, если взорвет мир, поэтому у него нет стимула для исполнения угрозы, которая уже не имеет никакого смысла. Поскольку русские могут это предвидеть, им следует проигнорировать угрозу возмездия и нанести удар первыми. Конечно, американцы находятся в строго симметричной позиции, поэтому они тоже должны нанести удар первыми. Каждая сторона признает этот стимул со стороны другой и поэтому будет ожидать нападения, если она не поспешит нанести упреждающий удар. Поскольку это единственное нэшевское равновесие в игре, нам следует ожидать лишь гонки между двумя державами в нанесении упреждающего удара. Совершенно очевидным следствием из этого будет разрушение мира.
Этот теоретико-игровой анализ вызывал неподдельный ужас и опасения с обеих сторон в период холодной войны и, как считается, привел к ряду мощных попыток создать стратегические средства для принятия обязательств. Некоторые анекдоты, например, рассказывают, как президент Никсон пытался с помощью ЦРУ убедить русских в том, что он сумасшедший или часто бывает пьян, чтобы они поверили, что он нанесет ответный удар, даже если это уже не будет в его интересах. Аналогичным образом, КГБ, как утверждается, с той же целью фабриковал медицинские заключения, преувеличивающие дряхлость Брежнева. В конечном счете, стратегическая симметрия, которая беспокоила аналитиков Пентагона, была сложной и, возможно, нарушалась изменениями в американской тактике размещения ракет. Они оснастили мировой флот подводных лодок достаточным количеством ракет для уничтожения СССР. Это снизило качество и надежность их коммуникаций и, таким образом, ввело элемент стратегически значимой неопределенности. По всей вероятности, президент мог быть не уверен в возможности связаться с подводными лодками и отменить приказ об атаке, который вступал в силу автоматически, как только советская ракета пересекала радиолокационную линию в Северной Канаде. Разумеется, ценность этого нарушения симметрии зависела от осознания русскими потенциальной проблемы. В классическом фильме Стэнли Кубрика «Доктор Стрейнджлав» катастрофа происходит случайно, потому что русские строят машину конца света, которая автоматически наносит ответный удар, независимо от решимости советского руководства следовать плану, предполагаемому MAD, но затем сохраняют ее существование в тайне. В результате, когда бесспорно безумный американский полковник отправляет ракеты в Россию, и американский президент пытается убедить своего советского коллегу в том, что нападение было непреднамеренным, глава советского правительства смущенно рассказывает ему о тайной машине конца света. Теперь два лидера уже ничего не могут сделать, кроме как смотреть в ужасе, как мир взрывается из-за теоретико-игровой ошибки.
Пример противостояния из эпохи холодной войны, хотя и известен и имеет большое значение для истории теории игр и ее расхожей рецепции, в то время полагался на не совсем точный анализ. Теоретики игр на службе военных почти наверняка ошиблись уже тогда, когда взялись моделировать холодную войну как однократную ДЗ. Стоит как минимум отметить, что игра по удерживанию ядерного равновесия была частью более крупных и очень сложных игр мировых держав. С другой стороны, далеко не очевидно, что для каждой сверхдержавы уничтожить другую, избежав при этом самоуничтожения, на самом деле было наиболее ценным результатом. Если бы это было не так, как для одной, так и для обеих стран, то игра не была дилеммой заключенных. Мудрый циник мог бы предположить, что исследователи с обеих сторон разыгрывали хитроумную стратегию в игре по выбиванию финансирования, и эта игра включала в себя кооперацию друг с другом, чтобы убедить своих политиков выделить больше ресурсов на вооружение.
В более приземленных обстоятельствах большинство людей использует расхожее средство принятия обязательств, которое еще Адам Смит сделал центральным элементом своей теории социального порядка: ценность своей репутации. Даже если я втайне скупой, я, возможно, захочу заставить других думать, что я щедр, раздавая чаевые в ресторанах, включая те, в которых я больше никогда не собираюсь побывать. Чем больше я занимаюсь этим, тем больше я вкладываюсь в ценную репутацию, которой я могу нанести серьезный урон за счет одного лишь акта очевидной низости при свидетелях. Таким образом, моя с трудом заработанная репутация щедрого человека действует как механизм обязательств в определенных играх, сам по себе требующий повторных инвестиций. Со временем моя благожелательность может стать привычной и, следовательно, нечувствительной к случайным обстоятельствам, вплоть до того, что у аналитика не остается никаких эмпирических оснований продолжать моделировать меня как предпочитающего скупость. Существует много доказательств тому, что гиперсоциальность людей поддерживается возникшими в ходе развития биологическими диспозициями (которые обнаруживаются у большинства, но не у всех людей) эмоционально страдать от недоброжелательных сплетен и страха перед ними. Люди также сугубо естественным образом предрасположены к тому, чтобы наслаждаться сплетнями, а значит, наказывать других, предавая огласке факт нарушения ими обязательств — это форма социального контроля, которая не кажется слишком дорогостоящей и потому охотно применяется. Хорошей особенностью подобной формы наказания является то, что она может, в отличие от, скажем, побивания людей палками, быть отозвана без причинения долгосрочного ущерба наказуемому. Это замечательное свойство для средства, целью которого является поддержание стимулов для участия в совместных социальных проектах; сотрудничество, как правило, более плодотворно, если кости всех участников команды целы. Таким образом, соглашения о прощении также играют стратегическую роль в этом чрезвычайно элегантном средстве принятия обязательств, которое создал для нас естественный выбор. Наконец, нормы представляют собой продукт культурной эволюции и представляют собой взаимные ожидания в группе людей (и, если на то пошло, слонов, дельфинов или обезьян), которые обладают дополнительным свойством — лица, их нарушающие, могут наказывать себя чувством вины или стыда. Таким образом, они зачастую совершают кооперативные поступки вопреки своим сугубо личным интересам, даже когда никто не обращает на это внимания. Религиозные истории или даже философские выдумки, включая кантианскую «рациональность», особенно часто используются для объяснении норм, поскольку их теоретико-игровая основа не приходит людям на ум.
Хотя так называемые «моральные переживания» (moral emotions) чрезвычайно полезны для соблюдения обязательств, они не являются для них необходимыми. Большие человеческие институты, как всем хорошо известно, отличаются крайней нравственной глухотой; однако обязательства, как правило, имеют решающее значение для логики их функционирования. Например, правительство, искушаемое провести переговоры с террористами для освобождения заложников, в отдельном случае может взять на себя обязательство держаться стратегии «черты на песке» ради сохранения своей репутации, необходимой для того, чтобы не провоцировать террористов на будущие атаки. Другим примером можно назвать авиакомпанию Qantas Airlines Australia. У Qantas не было ни одного несчастного случая со смертельным исходом, и некоторое время (до тех пор, пока с ней не приключились несколько происшествий без погибших, привлекать внимание к которым она, вероятно, опасалась) она активно это рекламировала. Это означает, что ее авиалайнеры, по крайней мере в течение этого периода, вероятно, были более безопасными, чем в среднем, даже если изначальное преимущество было лишь статистической удачей, поскольку ценность способности заявлять о своих идеальных показателях росла по мере длительности ее наличия, и, таким образом, давала авиакомпании стимулы нести более высокие расходы на обеспечение безопасности. Скорее всего, у компании все еще есть стимул вкладывать больше средств в сохранение своего рекорда, т.е. дать ему пересечь роковой для ее репутации рубеж между 0 и 1.
Дабы репутационные эффекты продолжали стимулировать взятие на себя обязательств, должны соблюдаться определенные условия. Во-первых, игра должна быть многократной. Репутация не имеет стратегической ценности в однократной игре. Во-вторых, ценность репутации для того, кто о ней печется, должна быть выше, чем ценность принесения этой репутации в жертву на любом раунде многократной игры. Таким образом, игроки могут поддерживать обязательства, уменьшая ценность каждого раунда, чтобы соблазн отступиться в любом раунде никогда не становился достаточно высоким, чтобы стать невыносимым искушением. Например, стороны договора могут обменивать свои облигации маленькими инкрементами, чтобы таким образом уменьшать стимулы обеих сторон к отступничеству. Так, строителям могут платить еженедельно или ежемесячно. Аналогичным образом, Международный валютный фонд часто выделяет кредиты правительствам небольшими траншами, тем самым уменьшая стимулы правительств нарушить условия займа, получив деньги; да и правительства могут предпочитать подобные соглашения, дабы устранить внутреннее политическое давление использовать полученные деньги не по назначению. Конечно, всем нам известны случаи, когда выигрыш от выхода из соглашения в текущем раунде становится слишком большим по сравнению с более долгосрочной ценностью репутации для дальнейшего сотрудничества — в один прекрасный день казначей общества может скрыться вместе с фондом. Хотя и взятие на себя обязательств из-за заботы о своей репутации — одна из базовых скреп общества, но никакой естественный связующих механихм не будет идеально эффективным.
Эволюционная теория игр
Гинтис (Gintis 2000, 2009) считает обоснованным утверждение, что «теория игр является универсальным языком для объединения наук о поведении». Хорошие примеры подобной работы по объединению действительно имеются. Бинмор (Binmore 1998, 2005) моделирует историю общества как серии сближений на все более эффективных равновесиях в регулярно встречающихся транзакционных играх, прерываемых эпизодами, где некоторые люди пытаются перейти к новым равновесиям, отклоняясь от устойчивых равновесных путей, вызывая тем самым периодические катастрофы. (Сталин, например, пытался переориентировать свое общество на ряд равновесий, в которых люди больше заботились бы о будущем промышленном, военном и политическом могуществе своего государства, чем о своей собственной жизни; он не добился успеха, однако его усилия безусловно, создали ситуацию, при которой на протяжении нескольких десятилетий многие советские люди придавали гораздо меньшее значение жизни других людей, чем это обычно принято). Кроме того, применение теории игр к поведению выходит далеко за рамки политики. Например, в разделе 4 мы рассмотрели идею Льюиса, что каждый человеческий язык представляет собой сеть равновесий Нэша в координационных играх вокруг передачи информации.
Льюис, ввиду давности его работы, ограничивался статической теорией игр, модель который предполагает, что агенты свободно выбирают свои стратегии, которые задаются экзогенно фиксированными функциями полезности. Из-за этого его работа побудила ряд философов отправиться в бессмысленное путешествие на поиски общей аналитической теории рациональности конвенций (как отметил Бикхард в Bickhard 2008). Хотя Бинмор раскритиковал этот подход в серии работ, сделав на этом своего рода карьеру, Гинтису (Gintis 2009a) недавно удалось обозначить суть проблемы с особой ясностью. РН и SPE являются хрупкими концепциями решения, когда применяются к вычислительным механизмам, возниквшим естественным образом, таким как мозг животного (включая человеческий). Как мы уже видели выше в разделе 3, в координационных (и других) играх со множеством нэшевских равновесий, то, что экономически рационально для игрока, крайне чувствительно к знанию других игроков. В общем случае, когда игроки оказываются в играх, где у них нет строго доминирующих стратегий, у них есть только несложные стимулы для розыгрыша стратегий РН или SPE — в той мере, в которой можно ожидать, что другие игроки найдут свои стратегии РН или SPE. Есть ли у нас разумные основания ожидать, что общая теория стратегической рациональности, вроде той, которую ищут философы, будет предусматривать все случайности? Обращение к байесовским принципам рассуждения, как мы рассмотрели в разделе 3.1 — стандартный способ инкорпорировать подобную неопределенность в теории рационального, стратегического решения. Однако, как, следуя за Сэвиджем (Savage 1954), утверждает Бинмор (Binmore 2009), байесовские принципы удовлетворительны только в качестве принципов рациональности как таковой для т.н. «малых миров», то есть в средах, где распределение рисков исчисляется для массива известных и конечных параметров, подобно игре на переправу из раздела 3. В больших мирах, где функции полезности, наборы стратегий и информационная структура с трудом поддаются оценке и меняются под воздействием случайных экзогенных сил, идея, что правило Байеса сообщает игрокам, как им «быть рациональными», крайне неправдоподобна. Но зачем тогда нам вообще считать, что игроки будут выбирать стратегии РН, SPE или последовательного равновесия?
Как подчеркивают и Бинмор (Binmore 2009), и Гинтис (Gintis 2009a), если применять теорию игр для моделирования действительного, естественного поведения вне условий малого мира, которыми обычно оперируют микроэкономисты (но не макроэкономисты, политологи, социологи или философы науки), тогда нам необходимо как-то описать, в чем именно состоит привлекательность равновесий, которые анализ порой не может даже идентифицировать, нивелировав всякую неопределенность, чтобы представить ее в качестве чистого риска. Сошлемся вновь на волновавшую Льюиса тему и скажем, что когда человеческий язык развивался, не было никакого внешнего судьи, который заботился бы об эффективности по Парето и ее обеспечивал, создавая фокальные точки для координации. Тем не менее каким-то образом люди в лингвистических сообществах смогли договориться использовать примерно одни и те же слова и конструкции, чтобы говорить одно и то же. Кажется маловероятным, что в этих процессах сыграла роль чья-то эксплицитная, продуманная стратегия. Тем не менее теория игр оказалась способна дать нам фундаментальные понятия для понимания стабилизации языков. Этот факт подкрепляет оптимизм Гинтиса относительно области применения теории игр. Чтобы понять его, нам следует обратиться к эволюционным играм.
Теория игр была плодотворно применялась в эволюционной биологии, где виды и/или гены рассматриваются как игроки, со времени выхода новаторской работы Мейнарда Смита (Maynard Smith 1982) и его коллег. Эволюционная (или динамическая) теория игр сейчас — значительное математическое расширение, применимое ко многим, не только биологическим, ситуациям. Брайан Скирмс (Skyrms 1996) использует эволюционную теорию игр, чтобы ответить на вопросы, которые Льюис не мог даже задать: об условиях, при которых могли бы возникнуть язык, понятие справедливости, понятие частной собственности и другие не-искусственные (non-designed), общие феномены, интересующие философов. Новизна эволюционной теории игр в том, что ходы не выбираются агентами свободно. Вместо этого агенты обычно жестко запрограммированы на исполнение определенных стратегий. А успех стратегии, взятой в некоторой «популяции стратегий», где каждая из стратегий распределяется с некоторой частотой, определяется количеством ее копий, которые она оставит в игре последующих поколений. При таких условиях сами стратегии становятся игроками, а индивиды, реализующие их, являются просто исполнителями, на плечи которых, с одной стороны, ложатся краткосрочные затраты, а с другой, выпадают краткосрочные выигрыши конкретных результатов.
Тут мы будем следовать в фарватере Скирмса. Для начала введем динамику репликатора. Давайте рассмотрим, как естественный отбор влияет на судьбы видов, изменяя, создавая и уничтожая их. Основным механизмом является дифференциальная воспроизведение. Любое животное с наследуемыми особенностями, которые увеличивают ожидаемое число потомков в определенных условиях, будет оставлять больше потомства, чем другие, пока эти условия остаются относительно стабильными. Его потомки же будут с большей вероятностью наследовать рассматриваемые признаки. Следовательно, доля этих признаков в популяции будет постепенно возрастать по мере смены поколений. Некоторые из них могут закрепиться, то есть в итоге охватить всю популяцию (до тех пор, пока окружающая среда не изменится).
Где здесь вступает теория игр? Часто одним из наиболее важных аспектов окружающей среды для организма являются тенденции в поведении других организмов. Мы можем считать, что каждая родословная «пытается» максимизировать свою репродуктивную приспособленность (= ожидаемое количество внуков), ища стратегию, которая была бы оптимальной с учетом стратегий других линий. Таким образом, эволюционная теория является еще одной областью применения непараметрического анализа.
В эволюционной теории игр мы больше не считаем, что индивиды выбирают стратегии по мере перехода от одной игры к другой. Причина в том, что наш интерес состоит в другом. Здесь мы менее озабочены поиском равновесий для одиночных игр — нас интересует то, какие равновесия стабильны и как они меняются со временем. Поэтому сейчас мы моделируем сами стратегии как играющие против друг друга. Стратегия считается «лучше» другой, если она с большей вероятностью оставит больше копий себя в следующем поколении, которое вновь сыграет в ту же игру. Мы изучаем то, как изменяется распределение стратегий по популяции по мере того, как развертывается цепочка игр.
Для эволюционной теории игр мы введем новую концепцию равновесия, предложенную Мейнардом Смитом (Maynard Smith 1982). Набор стратегий, взятый в определенной пропорции (например, 1/3:2/3, 1/2:1/2, 1/9:8/9, 1/3:1/3:1/6:1/6 — всегда в сумме 1) находится в равновесии ESS (Evolutionary Stable Strategy, эволюционно стабильной стратегии) только в том случае, если: (1) никто из разыгрывающих стратегию не может улучшить свою репродуктивную приспособленность, переключившись на любую из других стратегий в наборе, и (2) ни один из мутантов, разыгрывающий иную стратегию (т.е. «инвазивный»), не может закрепиться в популяции.
Принципы эволюционной теории игр лучше всего объясняются на примерах. Скирмс начинает с изучения условий, при которых может возникнуть чувство справедливости — понимаемое в данном случае как склонность рассматривать равное разделение ресурсов как честное, если соображения эффективности не предполагают в особых случаях иного. Он предлагает нам рассмотреть популяцию, в которой индивиды регулярно встречаются друг с другом и должны торговаться за ресурсы. Начнем с трех типов индивидов:
а) Справедливые всегда требуют ровно половину ресурса;
б) Жадины всегда требуют больше половины ресурсов. Когда один жадина встречает другого, они теряют ресурс в борьбе за него;
в) Скромники всегда требуют меньше половины. Когда скромник сталкивается с другим скромником, каждый берет меньшую долю от доступного ресурса и потому часть теряется.
Каждая одиночная встреча, где общая сумма требований составляет 100%, является РН этой отдельной игры. Точно так же может существовать множество динамических равновесий. Предположим, что жадные требуют 2/3 ресурса, а скромные — 1/3. Тогда следующие две пропорции являются ESS:
1) Половина популяции жадины, а половина — скромники. Мы можем рассчитать здесь средний выигрыш. Скромник получает 1/3 ресурса в каждой встрече. Жадина получает 2/3, когда он встречает скромника, и не получает ничего, когда встречает другого жадину. Таким образом, его средний выигрыш также составляет 1/3. Это ЭСС, потому что инвазия справедливого невозможна. Когда справедливый встречается со скромником, он получает 1/2. Когда справедливый встречает жадину, он ничего не получает. Таким образом, его средний выигрыш составляет всего 1/4. У скромников и жадин нет стимулов к изменению стратегии. Мутанту-справедливому, появившемуся в популяции, будет хуже всего, и потому естественный отбор не будет поощрять распространение таких мутантов.
2) Все игроки — справедливые. Каждый всегда получает половину ресурса, и никто не может преуспеть больше, переключившись на другую стратегию. Жадины, попав в эту популяцию, встречаются со справедливыми и получают средний выигрыш 0. Скромники по-прежнему получают 1/3, но это меньше, чем выигрыш справедливого.
Обратите внимание, что равновесие (1) неэффективно, поскольку средний выигрыш по всей популяции меньше. Однако в той же мере, в которой неэффективные результаты могут быть РН статических игр, они могут являться и ЭСС игр эволюционных.
Равновесия, где участвуют несколько стратегий, мы называем полиморфизмами. В общем случае, в игре Скирмса любой полиморфизм, в котором жадина требует x и скромник требует 1-x, является ESS. Вопрос, который интересует исследователя справедливости, касается относительной вероятности возникновения этих различных равновесий.
Это зависит от пропорций стратегий в исходной популяции. Если в стартовой популяции больше одного справедливого, то есть некоторая вероятность того, что справедливые столкнутся друг с другом и получат максимально возможный средний выигрыш. Скромники сами по себе не препятствуют распространению справедливых, это делают только жадины. Но жизнеспособность самих жадин зависит от того, есть ли вокруг скромники. Таким образом, чем больше в популяции справедливых по сравнению с парами жадина-скромник, тем лучше в среднем положение справедливых. Это подразумевает пороговый эффект. Если доля справедливых опустится ниже 33%, то их доля уже неминуемо опустится до нуля, потому что они будут недостаточно часто встречаться друг с другом. Если популяция справедливых поднимется выше 33%, то тенденция будет состоять в подъеме их числа до уровня закрепления, потому что дополнительный выигрыш от встречи друг с другом компенсирует их потери от встречи с жадиной. Это можно увидеть, заметив, что когда каждая стратегия используется 33% популяции, ожидаемый средний выигрыш для всех 1/3. Поэтому любое повышение сверх этого порога со стороны справедливых будет подталкивать их к закреплению.
Этот результат иллюстрирует вышесказанное и показывает, каким образом, учитывая некоторые относительно общие условия, справедливость, как мы ее определили, может возникнуть динамически. Другие хорошие новости для любителей справедливости появляются, если мы вводим коррелированную игру.
Модель, которую мы только что рассмотрели, предполагает, что стратегии не коррелированы, то есть вероятность того, что каждая стратегия встречается с любой другой стратегией, является простой функцией их относительных частотностей в популяции. Теперь рассмотрим, что происходит в нашей динамической игре с распределением ресурсов, когда мы вводим корреляцию. Предположим, что у справедливого есть небольшая способность узнавать и находить других справедливых в качестве партнеров по взаимодействию. В этом случае справедливые в среднем добиваются большего успеха, и это должно привести к снижению их порога для закрепления.
Тот, кто занимается моделированием эволюционных игр, исследует эффекты корреляции и других параметрических ограничений, прогоняя через компьютер огромные симуляции, где стратегии конкурируют друг с другом раунд за раундом в виртуальной среде. Стартовые пропорции стратегий и любые степени корреляции просто задаются в программе. Затем вы просто следите, как разворачивается динамика процесса во времени и измеряете временные отрезки, в течение которых она остается в любом из равновесий. Эти пропорции представлены относительными размерами бассейнов (или областей) притяжения (basins of attraction) для различных возможных равновесий. Равновесия — это точки притяжения в динамическом пространстве; бассейном притяжения для каждой такой точки является множество точек в пространстве, из которых популяция будет сходиться к рассматриваемому равновесию.
Введя корреляцию в свою модель, Скирмс сначала устанавливает крайне малую степень корреляции — 0,1. Это вынуждает область притяжения для равновесия (i) сократиться наполовину. Когда степень корреляции 0,2, полиморфическая область сокращается до точки, в которой популяция начинает в полиморфизме. Таким образом, очень небольшое увеличение корреляции приводит к пропорционально большому увеличению стабильности равновесия, при котором все разыгрывают справедливого. Небольшая корреляция является разумным предположением для большинства популяций, учитывая, что соседи склонны взаимодействовать друг с другом и подражать друг другу (или генетически, или из-за склонности копировать друг друга), и потому что генетически и культурно схожие животные с большей вероятностью будут жить в общей среде. Таким образом, если справедливость вообще может возникнуть, она будет иметь тенденцию быть доминирующей и стабильной.
Большая часть политической философии заключается в попытках выработать дедуктивные нормативные аргументы, призванные убедить несправедливых агентов в том, что у них есть основания поступать справедливо. Анализ Скирмса предлагает совершенно иной подход. Справедливый будет преуспевать лучше прочих в динамической игре, если будет предпринимать активные шаги для сохранения корреляции. Следовательно, эволюция способствует моральному одобрению справедливости, так и созданию справедливых институтов. Большинство людей думают, что делить «50 на 50» «справедливо» и заслуживает поддержки моральными и институциональными наградами и санкциями, поскольку мы являемся продуктами динамической игры, поощрявшей нашу склонность так думать.
Тема, привлекавшая наибольшее внимание у теоретиков эволюционных игр, — это альтруизм, определяемый как любое поведение организма, которое снижает уровень его собственной ожидаемой приспособленности в отдельно взятом взаимодействии, но увеличивает уровень приспособленности его партнера по взаимодействую. Альтруизм можно назвать довольно распространенным в природе явлением. Однако как он может возникнуть в условиях дарвиновского отбора?
Скирмс исследует этот вопрос, используя в качестве примера динамическую дилемму заключенного. Это просто серия игр ДЗ, разыгрываемых в популяции, некоторые члены которой являются отступниками, а некоторые наоборот, кооператорами. Выигрыши, как всегда в эволюционных играх, измеряются с точки зрения ожидаемого количества экземпляров каждой стратегии в будущих поколениях.
Пусть U(A) — средняя приспособленность стратегии A в популяции. Пусть U — средняя приспособленность всей популяции. Тогда доля стратегии А в следующем поколении это просто отношение U(A)/U. Поэтому, если А имеет большую приспособленность, чем в среднем для популяции, то А возрастает. Если А имеет меньшую приспособленность, чем средняя по популяции, то А уменьшается.
В динамической ДЗ, где взаимодействие случайно (т.е. в отсутствие корреляции), отступники успешнее, чем в среднем по популяции, если в ней есть кооператоры. Это следует из того, что, как мы видели в разделе 2.4, отступничество всегда является доминирующей стратегией в однократной игре. Таким образом, 100%-е отступничество — это ЭСС в динамической игре без корреляции, соответствующее РН в однократной статической ДЗ.
Однако добавление возможности корреляции радикально меняет эту картину. Теперь нам нужно вычислять среднюю приспособленность стратегии, учитывая вероятность ее встречи с каждой из возможных стратегий. В эволюционной ДЗ кооператоры, для которых вероятность встретить других кооператоров высока, успешнее отступников, вероятность которых встретиться с другими отступниками высока. Таким образом, корреляция способствует сотрудничеству.
Чтобы сказать что-то более точное об этой связи между корреляцией и сотрудничеством (и чтобы связать эволюционную теорию игр с вопросами теории принятия решений, но это уже выходит за рамки данной статьи), Скирмс представляет новое техническое понятие. Он называет стратегию адаптивно принимаемой, если вокруг ее точки закрепления в динамическом пространстве есть область, такая что из любой точки этой области она будет идти к закреплению. В эволюционной ДЗ как отступничество, так и сотрудничество адаптивно принимаемы. Относительные размеры бассейнов притяжения очень чувствительны к конкретным механизмам, благодаря которым достигается корреляция. Чтобы проиллюстрировать этот момент, Скирмс приводит несколько примеров.
Одна из моделей Скирмса вводит корреляцию с помощью фильтра на составление пар для взаимодействия. Предположим, что в первом раунде динамической ДЗ индивидуумы изучают друг друга и взаимодействуют или нет, в зависимости от того, что узнают о партнере. Во втором и последующих раундах все те, кто не образовали пар в первом раунде, объединяются в пары случайным образом. В этой игре бассейн притяжения для отступников больше, только если в первом раунде не окажется большой доли кооператоров. В этом случае отступники не получат пару в раунде 1, а затем образуют пары в основном друг с другом в раунде 2 и приводят друг друга к исчезновению.
Эта модель более интересна, поскольку ее механизм менее искусствен и не позволяет людям выбирать себе партнеров, но требует от них взаимодействия с теми, кто находится ближе к ним.
Из-за генетической связи (или культурного обучения через копирование) люди с большей вероятностью будут похожи на своих соседей. Если эта (конечная) популяция выстраивается в одном измерении (например, вдоль линии), а кооператоры и отступники располагаются вдоль него случайным образом, то мы получаем следующую динамику. Изолированные кооператоры имеют более низкую ожидаемую приспособленность, чем окружающие их отступники, и локально доводятся до вымирания. Члены групп из двух кооператоров имеют 50% вероятность взаимодействия друг с другом и 50% вероятность (для каждого) взаимодействия с отступником. В результате их средняя ожидаемая приспособленность также остается ниже, чем у их соседей-отступников, и они также сталкиваются с вероятным вымиранием. Группы из трех кооператоров оказываются в нестабильной точке, из которой одинаково вероятны как вымирание, так и экспансия. Однако в группах из четырех или более кооператоров гарантируется хотя бы одна встреча кооператора с кооператором, которого достаточно по крайней мере для замены исходной группы. В этом случае кооператоры как группа успешнее, чем окружающие отступники, и увеличиваются за их счет. В конце концов, кооператоры почти придут к закреплению — но не совсем. Отдельные перебежчики на периферии популяции будут «питаться» крайними кооператорами и выживут в качестве небольших «криминальных сообществ». Таким образом, мы видим, что альтруизм может не только поддерживаться динамикой эволюционных игр, но может даже распространяться при корреляции и колонизировать первоначально не альтруистические популяции.
Дарвинистская динамика, таким образом, приносит довольно хорошие новости для кооперации. Следует обратить внимание, однако, на то, что это выполняется только до тех пор, пока индивиды «намертво» запрограммированы природой или культурой и не могут переоценивать полезность для себя. Если наши агенты становятся слишком умными и гибкими, они могут заметить, что они разыгрывают ДЗ и каждый только выиграет от отступничества. В этом случае они в конечном итоге будут обречены на исчезновение — если только они не разработают стабильные и эффективные моральные нормы, способствующие укреплению сотрудничества. Но ведь это именно то, чего мы ожидаем от популяций животных, средний уровень приспособленности которых тесно связан с их способностью к успешному социальному сотрудничеству. Даже так эти популяции вымрут, если они не задумаются о будущих поколениях. Но разумной причины заботиться о будущих поколениях, если каждое новое поколение полностью заменяет предыдущее, для агентов нет. По этой причине экономисты используют модели «перекрывающихся поколений» при моделировании игр с распределением. Индивиды поколения 1, которые продержатся до поколения 5, будут экономить ресурсы для индивидов поколения 3, чтобы с ними кооперироваться; к поколению 3 новые индивиды будут заботиться о поколении 6; и так далее.
Гинтис (Gintis 2009) утверждает, что, если мы намереваемся использовать эволюционную теорию игр для унификации наук о поведении вообще, нам следует начать с использования ее для унификации самой теории игр. Мы отметили ранее в настоящей статье, что РН и ИРП являются проблематичными концепциями решения во многих случаях, где отсутствуют эксплицитные институциональные правила, поскольку что у агентов есть стимулы играть РН или ИРП только в той степени, в какой они уверены, что другие будут поступать аналогичным образом. В той степени, в которой у агентов нет такой уверенности — и это, кстати, возможно понять именно благодаря теории игр — следует ожидать всеобщего беспорядка и смуты. Гинтис детально описывает, что ключом к этой проблеме является существование того, что он называет «хореографом». Так он обозначает экзогенный элемент, информирующий агентов, каких стратегий равновесия им следует ожидать от других игроков. Как обсуждалось в разделе 5, культурные нормы, по-видимому, являются наиболее важными хореографами для людей. Интересные функции полезности, включающие нормы соответствующего типа, были всесторонне изучены Бикьери (Bicchieri 2006). В данном контексте Гинтис демонстрирует еще один объединяющий элемент, имеющий большое значение: если агенты приписывают положительную полезность следованию предложениям хореографа (т. е. стратегической корреляции с другими ради самой этой корреляции), тогда везде, где соперничество потенциальных выигрышей не подавляют этот стимул, можно ожидать, что агенты также будут последовательно оценивать байесовские приоритеты и, таким образом, достигать равновесия в убеждениях, как описано в разделе 3.1, в играх с несовершенной информацией.
В свете этого, когда мы задаемся вопросом о ценности применения теоретико-игровых моделей к поведению людей вне хорошо структурированных рынков, многое зависит от того, что мы считаем правдоподобными и эмпирически подтвержденными источниками стимулов для координации людей друг с другом. Недавно этот вопрос стал предметом широких дебатов, которые мы рассмотрим ниже в разделе 8.3.
Теория игр и поведенческие данные
В предыдущих разделах мы проанализировали проблемы, возникающие при рассмотрении классической (неэволюционной) теории игр как нормативной теории, которая говорит людям, что они должны делать, если хотят быть рациональными в стратегических ситуациях. Трудность, как мы увидели, состоит в том, что, похоже, нет ни одной концепции решения, которую мы могли бы единогласно рекомендовать для всех ситуаций, особенно когда в распоряжении агентов есть частная информация. Однако в предыдущем разделе мы показали, как обращение к эволюционным основаниям проливает свет на условия, при которых функции полезности, которые были эксплицитно разработаны, могут правдоподобно применяться к группам людей, приводя к теоретико-игровым моделям с правдоподобными и стабильными решениями. Однако до сих пор мы не рассматривали какие-либо действительные эмпирические данные наблюдений или экспериментов. Действительно ли теория игр помогла эмпирическим исследователям сделать новые открытия о поведении (человеческом или ином)? Если да, то в чем вообще состоит содержание этих открытий?
При ответе на эти вопросы мы тут же встречаем эпистемологическую проблему. Нет никакого способа применить теорию игры «саму по себе», в отрыве от других технологий моделирования. Используя терминологический стандарт философии науки, можно проверить теоретико-игровую модель феномена только в тандеме со «вспомогательными предположениями» о рассматриваемом феномене. По меньшей мере, это так, если мы строго рассматриваем теорию игр как математику без собственного эмпирического содержания. В некотором смысле, теорию без эмпирического содержания вообще невозможно проверить; можно только задаваться вопросом о том, являются ли аксиомы, на которых зиждется теория, взаимно согласованными. Тем не менее математическую теорию можно оценить применительно к эмпирической полезности. Одно из философских критических возражений, использовавшихся против теории игр, понимаемой как математический инструмент для моделирования поведенческих феноменов, гласит, что применение теории игр зачастую или всегда требует обращения к ложным, вводящим в заблуждение или неадекватно упрощенным предположениям об этих феноменах. Нам кажется, что эта критика имеет разную силу в разных контекстах в силу изменения дополнительных предположений.
Так, собственно, и выходит. Нет никакой интересной области, в которой применимость теории игр была бы совершенно бесспорной. Тем не менее консенсус относительно того, как использовать теорию игр (как классическую, так и эволюционную) в целом достигается намного легче, когда она служит инструментом для понимания поведения животных, нежели когда она употребляется для объяснения и предсказания стратегического поведения людей. Рассмотрим вкратце философские и методологические вопросы, которые возникли вокруг применения теории игр в биологии, прежде чем уделить более пристальное внимание теоретико-игровым социальным наукам.
Наименее спорное теоретико-игровое моделирование применяет классическую форму теории для рассмотрения стратегий, с помощью которых животные стремятся заполучить базовый ресурс, важный для их эволюционной борьбы: возможность произвести способное к репродукции потомство. Чтобы таким образом максимизировать свою ожидаемую приспособленность, животные должны найти оптимальные компромиссы между различными промежуточными благами, такими как питание, безопасность от хищников и способность преуспеть в брачной конкуренции. Эффективные точки компромиссов между этими благами часто могут быть оценены для конкретных видов в конкретных экосистемах, и с опорой на эти оценки можно вывести как параметрические, так и непараметрические равновесия. Модели такого рода имеют впечатляющий перечень достижений в прогнозировании и объяснении независимых эмпирических данных о таких стратегических феноменах, как конкурентный поиск пищи, выбор партнера, непотизм, соперничество отпрысков, стадность, групповая борьба с хищниками и коммуникации, взаимный уход и межвидовое сотрудничество (симбиоз). (Примеры см. в работах Krebs and Davies 1984, Bell 1991, Dugatkin and Reeve 1998, Dukas 1998 и Noe, van Hoof and Hammerstein 2001.) С другой стороны, как заметил Гаммерштейн (Hammerstein 2003), реципрокность [взаимность], а также ее эксплуатация и метаэксплуатация встречаются у социальных животных гораздо реже, чем этого можно было бы ожидать, опираясь на теоретико-игровое моделирование. Гаммерштейн, в частности, предположил, что это вызвано тем, что животные обычно имеют меньше возможностей ограничивать своих партнеров по взаимодействию, чем люди. Наша дискуссия в предыдущем разделе о важности корреляции для стабилизации игровых решений теоретически поддерживает это предположение.
Почему классическая теория игр позволила предсказывать поведение отличных от человека животных более непосредственно, чем для большей части человеческого поведения?
Предполагается, что дело в разных уровнях сложности среди отношений между дополнительными предположениями и явлениями. Росс (Ross 2005a) говорит следующее. Задачи максимизации полезности и максимизации приспособленности относятся к области экономики.
Экономическая теория отождествляет максимизирующие единицы — экономических агентов — с неизменными областями предпочтений. Отождествление всех биологических индивидов с подобными агентами тем более правдоподобна, чем менее развиты у агента когнитивные способности. Так, насекомые (например) особенно подходят для применения теории выявленных предпочтений (см. раздел 2.1).
Однако по мере усложнения нервной системы мы сталкиваемся с обучаемыми животными. Обучение может вызвать перманентную модификацию поведенческих паттернов животных, причем до той степени, что мы уже сможем продолжать отождествлять меняющегося биологического индивида с одним агентом лишь ценой объяснительной пустоты (поскольку приписывание функций полезности становятся все более ad hoc).
Кроме того, возрастающая сложность искажает простое моделирование во втором измерении: когнитивно сложные животные не только изменяют свои предпочтения с течением времени, но и подчиняются распределенным контрольным процессам, которые делают их площадками соперничества внутренних агентов (Schelling 1980; Ainslie 1992, Ainslie 2001). Так что они не являются экономическими агентами в прямом смысле этого слова, даже в определенный момент времени.
Когда мы беремся моделировать поведение людей с опорой на любую часть экономической теории, в том числе теорию игр, мы должны признать, что отношение между человеком и экономическим агентом, которую мы проводим для целей моделирования, всегда будет сложнее простого тождества.
Нет такого рубежа, при пересечении которого животное мгновенно становится слишком когнитивно сложным, чтобы быть моделируемым в качестве одного экономического агента, и для всех животных (включая людей) существуют контексты, в которых мы можем с пользой игнорировать синхронное измерение сложности.
Однако мы сталкиваемся с фазовым переходом в моделировании динамики, когда переходим от асоциальных к не-эусоциальным общественным животным. (Это социальные животные, но не такие, как муравьи, пчелы, осы, термиты и голые землекопы, кооперация которых обусловлена фундаментальными изменениями в их популяционной генетике, которые делают индивидуумов внутри групп подобными клонам. Известными примерами не-эусоциальных общественных животных являются попугаи, вороны, летучие мыши, крысы, собаки, гиены, свиньи, еноты, выдры, слоны, киты и приматы.) У них стабилизация динамики внутреннего контроля частично происходит вне индивидов, на уровне групповой динамики. С этими существами моделирование индивида как экономического агента с помощью одной функции совокупной полезности является крайней идеализацией, которую можно проводить только с величайшей методологической осторожностью и вниманием к специфическим контекстуальным факторам данной процедуры моделирования. Приложения теории игр здесь могут быть эмпирически адекватными только в том случае, если эмпирически адекватно экономическое моделирование.
Homo sapiens — экстремальный случай в этом отношении. Отдельные люди социально контролируемы в степени, недоступной для всех других не-эусоциальных видов. В то же время, их значительная когнитивная пластичность позволяет им значительно отличаться от культуры к культуре. Таким образом, люди являются наименее простыми экономическими агентами среди всех организмов. (Следовательно, можно сказать с некоторой долей иронии, что именно людей изначально взяли и продолжали использовать на протяжении многих лет в качестве наглядных примеров экономической агентности.) Ниже мы рассмотрим последствия этого для применения теории игр.
Однако вначале необходимо сделать ряд замечаний по поводу эмпирической адекватности эволюционной теории игры в объяснении и прогнозировании распределения стратегических диспозиций в популяциях агентов.
Такое моделирование применяется как к животным, так и к продуктам естественного отбора (Hofbauer and Sigmund 1998), а также к не-эусоциальным общественным животным (но особенно к людям), как к продуктам культурного отбора (Young 1998).
Существует два основных типа вспомогательных посылок, которые вам необходимо обосновать, в зависимости от конкретных обстоятельств, при построении подобных моделей.
Во-первых, необходимо иметь основания для уверенности в том, что диспозиции, которые вы хотите объяснить, являются адаптациями (биологическими или культурными, в зависимости от обстоятельств), — то есть диспозициями, которые были отобраны и закрепились благодаря тому, что способствовали собственной приспособленности или приспособленности более широкой системы, а не являлись лишь случайностями или структурно неизбежными побочными продуктами других адаптаций.
Во-вторых, вы должны смочь поместить всю модель в контекст обоснованного набора допущений о взаимосвязях между встроенными эволюционными процессами на различных временных масштабах. (Например, если биологическому виду присуща культурная динамика, то как медленная генетическая эволюция сдерживает быструю культурную эволюцию? Какова обратная связь культурной эволюции с генетической, если таковая вообще существует? В высшей степени ясно эти вопросы и дискуссия вокруг них разбирается в Sterelny 2003.)
Конфликтующие мнения относительно того, какие из этих допущений следует принять относительно эволюции человека, стимулируют сегодня крайне оживленные споры, сопровождающие моделирование поведенческих диспозиций и институтов в эволюционной теории игр. Именно здесь вопросы эволюционной теории игр встречаются с проблемами быстро развивающейся области экспериментальной поведенческой теории игр. Поэтому перед тем, как закончить с этой статьей, я опишу вторую область, чтобы дать представление об упомянутых спорах, составляющих ныне наиболее обсуждаемую область философских споров об основаниях теории игр и ее применении.
Теория игр в лаборатории
Экономисты проверяли теории, проводя лабораторные эксперименты с людьми и другими животными, начиная с новаторской работы Луи Терстоуна (Thurstone 1931). В последние десятилетия объем подобных работ стал поистине гигантским.
В большинстве из них субъекты помещаются в неидеально конкурентную микроэкономическую среду. Поскольку это именно те условия, в которых микроэкономика вырождается в теорию игр, большая часть экспериментальной экономики была экспериментальной теорией игр. Потому трудно отличить экспериментально мотивированные вопросы об эмпирической адекватности микроэкономической теории и вопросы об эмпирической адекватности теории игр.
Ограничимся здесь лишь поверхностным обзором обширной и сложной литературы. Отошлем читателей к выдающимся опросам, представлены в работах Kagel and Roth (1995), Camerer (2003), Samuelson (2005) и Guala (2005). Полезный высокоуровневый принцип сортировки литературы — соотнести ее с различными вспомогательными посылками, которыми сопровождается применение аксиом теории игр.
В популярных изложениях часто говорится (например, в Ormerod 1994), что экспериментальные данные в общем опровергают гипотезу, что люди являются рациональными экономическими агентами. Подобные утверждения слишком расплывчаты, чтобы быть устойчивой интерпретацией результатов. Все данные согласуются со взглядом, что люди приблизительно являются экономическими агентами, по крайней мере, на длинных временных отрезках, достаточных для теоретико-игрового анализа конкретных сценариев, в минимальном смысле, что их поведение может быть смоделировано совместимым с теорией выявленных предпочтений путем (RPT, см. раздел 2.1).
Однако эмпирические требования RPT столь невелики, что это не так уж и удивительно, как полагают многие неэкономисты (Ross 2005a). Что действительно является предметом дебатов вокруг общей интерпретации экспериментальных данных, так это вопрос о том, в какой степени люди являются максимизаторами ожидаемой полезности. Как мы видели в разделе 3, теория ожидаемой полезности (expected utility theory, EUT) обычно применяется в тандеме с теорией игр для моделирования ситуаций, связанных с неопределенностью, — то есть большинства ситуаций, представляющих интерес для наук о поведении.
Тем не менее множество альтернативных математических методов описания максимизации поддаются кардинализации полезности фон Неймана-Моргенштерна (VNM); а эмпирическую адекватность теории игр можно подставить под сомнение только в том случае, если мы полагаем, что поведение людей в общем не поддается описанию с помощью кардинальных функций определения полезности (VNMuf) при достаточно либеральной их интерпретации (т. е. в отличие от узкой интерпретации, в которой полезность VNM определена строго в терминах теории ожидаемой полезности).
То, что на самом деле показывает экспериментальная литература, так это то, что мир поведения очень «сумбурен» с точки зрения теоретика. Проблема сумбурности возникает из-за существенной гетерогенности как среди людей, так и среди векторов (личных, ситуации). Нет ни одной такой структурной функции полезности, где бы люди действовали ради максимизации функции этой структуры во всех обстоятельствах. Столкнувшись с хорошо изученными проблемами в контекстах, которые не выдвигают чрезмерных требований или которые очень хорошо институционально структурированы, люди часто ведут себя как максимизаторы полезности.
Общие обзоры теоретических вопросов и экспериментальных доказательств подготовили Смит (Smith 2008) и Бинмор (Binmore 2007). Широкий ряд примеров эмпирических исследований рассматривается в экспериментах т.н. «непрерывного двойного аукциона», которые обсуждали Плотт и Смит (Plott and Smith 1978 и Smith 1962, 1964, 1965, 1976, 1982).
В результате классическая теория игр может использоваться в таких областях для надежного прогнозирования поведения и в государственной деятельности, о чем свидетельствуют десятки чрезвычайно успешных государственных аукционов коммунальных и других активов, разработанные теоретиками игр для увеличения государственного дохода (Binmore and Klemperer 2002).
В других контекстах интерпретация поведения людей как в общем максимизирующего ожидаемую полезность требует неправомерного пренебрежения принципом простоты при построении теории. Мы получим наилучшее предсказание с использованием меньшего числа допущений, если предположим, что субъекты максимизируют полезность в соответствии с одной или — как правило — несколькими альтернативами (описывать которые мы не будем, поскольку они не имеют неопосредственного отношения к теории игр): версия теории перспектив (Канеман и Тверски 2014) или теория полезности альфа-ню (Chew и MacCrimmon 1979) или теория ожидаемой полезности с ранжированными вероятностями (Quiggin 1982, Yaari 1987). Харрисон и Рутстрем (Harrison and Rutstrom 2008) показывают, как создавать и кодировать модели максимально вероятного смешения (maximum likelihood mixture models), которые позволяют создателю эмпирических моделей применить ряд таких функций принятия решений к одному множеству данных о выборе. Полученный анализ определяет долю общей совокупности выборов, наилучшим образом объясняемой каждой моделью в смешении.
Этот подход шагнул наиболее далеко в работе Андерсена и др. (Andersen et al. 2014), где была показана эмпирическая ценность включения модели не максимизирующих скрытых психологических процессов смешения наряду с максимизацией экономических моделей.
Эффективная гибкость по отношению к моделированию решений, которая может быть реализована эмпирически, почти что снимает необходимость внесения поправок в саму структуру теории игр. Таким образом, это хорошо согласуется с интерпретацией теории игр как части математического инструментария ученого, изучающего проблемы поведения, а не как первоочередной эмпирической модели человеческой психологии.
Более серьезную угрозу полезности теории игр представляет систематическая полная перемена (reversal) предпочтений, как у людей, так и у других животных. Она серьезнее, поскольку не только выходит за рамки только случаев с людьми, но и бросает вызов теории выявленных предпочтений (RPT), а не просто чрезмерно жесткой приверженности EUT. Как мы объясняли в разделе 2.1, RPT, в отличие от EUT, входит в число аксиоматических основ теории игр, которые интерпретируются непсихологически. (Не все авторы согласны с тем, что очевидные феномены полной перемены предпочтений угрожают RPT, а не EUT; см. дискуссии в Camerer (1995), стр. 660–665, и Ross (2005), стр. 177-181).
Причиной для полной перемены предпочтений, распространенной среди животных с головным мозгом, является гиперболическое дисконтирование будущего (Strotz 1956, Ainslie 1992). Это явление, при котором агент обесценивает будущую награду в недалеком будущем сильнее, нежели в более отдаленном.
Нагляднее всего этот принцип иллюстрируется в сравнении с экспоненциальным дисконтированием большинства традиционных экономических моделей, где есть линейная зависимость между сроком до вознаграждения от точки отсчета и скоростью изменения ценности вознаграждения. На приведенном ниже рисунке показаны экспоненциальная и гиперболическая кривые для одного и того же интервала между точкой отсчета и будущим вознаграждением. Нижняя кривая соответствует гиперболической функции; резко вогнутая форма кривой — следствие изменения коэффициента дисконтирования.
Результатом этого является то, что, по мере того, как более поздние перспективы созревают до точки возможного потребления, люди и животные иногда будут расходовать ресурсы, отменяя последствия предыдущих действий, также стоивших им ресурсов. Например: выбирая сегодня между проверкой груды эссе первокурсников и просмотром бейсбольного матча, я откладываю проверку на потом, прекрасно зная, что могу упустить еще более интересную возможность, которая откроется завтра (состоится столь же увлекательный матч, или еще что-то получше). До сих пор это можно было бы описать, не жертвуя согласованностью предпочтений: если конец света может наступить сегодня с крошечной, но ненулевой вероятностью, то есть некоторый уровень неприятия риска, при котором я предпочел бы оставить рефераты непросмотренными. На приведенном ниже рисунке сравниваются две экспоненциальные кривые дисконтирования: нижняя — ценность игры, которую я смотрю до проверки эссе, и верхняя — более ценной игры, которой я буду наслаждаться после завершения работы. Обе кривых отражают возрастающую ценность по мере приближения к точке отсчета, но кривые не пересекаются, поэтому мои выявленные предпочтения согласованы во времени независимо от моего нетерпения.
Однако, если я свяжу своей прокрастинации руки, купив билет на завтрашний матч, чего я бы не сделал в отсутствие внушающей страх задачи по проверке эссе, тогда я нарушу межвременную согласованность предпочтений. Точнее, если бы я мог выбрать на прошлой неделе, стоит ли мне сегодня предаваться прокрастинации, я бы предпочел не делать этого. В этом случае моя кривая дисконтирования, проведенная из точки отсчета на прошлой неделе, пересекает кривую, выведенную из перспективы сегодняшнего дня, и мои предпочтения полностью меняются (reverse). На рисунке ниже показана такая ситуация.
Этот феномен усложняет применение классической теории игр к животным, обладающим интеллектом. Тем не менее он явно не уничтожает его совершенно, поскольку люди (и животные) часто не меняют своих предпочтений. (Если бы это было неверно, успешные аукционные модели и другие т.н. «механизмы» были бы крайне загадочны.) Интересно, что ведущие теории, направленные на объяснение причин, почему субъекты гиперболического дисконтирования часто ведут себя в соответствии с RPT, сами обращаются к принципам теории игр. Эйнсли (Ainslie 1992, 2001) описал народы как сообщества с внутренними торговыми интересами, в которых субъединицам, оперирующим краткосрочными, среднесрочными и долгосрочными доходами, приходится сталкиваться с конфликтами. Если они их не решают, вместо этого погружаясь в гоббсовское состояние (раздел 1), то внешние агенты, избежавшие гоббсовского исхода, могут полностью разрушить эти народы. Усстройство гоббсовского тирана недоступно для мозга. Поэтому его поведение (если ему удалось избежать помешательства на системном уровне) представляет собой последовательность самоусиливающихся равновесий того типа, который изучается в теоретико-игровой литературе об общественном выборе при коалиционных переговорах в демократических законодательных органах. То есть внутренняя политика мозга заключается в «торговле голосами» (logrolling) (Stratmann 1997). Эта внутренняя динамика затем частично регулируется и стабилизируется более широкими социальными играми со встроенными коалициями (люди как целое над темпоральными фрагментами их биографий) (Ross 2005: 334–353). (Например: социальные ожидания от чьей-то роли в качестве торговца устанавливают поведенческие равновесные цели для «торговли голосами» в мозге). Это потенциально добавляет соответствующие элементы в объяснение того, почему и как стабильные институты с относительно прозрачными правилами являются ключевым условием, которое помогает людям более точно воспроизводить поведение простых экономических агентов, так что классическая теория игр находит надежное применение к ним как целым единицам.
Здесь будет уместным сделать одно важное замечание для читателя. В литературе по наукам о поведении последнего времени считается само собой разумеющимся, что не согласованное во времени дисконтирование является для людей стандартным случаем.
Тем не менее Андерсен (Andersen et al. 2008) эмпирически показал, что это возникает вследствие
(i) допущения, что группы людей являются гомогенными, дисконтирующие поведение которых лучше всего описывают функциональные формы, и
(ii) неспособности независимо выявлять и контролировать отличия людей в их отвращении к риску при оценке их функций дисконтирования.
Для ряда изученных с учетом этого соображения популяций, данные свидетельствуют о том, что согласованное во времени дисконтирование описывает значительно более высокие пропорции выбора, чем несогласованные во времени выборы.
Таким образом, следует избегать чрезмерного обобщения моделей гиперболического дисконтирования.
Нейроэкономика и теория игр
Идея, что теория игр может быть также применена к внутренней динамике мозга, как было предложено в предыдущем разделе, получила развитие в виду независимых мотиваций в рамках исследовательской программы, известной как нейроэкономика (Montague и Berns 2002, Glimcher 2003, Ross 2005, Camerer, Loewenstein and Prelec 2005). Благодаря недавно появившимся неинвазивным технологиям сканирования мозга, в особенности функциональной магнитно-резонансной томографии (фМРТ), стало возможным изучать синаптическую активность работающего мозга, реагирующего на контролируемые сигналы. Это позволило открыть новый путь доступа — хотя все еще и весьма косвенного (Harrison и Ross 2010) — к вычислениям ожидаемой ценности вознаграждения в мозге, которые (естественно), как считается, играют ключевую роль в определении поведения. На основе экономической теории составляются производные функции, максимизируемые вычислениями этой ожидаемой ценности на синаптическом уровне; отсюда и название «нейроэкономика».
Теория игр занимает ведущую роль в нейроэкономике на двух уровнях. Во-первых, теория игр используется для прогнозирования вычислений, которые выполняют отдельные нейроны и группы нейронов, обслуживающих систему вознаграждения.
В наиболее распространенном примере Glimcher (2003) и его коллеги использовали фМРТ сканы обезьян, которых они обучили играть т.н. «инспекторские игры» против компьютеров. В инспекторской игре игрок сталкивается с серией выборов: либо работать за вознаграждение, и в этом случае он обязательно получит вознаграждение, либо выполнить другое, более легкое действие («увиливать»), и получить вознаграждение только в том случае, если другой игрок («инспектор») не следит за ним. Предположим, что поведение первого игрока («рабочего») демонстрирует функцию полезности, ограниченную на каждом конце следующим образом: он будет всегда работать, если инспектор всегда будет следить за ним, и он будет всегда увиливать, если инспектор никогда не будет за ним следить.
Инспектор предпочитает получать максимально возможный объем работы при минимально возможном уровне слежки. В этой игре единственное РН для обоих игроков находится в смешанных стратегиях, поскольку любая закономерность в стратегии одного игрока, обнаруженная другим игроком, может быть принята на вооружение. Для любой заданной пары конкретных функций полезности двух игроков, отвечающих описанным выше ограничениям, равновесной по Нэшу является любая пара стратегий, где в каждом испытании либо рабочему безразлично, работать или уклоняться, либо инспектору безразлично, следить или нет.
Применение анализа инспекторских игр для пар или групп агентов требует от нас, чтобы мы либо самостоятельно обосновали их функции полезности по всем переменным, имеющим отношение к их игре — и в этом случае мы можем определить РН, а затем проверить, успешно ли игроки максимизируют ожидаемую полезность; или предположили, что агенты максимизируют ожидаемую полезность или следуют какому-то другому правилу, например, функции подбора соответствия, — а затем вывели бы их функции полезности из их поведения. Любой подход может быть целесообразным в разных эмпирических контекстах.
Однако эпистемологическая сила значительно возрастает, если функция полезности инспектора определяется экзогенно, как это часто бывает. (Например, полиция, проводящая случайные проверки на дороге, чтобы поймать нетрезвых водителей, как правило, имеет целевое число пьяных водителей, оно им назначено «палочной системой», а бюджет на достижение цели установлен экзогенно. Это задает их функцию полезности с учетом распределения предпочтений и отношение к риску среди популяции водителей.) В случае экспериментов Глимчера инспектор — это компьютер, поэтому его программа находится под контролем и его сторона матрицы платежей известна. Единицы, отображающие ожидаемую полезность для испытуемых, — в данном случае — это порции фруктового сока для обезьян, — могут быть предварительно установлены в рамках параметрических тестов.
После этого с помощью компьютера, в который внесена экономическая модель обезьян, можно перерыть данные об их поведении в игровых условиях в поисках уязвимостей в их поведенческих паттернах, чтобы делать на них поправку в своей стратегии. Когда все переменные зафиксированы, может быть рассчитано ожидаемое от обезьян равновесное по Нэшу поведение, максимизирующее полезность — и испытано через манипулирование функцией полезности компьютера на разных прогонах игры.
Поведение обезьян после обучения очень надежно воспроизводит РН (как и поведение людей, играющих в подобные игры за денежные призы; Glimcher 2003: 307–308). Работая с обученными обезьянами, Глимчер и его коллеги смогли затем провести значимые эксперименты. Рабочее и увиливающее поведение обезьян было при помощи обучения связано со взглядом на правую или левую половину дисплея. В более ранних экспериментах Платт и Глимчер (Platt and Glimcher 1999) установили, что в параметрических настройках, поскольку вознаграждение варьировались от одного блока испытаний к другому, частота возбуждения каждого нейрона теменной доли, что контролирует движение глаз, может быть натренирована кодировать ожидаемую полезность каждого возможного движения для обезьяны по отношению к ожидаемой полезности альтернативного движения. Таким образом, «движения стоимостью 0,4 мл сока были представлены в два раза сильнее [в вероятностях возбуждения нейронов], чем движения стоимостью 0,2 мл сока» (Platt and Glimcher 1999: 314). Неудивительно, что, когда количество сока в вознаграждении за каждое движение варьировалось от одного испытания к другому, частота возбуждения нейронов также варьировалась.
На этом фоне Глимчер и его коллеги смогли изучить, как мозг обезьян реализовал процесс отслеживания РН. Когда обезьяны играли в инспекторскую игру против компьютера, цель, связанная с уклонением от работы, могла быть установлена в оптимальном месте с учетом предшествующего обучения для конкретного исследуемого нейрона, в то время как «рабочая» цель появлялась в нулевом местоположении. Это позволило Глимчеру проверить ответ на следующий вопрос: поддерживали ли обезьяны РН в игре, сохраняя частоту активности нейронов постоянной, в то время как фактическое и оптимальное поведение целой обезьяны изменялось? Данные достоверно дали положительный ответ. Глимчер разумным образом заключил, что эти данные как допускают, что частота активности нейронов, по крайней мере, в этой области коры для данной задачи, кодируют ожидаемую полезность как в параметрических, так и в непараметрических условиях. Здесь мы имеем очевидное оправдание эмпирической применимости классической теории игр в контексте, не зависящем от институтов или социальных конвенций.
Последующий анализ продвинул эту гипотезу еще дальше. Инспектору в компьютерной версии была представлена та же последовательность результатов, что получил и его оппонент-обезьяна в игре за день до того. Инспектору было предложено оценить относительную ожидаемую ценность действий, направленных на увиливание от работы и на ее выполнение, доступные на следующем ходу.
Глимчер сообщает о положительной корреляции между незначительными флуктуациями вокруг устойчивой равновесной по Нэшу активности нейрона и ожидаемой ценностью, которую получил компьютер, придерживавшийся того же нэшевского равновесия.
Глимчер комментирует этот вывод следующим образом:
Таким образом, мы видим, что теория игр выходит за рамки своей традиционной роли технологии описания высокоуровневых ограничений эволюционной динамики или поведения хорошо информированных агентов, работающих в рамках институциональных ограничений. В руках Глимчера она была использована для прямого моделирования активности в мозге обезьяны. Росс (Ross 2005a) утверждает, что группы нейронов, моделируемых таким образом, не следует отождествлять с суб-личностными игроками (game-playing units), которых описывает теория внутриличностных соглашений Эйнсли, упомянутая нами ранее; это предполагало бы прямую редукцию, которой опыт наук о поведении и биологии научил нас не ожидать. Эта проблема возникла в результате прямого диспута между нейроэкономистами по поводу соперничающих интерпретаций фМРТ-наблюдений межвременного выбора и дисконтирования (McClure et al. 2004, Glimcher et al. 2007). До сих пор все доказательства говорят в пользу того, что если иногда полезно анализировать делаемый людьми выбор как равновесие в играх между субличностными агентами, то такие субличностные агенты не должны отождествляться с отдельными областями мозга. Противоположная интерпретация, к сожалению, все еще крайне распространена в менее специализированной литературе.
Мы только что увидели первый уровень, на котором нейроэкономика применяет теорию игр. Второй уровень включает в себя поиск обусловленных переменных в активности нейронов, которые могут повлиять на выбор людьми стратегий, когда они играют в игры. Это, как правило, связано с многократным воспроизведением протоколов из литературы по поведенческой теории игр с испытуемыми, лежащими в фМРТ-сканерах во время игры. Харрисон (Harrison 2008) и Росс (Ross 2008b) скептически рассматривают ценность подобных исследований, которые включают в себя бездоказательные скачки в выводах, которые связывают наблюдаемое поведение со специфическими нейронными откликами. Также может быть поставлено под сомнение, много ли обобщаемых новых знаний может быть приобретено в той мере, в какой подобные ассоциации могут быть успешно идентифицированы.
Приведем пример такого рода «игры в сканере» — которая прямо предполагает стратегическое взаимодействие. Кинг-Касас и др. (King-Casas et al. 2005) взяли стандартный протокол из поведенческой теории игр, так называемой «игры на доверие», и применили его на субъектах, чей мозг был совместно просканирован с использованием технологии связывания функциональных карт соответствующих участков мозга, известной как «гиперсканирование».
Эта игра включает в себя двух игроков. В ее повторяющемся формате, который использовался в эксперименте Кинг-Касаса, первый игрок обозначается как «инвестор», а второй — как «доверенный». Инвестор начинает с 20 долларов США, из которых он может сохранить любую часть, а остаток инвестировать вместе с доверенным. В руках доверенного инвестированная сумма увеличивается экспериментатором втрое.
После этого доверенный может вернуть всю или часть этой прибыли инвестору, сколько он сочтет нужным. Процедура повторяется в течение десяти раундов, а идентичности игроков остаются анонимными друг для друга.
Эта игра имеет бесконечное множество РН. Предыдущие данные из поведенческой экономики согласуются с утверждением о том, что модальное нэшевское равновесие в игре людей аппроксимируется обоими игроками с использованием стратегии «зуб за зуб» (см. раздел 4), модифицируемой произвольными отступничествами для получения дополнительной информации и некоторым сотрудничеством после отступничества, доказывающим ограниченную допустимость подобных исследований. Это очень слабый результат, поскольку он совместим с широким спектром гипотез о том, какие именно варианты стратегий «зуб за зуб» используются и поддерживаются, и, таким образом, не дает никаких выводов о потенциальной динамике в разных условиях обучения, институтах или межкультурных обменах.
Когда эта игра проходила при гиперсканировании, исследователи интерпретировали свои наблюдения следующим образом. Считалось, что нейроны в хвостатом ядре головного мозга доверительного управляющего (считается, что там выполняются вычисления или отражаются активность дофаминергических систем среднего мозга) проявляют особо сильную реакцию, когда инвесторы доброжелательно отвечают взаимным доверием — то есть откликаются на отступничество повышенной щедростью.
По ходу игры эти реакции, как предполагалось, сменились с реактивных на антиципаторные, т.е. предвосхищающие. Таким образом, репутационные профили, предсказанные классическими моделями теории игр, были обнаружены непосредственно в мозгу. Еще один результат, не предсказанный сугубо теоретическим моделированием, и для которого чисто поведенческие наблюдения не были достаточными для определенности, заключался в том, что реакция нейронов хвостатого ядра на недобросовестную взаимность, то есть пониженную щедрость в ответ на сотрудничество, была значительно меньше по амплитуде. Исследователи выдвинули гипотезу, что это механизм, с помощью которого мозг реализует модификацию «зуба за зуб», призванную не допустить, чтобы случайные нарушения, предпринимаемые для прощупывания почвы, разрушили сотрудничество навсегда.
Прогресс в понимании, на который надеются специалисты, практикующие этот стиль нейроэкономики, заключается не в том, что он сообщает нам об определенных типах игр, а скорее в сравнении выводов, которые он обеспечивает, о том, как контекстуальное оформление влияет на предположения людей о том, в какие игры они играют. Утверждается, что фМРТ или другие виды исследования работающего мозга позволят нам количественно оценить степень стратегической неожиданности. Взаимодействующие ожидания стратегических сюрпризов могут сами подвергаться стратегическим манипуляциям, но данная идея только начала теоретически исследоваться (Ross and Dumouchel 2004). Мнение некоторых нейроэкономистов, что мы теперь имеем возможность эмпирически проверять такие новые теории, а не просто гипотетически моделировать их, стимулировала развитие этого направления исследований.
Теоретико-игровые модели человеческой природы
Разработки, рассмотренные в предыдущем разделе, подвели нас к подвижной границе экспериментального / поведенческого приложения классической теории игр. Теперь мы можем вернуться в точку ветвления, отложенную несколько абзацев назад, где этот поток исследований встречается с другим, исходящим из эволюционной теории игр. Нет серьезных сомнений в том, что по сравнению с другими не-эусоциальными животными — включая наших ближайших родственников, шимпанзе и бонобо, — люди достигают огромных успехов в координации (см. раздел 4) (Tomasello et al. 2004).
Оживленная полемика, имеющая важные философские следствия и обе стороны которой противостоят аргументам теории игр, сегодня развернулась по поводу того, можно ли эту способность исчерпывающим образом объяснить культурной адаптацией, или же лучше сослаться на генетические изменения, произошедшие на ранних стадиях эволюции Homo sapiens.
Хайнрих и соавторы (Henrich et al. 2004, 2005) провели серию экспериментальных игр с популяциями, отобранными из пятнадцати небольших обществ из Южной Америки, Африки и Азии, в том числе с тремя группами собирателей, шестью группами подсечно-огневых земледельцев, четырьмя группами кочевых пастухов и двумя группами мелких земледельцев.
В играх («Ультиматум», «Диктатор», «Общественные блага»), которые они использовали, все субъекты были помещены в ситуации, в целом напоминающие игру на доверие, описанную в предыдущем разделе. Игры «Ультиматум» и «Общественные блага» — это сценарии, в которых социальное благосостояние может быть максимизировано, а благосостояние каждого отдельного человека максимизировано (достигнута эффективность по Парето), если и только если по меньшей мере некоторые игроки используют стратегии, которые не являются идеальными стратегиями равновесия подыгр (см. раздел 2.6). В играх «Диктатор» узко эгоистичный игрок, делающий первый ход, захватил бы всю доступную прибыль. Таким образом, в каждом из трех типов игр игроки ИРП, которые заботились только об собственном денежном благополучии, получат результаты, которые будут включать в себя крайне неэгалитарные выплаты. Ни в одном из сообществ, изученных Хайнрихом (или в любом другом сообществе, в котором проводятся подобные игры), подобные результаты получены не были.
Игроки, чьи роли таковы, что они заберут все, кроме эластичности денежных прибылей (epsilon of the monetary profits), если они и их партнеры разыграют ИРП, всегда предлагали партнерам значительно больше, чем эластичность, и даже тогда партнеры иногда отказывались от таких предложений за счет неполучения денег. Кроме того, в отличие от традиционных субъектов экспериментальной экономики — студентов университетов промышленно развитых стран, — субъекты Хайнриха не играли даже стратегии равновесия Нэша в отношении денежных выплат. (То есть игроки, имевшие стратегическое преимущество, предлагали более крупные доли прибылей стратегически слабым, чем это было необходимо для того, чтобы обеспечить согласие с их предложениями.)
Хайнрих интерпретируют эти результаты, предполагая, что все реальные люди, в отличие от «рационального экономического человека», в определенной степени ценят эгалитарные результаты. Однако их эксперименты также показывают, что эта степень значительно варьируется в зависимости от культуры и коррелирует с вариациями двух конкретных культурных переменных: типичных платежей за кооперацию (степень, в которой экономическая жизнь в обществе зависит от сотрудничества с субъектами, не состоящие в прямом родстве) и совокупная интеграция на рынке (конструкт, составленный из независимо измеренных степеней социальной сложности, анонимности, конфиденциальности и размера поселений). По мере увеличения значений этих двух переменных поведение игры смещается (слабо) в направлении равновесия Нэша. Таким образом, исследователи заключают, что люди имеют генетическую предрасположенность предпочитать эгалитаризм, но что относительный вес этих предпочтений программируется процессами социального обучения, обусловленными местными культурными особенностями.
При оценке интерпретации Хенриха следует прежде всего отметить, что никакие аксиомы RPT или различные модели решения, упомянутые в разделе 8.1, применяемые совместно с теоретико-игровым моделированием к данным человеческого выбора, не указывают на и не предполагают свойство узкого эгоизма (См. Ross (2005a) ch. 4; Binmore (2005b) и (2009); и любой текст об экономике или теории игр, позволяющий математике говорить самой за себя и не настаивает на «вращении» его в одном идеологическом направлении или в другом.)
Ортодоксальная теория игр, таким образом, не предсказывает, что люди будут играть стратегии ИРП или РН, выведенные из признания монетарных выплат в качестве эквивалента полезности. Поэтому Бинмор (Binmore 2005b) имеет все основания к жесткой критике модной риторики Хенриха и его коллег, предположивших, что их эмпирическая работа ставит ортодоксальную теорию в неловкое положение. Это не так.
Это не означает, что антропологическая интерпретация эмпирических результатов должна восприниматься как бесспорная. Бинмор много лет (Binmore 1994, 1998, 2005a, 2005b) опирался на широкий набор поведенческих данных, согласно которым, когда люди играют не с родственниками, они склонны учиться разыгрывать нэшевское равновесие в отношении функций полезности, которые приблизительно соответствуют функциям дохода. Как он указывает в работе Binmore 2005b, данные Хенриха не проверяют эту гипотезу на его малочисленных сообществах, потому что испытуемые не были подвергнуты тестовым играм на (довольно долго, в случае игры «Ультиматум») период обучения, который, как предполагают теоретические и вычислительные модели, необходим, чтобы люди начали сходиться на РН. Когда люди играют в незнакомые игры, они склонны моделировать их, используя в качестве референции игры, к которым они привыкли в своем повседневном опыте. В частности, они, как правило, играют в однократные лабораторные игры, как если бы они были знакомы с многократными играми, поскольку однократные игры редко встречаются в обычной общественной жизни вне специальных институциональных контекстов. Многие из замечаний Хенриха согласуются с этой гипотезой относительно их субъектов, хотя они, тем не менее, эксплицитно отвергают саму гипотезу. Противоречие — если оставить в стороне вопросы об отношении к «ортодоксальной» теории — здесь в меньшей мере связано с действиями конкретных субъектов в этом эксперименте, чем с вопросом о том, что какие выводы о человеческой эволюции следует сделать из их поведения.
Гинтис (Gintis 2004, 2009) утверждает, что данные такого рода поддерживают следующую гипотезу об эволюции человека. Наши предки были чистыми максимизаторами индивидуальной приспособленности. Где-то по ходу эволюции они попадали в ситуации, когда достаточное их число максимизировало свою индивидуальную приспособленность максимизацией приспособленности их группы (Sober и Wilson 1998) — для того, чтобы генетическая модификация закрепилась в биологическом виде: мы разработали предпочтения не только к нашему собственному индивидуальному благосостоянию, но и к относительному благосостоянию всех членов сообщества, индексированных по социальным нормам, программируемым в каждом отдельном человеке посредством культурного обучения.
Таким образом, современному исследователю, применяющему теорию игр для моделирования социальной ситуации, следует раскрывать функции полезности своих субъектов посредством
(i) выяснения того, членами какого сообщества (или сообществ) они являются, а затем
(ii) выведения функций полезности, запрограммированных в членов этого сообщества (сообществ), изучая представителей каждого релевантного сообщества в целом ряде игр и предполагая, что результаты являются скоординированными равновесиями. Поскольку функции полезности являются здесь зависимыми переменными, игры должны быть детерминированы независимо. Обычно мы можем придерживаться, по крайней мере, стратегических форм соответствующих игр, полагает Гинтис, в силу (а) нашей уверенности в том, что при прочих равных люди предпочитают эгалитарные исходы неэгалитарным в рамках «инсайдерских групп», к которым они ощущают свою принадлежность, и (б) требования, чтобы игровые равновесия опирались на устойчивые аттракторы в правдоподобных эволюционных теоретико-игровых моделях исторической динамики культуры.
Требование (б) как ограничение теоретико-игрового моделирования общечеловеческих стратегических диспозиций уже не является сильно противоречивым — или, по крайней мере, не является более противоречивым, чем общий адаптационизм в эволюционной антропологии, одним из проявлений которого оно является. Однако некоторые комментаторы скептически относятся к предложению Гинтиса о существовании генетического разрыва в эволюции человеческой социальной жизни. (О когнитивно-эволюционной антропологии, которая экслицитно отрицает такой разрыв, см. Sterelny 2003.) Частично опираясь на такой скептицизм (но более непосредственно на поведенческие данные), Бинмор (Binmore 2005) выступает против моделирования людей как якобы имеющих встроенное предпочтение к эгалитаризму. Согласно модели Бинмора, основным классом стратегических проблем, стоящих перед не-эусоциальными общественными животными, являются координационные игры. Человеческие сообщества вырабатывают культурные нормы, чтобы выбирать равновесия в этих играх, и многие из этих равновесий будут совместимы с высокими степенями по-видимому альтруистического поведения в некоторых (но не во всех) играх.
Бинмор утверждает, что люди приспосабливают свои представления о справедливости к тому, что для их окружения было преобладающими правилами выбора равновесия. Однако, он считает, что динамическое развитие подобных норм должно быть в конечном итоге совместимо с договорным равновесием (bargaining equilibria) между отдельными эгоистичными индивидами.
Действительно, утверждает он, что, поскольку сообщества развивают институты, которые поощряют то, что Хенрих назвал совокупной интеграцией рынка (обсуждалось выше), их функции полезности и социальные нормы склонны сходиться на эгоистичной экономической рациональности по отношению к благосостоянию. Это не означает, что Бинмор пессимистично относится к перспективам эгалитаризма: он развивает модель, показывающую, что сообщества в широком смысле корыстных переговорщиков (self-interested bargainers) могут естественным образом вытянуться вдоль динамически стабильных равновесных путей к нормам распределения, соответствующим справедливости Ролза (Rawls 1971). Главные препятствия на пути такой эволюции, по словам Бинмора, — это именно те виды предпочтений заботы о других, которые ценят консерваторы, создавая тем самым препятствия к поиску более эгалитарных договорных равновесий, находящихся в пределах досягаемости по равновесным путям сообществ.
Для разрешения этого спора между Гинтисом и Бинмором, к счастью, не требуется дожидаться открытий о далеком прошлом человеческой эволюции, которых мы можем вообще не сделать. Модели делают конкурирующие эмпирические предсказания некоторых проверяемых феноменов. Если Гинтис прав, тогда существуют пределы, налагаемые разрывом в эволюции гоминидов, в той степени, в которой люди могут научиться себялюбию. В этом, собственно, и все значение обсуждаемых выше споров по поводу интерпретации Хенрихом данных его полевых исследований. Модель отбора социального равновесия Бинмора также зависит, в отличие от модели Гинтиса, от широко распространенных среди людей диспозиций к наказанию второго порядка членов общества, которые не санкционируют нарушителей социальных норм. Гинтис (Gintis 2005) показывает с использованием теоретико-игровой модели, что это неправдоподобно, если затраты на наказание значительны. Однако Росс (Ross 2008а) утверждает, что распространенное в литературе предположение о том, что наказание за нарушение нормы должно быть дорогостоящим, связано с неспособностью адекватно различать модели первоначальной эволюции социальности, с одной стороны, и модели поддержания и развития норм и институтов после того, как их первоначальный набор стабилизировался. Наконец, Росс также указывает, что цели Бинмора столь же нормативны, как и описательны: он стремится показать эгалитаристам, как диагностировать ошибки в консервативной рационализации статуса-кво, не призывая к революциям, которые ставят под угрозу стабильность равновесного пути (и, следовательно, общественного благосостояния). Это убедительный принцип формулировок реформаторских предложений — что они должны быть «с защитой от подлости» (как выразился Юм), то есть должны быть совместимы с меньшей степенью альтруизма, чем его может быть в действительности в людях. Таким образом, несмотря на то, что большинство исследователей, работающих над теоретико-игровыми основами социальной организации, в настоящее время, похоже, принимают сторону Гинтиса и других представителей команды Хенриха, альтернативная модель Бинмора имеет некоторые сильные аргументы в свою пользу. Это также еще одна проблема на переднем фланге приложения теории игр, ожидающая решения в ближайшие годы.
Глядя вперед: области современных инноваций
В 2016 году Journal of Economic Perspectives опубликовал материалы симпозиума «Что происходит в теории игр?». Каждый из участников независимо отмечал, что теория игр стала столь плотно связана с микроэкономической теорией в целом, что сам вопрос довольно сложно отличить от исследования переднего края целой субдисциплины, которая, в свою очередь, представляет собой крупнейшую часть экономической науки. Потому грань между философией теории игр и философией микроэкономики ныне в равной степени неразличима. Конечно, как уже подчеркивалось, теории игр применяется далеко за пределами традиционной экономики, во всех науках о поведении и социальных дисциплинах. Но поскольку методы теории игр слились с методами микроэкономики, это расширение применения теории игр можно равным образом рассматривать как экспорт микроэкономического инструментария.
После десятилетий развития, (не полностью) описанных в данной статье, последние годы в плане фундаментальных инноваций, которые могли бы интересовать философов, были относительно тихими. Однако некоторая часть исходных оснований пересматриваться заново.
Создание теории игр фон Нейманом и Моргенштерном (von Neumann and Morgenstern 1944) разделило само исследование на две части. Некооперативная теория игр анализирует кейсы, которые опираются на предположение о том, что каждый игрок максимизирует свою функцию полезности, при этом рассматривая ожидаемые стратегические ответы других игроков в качестве ограничений. Как говорились выше, игрой, фон Нейман и Моргенштерн применяли свои модели к покеру, который представляет собой игру с нулевой суммой.
Большая часть этой статьи фокусировалась на множестве теоретических вызовов и идеях, которые возникли, как только некооперативная теория игр была расширена за пределы области нулевой суммы. Но это было лишь половиной классического труда фон Неймана и Моргештерна. Вторая была посвящена разработке кооперативной теории игр, о которой тут еще ничего не было сказано.
Причина этого молчания состоит в том, что большинство специалистов в теории игр полагает, что кооперативная теория игр в лучшем случае лишь отвлекает внимание, а в худшем является технологией, путающей смысл теории игр, опуская тот аспект игр, который главным образом и делает их потенциально интересными и поучительными в прикладном отношении: речь идет о требовании, чтобы равновесия отбирались эндогенно под ограничением, введенным Нэшем (Nash 1950а). Это, в конце концов, и есть то, что делает равновесие само-осуществимым, точно таким же образом, как это происходит с ценами на конкурентном рынке, и таким образом делает их стабильными при отсутствии вмешательства извне. Нэш (Nash 1953) утверждал, что решения кооперативных игр должны быть верифицированы демонстрацией, что они также являются решениями формально эквивалентных некооперативных игр. Достижением Нэша в той работе была аналитическое определение соответствующей эквивалентности. Это можно было интерпретировать как демонстрацию полной несостоятельности кооперативной теории игр.
Кооперативная теория игр отталкивается от предположения, что игроки уже, каким-то неизвестным образом, договорились о стратегическом векторе и, таким образом, о результате игры. Потом аналитик применяет теорию, чтобы определить минимальный набор условий, при которых договоренность игроков остается стабильной. Эту идею обычно поясняют на примере парламентской коалиции. Предположим, что есть доминантная партия, которая должна вступить в коалицию для того, чтобы получить большинство голосов в парламенте для принятия закона. Для этого ей необходимо объединиться с рядом тех или иных групп других партий. Представим, чтобы сделать наш пример более структурированным и интересным, что некоторые партии не будут участвовать в коалиции, в которой состоят некоторые другие партии; так что проблема у создателей коалиции не только в том, чтобы просто суммировать потенциальные голоса. Теоретик кооперативных игр определяет набор возможных коалиций. Может статься, что будут и другие партии, участие которых в любой возможной коалиции строго необходимо. Определение таких партий, например, выявит ядро игры, элементы, которые присутствуют во всех равновесиях.
Ядро — это ключевая концепция решения в кооперативной теории игр, за которую Шепли получил свою часть Нобелевской премии. (Shapley 1953 — отличная статья по этой теме.) «Программа Нэша», по его собственному определению (Nash 1953), состояла в верификации определенного кооперативного равновесия путем демонстрации того, что некооперативные игроки могли бы прийти к нему путем инкрементальных торгов, которые он описал в другой статье (Nash 1950b), и все возможные результаты подобных торгов включали бы в себя это ядро.
В свете этого примера не так удивительно, что в годы, когда некооперативная теория игр еще продолжала развиваться, кооперативной теорией пользовались главным образом политологи. Ее также с пользой для себя применяли экономисты, занимавшиеся исследованиями соглашений между фирмами и профсоюзами, а также аналитики международных торговых переговоров. Мы можем проиллюстрировать ценность подобных приложений, приведя второй пример.
Предположим, что, учитывая вес внутреннего лобби в ЮАР, правительство ЮАР никогда не согласится на какое-либо торговое соглашение, которое не позволяет ему защитить свой сектор автомобильной промышленности. (Так, кстати, дела обстоят и по сей день.) Тогда допущение подобной защиты есть часть ядра любого торгового соглашения, которое любая страна или блок могла бы заключить с ЮАР.
Это знание поможет участникам переговоров избежать риторики или обязательств перед другими лоббистами, в какой бы они ни были стране, что сделают ядро недосягаемым для них и, таким образом, гарантирует провал переговоров. Этот пример также помогает нам продемонстрировать ограничения кооперативной теории игр. ЮАР будет вынуждена поступаться интересами других лобби, дабы защитить свою автомобильную промышленность. Что именно будет принесено в жертву, будет функцией партии в развернутой форме некооперативных последовательных предложений и контрпредложений, и южноафриканские переговорщики, если они проявят должную осмотрительность, должны будут внимательно следить за тем, какими именно внутренними интересами они жертвуют. Т.е. кооперативный анализ не избавляет их от необходимости также заниматься и некооперативным анализом. Их консультанты по теории игр могут с тем же успехом просто закодировать некооперативные параметры в свой Gambit, который будет выдавать ядро по запросу.
Но кооперативная теория игр не умерла и не осталась лишь прикладным инструментом для политологов. Выяснилось, что есть целый ряд проблем законодательного толка, в которых участвует множество игроков, чьи атрибуты отличаются, но ординальные функции полезности симметричны, для чего некооперативное моделирование, хотя в принципе и возможное, абсурдно громоздко и требует слишком больших вычислений, в то время как кооперативное моделирование подходит превосходно. То, что нам приходится иметь дело с ординальными функциями полезности, важно, поскольку на релевантных рынках зачастую нет цен. Классический пример (Gale and Shapley 1962) — рынок невест. Абстрагируясь от индивидуальных романтических драм и комедий, общество включает в себя огромное множество людей, которые хотят образовать пару и очень заботятся о том, с кем они в конце концов ее создадут.
Предположим, что у нас есть конечный набор таких людей. Представим, что сваха, или специальное приложение, сначала делит этот массив на два подмножества и оглашает правило, согласно которому каждый из множества А должен сделать предложение кому-то из множества Б. Каждый из множества Б знает, что он — первый выбор кого-то из множества А. Он делает свой первый выбор из всех полученных предложений и возвращает остальные обратно.
Члены множества А, чьи первые предложения не были приняты, теперь делают вторые предложения кому-то, кому они еще предложения не делали, хотя этим вторым может оказаться кто-то, кто уже имеет в своем распоряжении предложение из первого раунда — Нкоси знает, что Барбара предпочла Амалию в первом раунде, но Нкоси не был в числе первых сватов Барбары, поэтому может заменить Барбару во втором раунде. Вероятно, в этой игре есть терминальный раунд, после которого уже не будет новых предложений, а приложение-сваха найдет ядро кооперативной игры, поскольку ни один i из множества Б не предпочтет создать пару с кем-то из множества А, кто предпочитает i кому угодно из списка «невест» в А. Все из множества Б теперь примут то предложение, которое им поступило, и, если у обоих множеств была одинакова кардинальность и никто не предпочтет одиночество образованию пары, никто не останется одиноким.
Это не напрямую применимая модель рынка невест, поэтому денег на продаже столь простого приложения не заработать. Проблема в том, что у нас нет никаких гарантий того, что, например, Нкоси и Амалия не предназначены друг другу судьбой, но не могут образовать пару из-за того, что оказались в одном подмножестве. В учебниках по теории игр эту проблему обходят с помощью предположения, что во множестве А — мужчины, а в Б — женщины, и что все настолько гетеросексуальны, что предпочтут сформировать пару с кем-то противоположного пола, чем с кем-то одного с ними пола. С другой стороны, модель дает нам некоторую интуицию — как это обычно и делают модели, — если не пытаться понимать все чересчур буквально.
Поработав с ней, мы можем увидеть логику фактов об обществе, которую тому, кто разрабатывает подобное приложение, лучше бы понимать: приложению придется вести лог предложений, находящихся на рассмотрении, но не принятых, оставлять людей, чьи предложения рассматриваются, на рынке, и помнить о том, кто кому уже отказал (не создавая всеобщей эмоциональной катастрофы публикацией этой информации).
Настоящее приложение не сможет достоверно найти ядро кооперативной игры, если множество людей не будет мало, ограничено и распределится на подгруппы как минимум типа «Х-человек ищет Y-человека», где X и Y свойства, которые приоритетны для всех. (Такие свойства вообще есть, хотя бы в приближении?) Но реальные приложения для знакомств, кажется, работают достаточно хорошо, чтобы трансформировать способ, которым большинство молодых людей сегодня находят себе пару, как минимум в странах, где есть доступ в интернет. Отношения между теоретически идеализированными и реальными брачными рынками исчерпывающие рассматриваются в работе Chiaporri 2017.
Обновление интереса к кооперативной теории игр обусловлено проблемами, с которыми столкнулось законодательство, которые, в отличие от игрушечной иллюстрации с гетеросексуальным рынком невест, удовлетворяют ключевым посылкам модели. Самые яркие примеры — сведение абитуриентов и университетов, а также сведение с донорами людей, нуждающихся в донорском органе (см. Roth 2017). На этих рынках нет никакой амбивалентности в том, как именно выделять множества, которые необходимо свести. Тут релевантны ординальные предпочтения: университеты не раздают места наиболее щедрым покупателям (по крайней мере, большинство), а органы не выставляются на продажу (по крайней мере по закону). Модели имеют действительное применение и наглядно повысили эффективность соответствующих областей и спасли немало жизней.
В науке нередко встречаются модели, которые, оказавшись на практике крайне неуклюжими для решения своих оригинальных проблем, становятся источником крайне эффективных решений новых проблем, которые ставит перед нами технологический прогресс. Интернет создал среду для применения алгоритмов для сочетаний пар — путешественники и арендодатели, едоки и рестораны, студенты и тьюторы, и (к сожалению) социально отчужденные люди и распространители пропаганды и фанатизмов всех сортов — все это могло быть создано теоретиком в любое время после инноваций Шепли, но прежде на практике было невозможно. Подобные приложения кооперативной теории игр часто применяются вместе с некооперативной теорией игр для аукционов (Klemperer 2004), дабы создать рынки товаров и услуг настолько эффективные, чтобы уничтожить когда-то могущественные торговые центры даже в пригородах США. Почему отели намного более прибыльны и доступны для клиентов, чем когда бы то ни было, помимо больших городов, до 2007 года? Ответ кроется в том, что алгоритмы динамического ценообразования (Gershkov and Moldovanu 2014) совместили теорию парообразования и теорию аукционов, чтобы позволить отелям, взятым вместе с онлайновыми тревел-сервисами, найти клиентов, готовых платить премиальные цены за идеальное местоположение и время, а затем заполнить оставшееся номера охотниками за хорошей сделкой, чьи предпочтения намного гибче. Авиалинии используют ту же технологию.
Теория игр, таким образом, продолжает оставаться изобретением ХХ века, двигающим социальные революции XXI века, и Сэмуэльсон (Samuelson 2016) предсказывает грядущий всплеск нового интереса к математическим глубинам кооперативных игр и их отношениям с некооперативными играми.
Помимо всего упомянутого выше, к нынешнему дню был разработан огромный набор и других применений как классической, так и эволюционной теории игр. Но мы надеемся, что сказанного выше достаточно, чтобы убедить читателя в огромной и постоянно расширяющейся полезности этого аналитического инструмента. Читатель, желающий большего, уже достаточно ознакомлен с основоположениями, чтобы приступить к самостоятельной работе с обширной тематической литературой, часть которой представлена ниже.
Библиография
В этой части книги и статьи, которые никто, серьезно интересующийся теорией игр, не может позволить себе пропустить, помечены (**).
Наиболее доступный учебник, который описывает основные ответвления теории игр — Dixit, Skeath and Reiley (2014). Тому, для кого эта область совершенно в новинку, следует сначала проштудировать его, прежде чем переходить к чему-то еще.
У теории игр бесчисленное количество приложений, из которых в данной статье было упомянуто лишь несколько. Читатели, ищущие большего, но не желающие окунаться в математику, могут найти несколько хороших источников. Dixit and Nalebuff 1991 и Dixit and Nalebuff 2008 особенно сильны в том, что касается политических и социальных примеров. McMillan 1991 фокусируется на приложения теории для бизнеса.
Великий исторический прорыв, который официально дал начало теории игр — это работа фон Неймана и Моргенштерна (von Neumann and Morgenstern 1944), которую тем, кто питает исследовательский интерес к теории игр, следует прочесть наряду с классическими работами Джона Нэша (John Nash 1950a, 1950b, 1951). Крайне полезный сборник ключевых фундаментальных работ, все из которых являются классикой — Kuhn 1997. Для ознакомления с современной математической работой, которая при этом необычайно нагружена философски, следует прочесть Binmore 2005 (**), которую стоит выделить в отдельный класс. Вторая половина книги Kreps 1990 (**) — лучшая стартовая точка для изучения философских проблем, возникающих вокруг отбора равновесия для нормативистов. Кунс (Koons 1992) еще дальше углубляется в эти материи. Fudenberg and Tirole 1991 остается наиболее подробным и полным математическим текстом из существующих. Работа Гинтиса (Gintis 2009b) (**) содержит обсуждение интереснейших проблем, а также уникальна тем, что рассматривает эволюционную теорию игр в качестве базового фундамента теории игр вообще. Недавние разработки фундаментальной теории хорошо представлены в работе Бинмора, Кирмана и Тани (Binmore, Kirman, Tani 1993). Любой, кто хочет применять теорию игр к реальным ситуациям выбора, в которых оказываются люди, которые соотносятся стохастически, а не детерминистически к аксиомам оптимизации, должен понимать теорию дискретного отклика (QRE) как концепцию решения. Оригинальная разработка этой теории — в книгах МакКелви и Палфри (MacKelvey and Palfrey 1995, 1998). Гуири, Холт и Палфри (Goeree, Holt, Palfrey 2016) представляют исчерпывающий и наиболее свежий обзор QRE и его ведущих применений.
Философские основания базовых теоретико-игровых понятий, как их понимают экономисты, представлены в LaCasse and Ross 1994. Работа Ross and LaCasse 1995 описывает отношения между играми и аксиоматическими предпосылками микроэкономики и макроэкономики. Философские проблемы на этом фундаментальном уровне обсуждаются в критическом ключе в работе Bicchieri 1993. Льюис (Lewis 1969) широко применяет в философии понятие равновесия из теории игр, хотя и делает некоторые фундаментальные предположения, которые экономисты обычно не разделяют. Его программа на этом не остановилась и продолжилась — уже без спорных посылок — в работах Скирмса (Skyrms (1996) (**), 2004). (Также см. Nozick 1998.) Gauthier 1986 открывает список литературы, которая не упоминалась в данной статье: в этой работе исследуется возможность найти теоретико-игровые основания контрактарианской (contractarian) этике. Эта же работа критически рассматривается в Vallentyne 1991, ее же в динамическом контексте разбирает Даниэлсон (Danielson 1992). Бинмор в работах 1994 и 1998 (**) года, однако, остро критикует этот проект, считая его несогласованным с естественной психологией. Философы также проявляют интерес к работе Hollis 1998.
К отдельному классу относятся работы нобелевского лауреата Томаса Шеллинга — они отличаются проницательностью, оригинальностью, их очень легко читать и они имеют кросс-дисциплинарное значение. Шеллинг — крайне продуктивный автор, он применяет теорию игр к социальным и политическим вопросам самой непосредственной важности и показывает, как легко можно перенести математику, если логика нигде не спотыкается. Всего четыре тома, все фундаментально важны: Schelling 1960(**), 1978 / 2016(**), 1984(**), 2006(**).
Harding 1995 — один из примеров применения теории игр к проблемам прикладной политологии. Baird, Gertner and Picker 1994 — это обзор применения теории игр в юриспруденции и теории права. Mueller 1997 рассматривает применение теории игр к общественному выбору. Ghemawat 1997 предоставляет case studies, которые служат методологическими шаблонами для практического применения теории игр для решения стратегических проблем в бизнесе. Poundstone 1992 приводит крайне живую историю дилеммы заключенного и ее применения стратегами холодной войны. Amadae 2016 рассказывает ту же историю с опорой на оригинальное академическое исследование с меньшим самодовольством в том, что касается его выводов. Мемуары Эллсберга (Ellsberg 2017) по большей части подтверждают то, что удалось выяснить Amadae. Durlauf and Young 2001 — это полезный сборник статьей о применении теории игр к социальным структурам и изменениям.
Эволюционная теория игр особенно обязана своим происхождением Мэйнарду Смиту (Maynard Smith)(**). Объединение теории игр напрямую с биологией см. в Hoffbauer and Sigmung 1998(**). Сигмунт (Sigmund 1993) представляет этот материал менее технически и в более доступной форме. Некоторые увлекательные применения эволюционной теории игр к ряду философских вопросов, на которые особенно опиралась данная статья, есть в работе Skyrms 1996 (**). Эти и другие вопросы критически обсуждаются с различных углов в Danielson 1998. Математические основания эволюционной теории игр представлены в Weibull 1995, дальнейшую разработку см. в Samuelson 1997. Как уже упоминалось выше, Gintis 2009b (**) сейчас служит вводным учебником, который рассматривает эволюционную теорию игр в качестве фундамента для всей теории игр вообще. Янг (H.P. Young 1998) приводит крайне утонченные модели эволюционной динамики культурных норм в теоретико-игровых взаимодействиях агентов с ограниченными когнитивными способностями, но склонными подражать друг другу. В Fudenberg and Lavine 1998 приводится технический фундамент для моделей подобного типа.
Многих философов также заинтересуют работу Бинмора (Binmore 1994, 1998, 2005a (**)), где показывается, что применение теоретико-игрового анализа может подтвердить ролзовскую концепцию справедливости без обращения к кантианским предположениям относительно того, чего рациональные агенты будут хотеть под завесой неведения (veil of ignorance) относительно их идентичностей и социальных ролей. (Кроме того, Бинмор предлагает экскурсию по целому ряду других вопросов, как центральных, так и периферийных, как для оснований, так и фронтира теории игр; эти книги особенно богаты проблемами, которые так интересуют философов.) Почти всем будет интересна работа Франка (Frank 1998) (**), где эволюционная теория игр используется для освещения базовых свойств человеческой природы и эмоций; хотя читатели могут также ознакомиться и с критикой модели Франка в Ross and Dumouchel 2004.
Поведенческие и экспериментальные применения теории игр описываются в Kagel and Roth 1995. Camerer 2003 (**) — это исчерпывающее и более свежее исследование подобной литературы, которое нельзя пропустить никому, кто интересуется подобными вопросами. Более короткий обзор, фокусирующийся на философской и методологической критике, представлен в работе Samuelson 2005. Философские основания также тщательно исследуется в Guala 2005.
Binmore 2009 (**) и Gintis 2009a (**) — две книги ведущих теоретиков, содержащие всесторонний взгляд на философские основания теории игр, обе были опубликованы в 2009.Обе незаменимы для философов, которые хотят поучаствовать в критических дискуссия вокруг фундаментальных вопросов теории игр.
Книга интервью с 19-ю ведущими теоретиками игр, в которой раскрываются их взгляды на мотации и фундаментальные темы — Hendricks and Hansen 2007.
Крайне значимая фундаментальная разработка в теории игр —кондициональные игры, предложенные Стирлингом (Stirling 2012). Первый том ограничивается лишь математикой, указывая на возможное применение, а техническое расширение, которое перекидывает мостки к экономике, можно найти в следующем, Stirling 2016. Философское значение этой работы лучше всего понятно в свете соображений, высказанных Бакараком (Bacharach 2006).
Теоретико-игровая динамика суб-личностей получает глубокое отражение в работе Эйнсли (Ainslie 2001). Важнейшие работы в нейроэкономике, вместе с экстенсивным применением и следствиям для поведенческой теории игр содержатся в работе Montague and Berns 2002, Glimcher 2003 (**), Camerer, Loewenstein and Prelec 2005. Росс (Ross 2005a) изучает теоретико-игровые основания микроэкономики в общем, но особенно — поведенческой экономики и нейроэкономики, с позиций когнитивных наук и во многом совпадает с Эйнсли.
Теория кооперативных игр содержится в работе Chakravarty, Mitra and Sarkar 2015. Доступный и не технический обзор применения теории парообразования содержится в книге Рота (Roth 2015), экономиста, чьи исследования в этой области были удостоены Нобелевской премии.
· Ainslie, G. (1992). Picoeconomics. Cambridge: Cambridge University Press.
· ––– (2001). Breakdown of Will. Cambridge: Cambridge University Press.
· Andersen, S., Harrison, G., Lau, M., and Rutstrom, E. (2008). Eliciting risk and time preferences. Econometrica, 76: 583–618.
· Andersen, S., Harrison, G., Lau, M., and Rutstrom, E. (2014). Dual criteria decisions. Journal of Economic Psychology, forthcoming.
· Bacharach, M. (2006). Beyond Individual Choice: Teams and Frames in Game Theory. Princeton: Princeton University Press.
· Baird, D., Gertner, R., and Picker, R. (1994). Game Theory and the Law. Cambridge, MA: Harvard University Press.
· Bell, W., (1991). Searching Behaviour. London: Chapman and Hall.
· Bicchieri, C. (1993). Rationality and Coordination. Cambridge: Cambridge University Press.
· ––– (2006). The Grammar of Society. Cambridge: Cambridge University Press.
· Bickhard, M. (2008). Social ontology as convention. Topoi, 27: 139–149.
· Binmore, K. (1987). Modeling Rational Players I. Economics and Philosophy, 3: 179–214.
· ––– (1994). Game Theory and the Social Contract (v. 1): Playing Fair. Cambridge, MA: MIT Press.
· ––– (1998). Game Theory and the Social Contract (v. 2): Just Playing. Cambridge, MA: MIT Press.
· ––– (2005a). Natural Justice. Oxford: Oxford University Press.
· ––– (2005b). Economic Man—or Straw Man? Behavioral and Brain Sciences 28: 817–818.
· ––– (2005c). Playing For Real. Oxford: Oxford University Press.
· ––– (2007). Does Game Theory Work? The Bargaining Challenge. Cambridge, MA: MIT Press.
· ––– (2008). Do conventions need to be common knowledge? Topoi 27: 17–27.
· ––– (2009). Rational Decisions. Princeton: Princeton University Press.
· Binmore, K., Kirman, A., and Tani, P. (eds.) (1993). Frontiers of Game Theory. Cambridge, MA: MIT Press
· Binmore, K., and Klemperer, P. (2002). The Biggest Auction Ever: The Sale of British 3G Telcom Licenses. Economic Journal, 112: C74-C96.
· Camerer, C. (1995). Individual Decision Making. In J. Kagel and A. Roth, eds., Handbook of Experimental Economics, 587–703. Princeton: Princeton University Press.
· ––– (2003). Behavioral Game Theory: Experiments in Strategic Interaction. Princeton: Princeton University Press.
· Camerer, C., Loewenstein, G., and Prelec, D. (2005). Neuroeconomics: How Neuroscience Can Inform Economics. Journal of Economic Literature, 40: 9–64.
· Chew, S., and MaCrimmon, K. (1979). Alpha-nu Choice Theory: A Generalization of Expected Utility Theory. Working Paper No. 686, University of Columbia Faculty of Commerce and Business Administration.
· Clark, A. (1997). Being There. Cambridge, MA: MIT Press.
· Danielson, P. (1992). Artificial Morality. London: Routledge
· ––– (ed.) (1998). Modelling Rationality, Morality and Evolution. Oxford: Oxford University Press.
· Dennett, D. (1995). Darwin's Dangerous Idea. New York: Simon and Schuster.
· Dixit, A., and Nalebuff, B. (1991). Thinking Strategically. New York: Norton.
· ––– (2008). The Art of Strategy. New York: Norton.
· Dixit, A., Skeath, S., and Reiley, D. (2009). Games of Strategy, Third Edition. New York: W. W. Norton and Company.
· Dugatkin, L., and Reeve, H., eds. (1998). Game Theory and Animal Behavior. Oxford: Oxford University Press.
· Dukas, R., ed. (1998). Cognitive Ecology.. Chicago: University of Chicago Press.
· Durlauf, S., and Young, H.P., eds. (2001). Social Dynamics. Cambridge, MA: MIT Press.
· Frank, R. (1988). Passions Within Reason. New York: Norton.
· Fudenberg, D., and Levine, D. (1998). The Theory of Learning in Games. Cambridge, MA: MIT Press.
· Fudenberg, D., and Tirole, J. (1991). Game Theory. Cambridge, MA: MIT Press.
· Gauthier, D. (1986). Morals By Agreement. Oxford: Oxford University Press.
· Ghemawat, P. (1997). Games Businesses Play. Cambridge, MA: MIT Press.
· Gilbert, M. (1989). On Social Facts. Princeton: Princeton University Press.
· Ginits, H. (2000). Game Theory Evolving. Princeton: Princeton University Press.
· ––– (2004). Towards the Unity of the Human Behavioral Sciences. Philosophy, Politics and Economics, 31: 37–57.
· ––– (2005). Behavioral Ethics Meets Natural Justice. Politics, Philosophy and Economics, 5: 5–32.
· ––– (2009). The Bounds of Reason. Princeton: Princeton University Press.
· Glimcher, P. (2003). Decisions, Uncertainty and the Brain. Cambridge, MA: MIT Press.
· Glimcher, P., Kable, J., and Louie, K. (2007). Neuroeconomic studies of impulsivity: Now or just as soon as possible? American Economic Review (Papers and Proceedings), 97: 142–147.
· Guala, F. (2005). The Methodology of Experimental Economics. Cambridge: Cambridge University Press.
· Hammerstein, P. (2003). Why is reciprocity so rare in social animals? A protestant appeal. In P. Hammerstein, ed., Genetic and Cultural Evolution of Cooperation, pp. 83–93. Cambridge, MA: MIT Press.
· Hardin, R. (1995). One For All. Princeton: Princeton University Press.
· Harrison, G.W. (2008). Neuroeconomics: A critical reconsideration. Economics and Philosophy 24: 303–344.
· Harrison, G.W., and Rutstrom, E. (2008). Risk aversion in the laboratory. In Risk Aversion in Experiments, J. Cox and G. Harrison eds., Bingley, UK: Emerald, pp. 41–196.
· Harrison, G.W., and Ross, D. (2010). The methodologies of neuroeconomics. Journal of Economic Methodology 17: 185–196.
· Harsanyi, J. (1967). Games With Incomplete Information Played by ‘Bayesian’ Players, Parts I-III. Management Science 14: 159–182.
· Henrich, J., Boyd, R., Bowles, S., Camerer, C., Fehr, E., and Gintis, H., eds. (2004). Foundations of Human Sociality: Economic Experiments and Ethnographic Evidence From 15 Small-Scale Societies. Oxford: Oxford University Press.
· Henrich, J., Boyd, R., Bowles, S., Camerer, C., Fehr, E., Gintis, H., McElreath, R., Alvard, M., Barr, A., Ensminger, J., Henrich, N., Hill, K., Gil-White, F., Gurven, M., Marlowe, F., Patton, J., and Tracer, D. (2005). ‘Economic Man’ in Cross-Cultural Perspective. Behavioral and Brain Sciences, 28: 795–815.
· Hendricks, V., and Hansen, P., eds. (2007). Game Theory: 5 Questions. Automatic Press.
· Hofbauer, J., and Sigmund, K. (1998). Evolutionary Games and Population Dynamics. Cambridge: Cambridge University Press.
· Hollis, M. (1998). Trust Within Reason. Cambridge: Cambridge University Press.
· Hollis, M., and Sugden, R. (1993). Rationality in Action. Mind 102: 1–35.
· Hurwicz, L., and Reiter, S. (2006). Designing Economic Mechanisms. Cambridge: Cambridge University Press.
· Kagel, J., and Roth, A., eds. (1995). Handbook of Experimental Economics. Princeton: Princeton University Press.
· Kahneman, D., and Tversky, A. (1979). Prospect Theory: An Analysis of Decision Under Risk. Econometrica, 47: 263–291.
· Keeney, R., and Raiffa, H. (1976). Decisions With Multiple Objectives. New York: Wiley.
· King-Casas, B., Tomlin, D., Anen, C., Camerer, C., Quartz, S., and Montague, P.R. (2005). Getting to Know You: Reputation and Trust in a Two-Person Economic Exchange. Science, 308: 78–83.
· Koons, R. (1992). Paradoxes of Belief and Strategic Rationality. Cambridge: Cambridge University Press.
· Krebs, J., and Davies, N. (1984). Behavioral Ecology: An Evolutionary Approach. Second edition. Sunderland: Sinauer.
· Kreps, D. (1990). A Course in Microeconomic Theory. Princeton: Princeton University Press.
· Kuhn, H., ed., (1997). Classics in Game Theory. Princeton: Princeton University Press.
· LaCasse, C., and Ross, D. (1994). ‘The Microeconomic Interpretation of Games’. PSA 1994, Volume 1. D. Hull, S. Forbes and R. Burien, eds.. East Lansing, MI: Philosophy of Science Association, pp. 479–387.
· Ledyard, J. (1995). Public Goods: A Survey of Experimental Research. In J. Kagel and A. Roth, eds., Handbook of Experimental Economics. Princeton: Princeton University Press.
· Lewis, D. (1969). Convention. Cambridge, MA: Harvard University Press.
· Maynard Smith, J. (1982). Evolution and the Theory of Games. Cambridge: Cambridge University Press.
· McClure, S., Laibson, D., Loewenstein, G., and Cohen, J. (2004). Separate neural systems value immediate and delayed monetary rewards. Science, 306: 503–507.
· McKelvey, R., and Palfrey, T. (1995). Quantal response equilibria for normal form games. Games and Economic Behavior 10: 6–38.
· McKelvey, R., and Palfrey, T. (1998). Quantal response equilibria for extensive form games. Experimental Economics 1: 9–41.
· McMillan, J. (1991). Games, Strategies and Managers. Oxford: Oxford University Press.
· Millikan, R. (1984). Language, Thought and Other Biological Categories. Cambridge, MA: MIT Press.
· Montague,P. R., and Berns, G. (2002). Neural Economics and the Biological Substrates of Valuation. Neuron, 36: 265–284.
· Mueller, D. (1997). Perspectives on Public Choice. Cambridge: Cambridge University Press.
· Nash, J. (1950a). ‘Equilibrium Points in n-Person Games.’ Proceedings of the National Academy of Science, 36: 48–49.
· ––– (1950b). ‘The Bargaining Problem.’ Econometrica, 18: 155–162.
· ––– (1951). ‘Non-cooperative Games.’ Annals of Mathematics Journal, 54: 286–295.
· Noe, R., van Hoof, J., and Hammerstein, P., eds. (2001). Economics in Nature. Cambridge: Cambridge University Press.
· Nozick, R. (1998). Socratic Puzzles. Cambridge, MA: Harvard University Press.
· Ormerod, P. (1994). The Death of Economics. New York: Wiley.
· Pettit, P., and Sugden, R. (1989). The Backward Induction Paradox. Journal of Philosophy, 86: 169–182.
· Platt, M., and Glimcher, P. (1999). Neural Correlates of Decision Variables in Parietal Cortex. Nature, 400: 233–238.
· Plott, C., and Smith, V. (1978). An Experimental Examination of Two Exchange Institutions. Review of Economic Studies, 45: 133–153.
· Poundstone, W. (1992). Prisoner's Dilemma. New York: Doubleday.
· Quiggin,J. (1982). A Theory of Anticipated Utility. Journal of Economic Behavior and Organization, 3: 323–343.
· Rawls, J. (1971). A Theory of Justice. Cambridge, MA: Harvard University Press.
· Robbins, L. (1931). An Essay on the Nature and Significance of Economic Science. London: Macmillan.
· Ross, D. (2005a). Economic Theory and Cognitive Science: Microexplanation.. Cambridge, MA: MIT Press.
· ––– (2005b). Evolutionary Game Theory and the Normative Theory of Institutional Design: Binmore and Behavioral Economics. Politics, Philosophy and Economics, forthcoming.
· ––– (2008a). Classical game theory, socialization and the rationalization of conventions. Topoi, 27: 57–72.
· ––– (2008b). Two styles of neuroeconomics. Economics and Philosophy 24: 473–483.
· Ross, D., and Dumouchel, P. (2004). Emotions as Strategic Signals. Rationality and Society, 16: 251–286.
· Ross, D., and LaCasse, C. (1995). ‘Towards a New Philosophy of Positive Economics’. Dialogue, 34: 467–493.
· Sally, J. (1995). Conversation and Cooperation in Social Dilemmas: A Meta-analysis of Experiments From 1958 to 1992. Rationality and Society, 7: 58–92.
· Samuelson, L. (1997). Evolutionary Games and Equilibrium Selection. Cambridge, MA: MIT Press.
· ––– (2005). Economic Theory and Experimental Economics. Journal of Economic Literature, 43: 65–107.
· Samuelson, P. (1938). ‘A Note on the Pure Theory of Consumers' Behaviour.’ Economica, 5: 61–71.
· Savage, L. (1954). The Foundations of Statistics. New York: Wiley.
· Schelling, T. (1960). Strategy of Conflict. Cambridge, MA: Harvard University Press.
· ––– (1978). Micromotives and Macrobehavior. New York: Norton. Second edition 2006.
· ––– (1980). The Intimate Contest for Self-Command. Public Interest, 60: 94–118.
· ––– (1984). Choice and Consequence. Cambridge, MA: Harvard University Press.
· ––– (2006). Strategies of Commitment. Cambridge, MA: Harvard University Press.
· Selten, R. (1975). ‘Re-examination of the Perfectness Concept for Equilibrium Points in Extensive Games.’ International Journal of Game Theory, 4: 22–55.
· Sigmund, K. (1993). Games of Life. Oxford: Oxford University Press.
· Skyrms, B.(1996). Evolution of the Social Contract. Cambridge: Cambridge University Press.
· ––– (2004). The Stag Hunt and the Evolution of Social Structure. Cambridge: Cambridge University Press.
· Smith, V. (1962). An Experimental Study of Competitive Market Behavior. Journal of Political Economy, 70: 111–137.
· ––– (1964). Effect of Market Organization on Competitive Equilibrium. Quarterly Journal of Economics, 78: 181–201.
· ––– (1965). Experimental Auction Markets and the Walrasian Hypothesis. Journal of Political Economy, 73: 387–393.
· ––– (1976). Bidding and Auctioning Institutions: Experimental Results. In Y. Amihud, ed., Bidding and Auctioning for Procurement and Allocation, 43–64. New York: New York University Press.
· ––– (1982). Microeconomic Systems as an Experimental Science. American Economic Review, 72: 923–955.
· ––– (2008). Rationality in Economics. Cambridge: Cambridge University Press.
· Sober, E., and Wilson, D.S. (1998). Unto Others. Cambridge, MA: Harvard University Press.
· Sterelny, K. (2003). Thought in a Hostile World. Oxford: Blackwell.
· Stirling, W. (2012). Theory of Conditional Games. Cambridge: Cambridge University Press.
· Stratmann, T. (1997). Logrolling. In D. Mueller, ed., Perspectives on Public Choice, 322–341. Cambridge: Cambridge University Press.
· Strotz, R. (1956). Myopia and Inconsistency in Dynamic Utility Maximization. The Review of Economic Studies, 23: 165–180.
· Sugden, R. (1993). Thinking as a Team: Towards an Explanation of Nonselfish Behavior. Social Philosophy and Policy 10: 69–89.
· ––– (2000). Team Preferences. Economics and Philosophy 16: 175–204.
· ––– (2003). The Logic of Team Reasoning. Philosophical Explorations 6: 165–181.
· Thurstone, L. (1931). The Indifference Function. Journal of Social Psychology, 2: 139–167.
· Tomasello, M., M. Carpenter, J. Call, T. Behne and H. Moll (2004). Understanding and Sharing Intentions: The Origins of Cultural Cognition. Behavioral and Brain Sciences, 28: 675–691.
· Vallentyne, P. (ed.). (1991). Contractarianism and Rational Choice. Cambridge: Cambridge University Press.
· von Neumann, J., and Morgenstern, O., (1944). The Theory of Games and Economic Behavior. Princeton: Princeton University Press.
· von Neumann, J., and Morgenstern, O., (1947). The Theory of Games and Economic Behavior, second edition, Princeton: Princeton University Press.
· Weibull, J. (1995). Evolutionary Game Theory. Cambridge, MA: MIT Press.
· Yaari, M. (1987). The Dual Theory of Choice Under Risk. Econometrica, 55: 95–115.
· Young, H.P. (1998). Individual Strategy and Social Structure. Princeton: Princeton University Press.
.jpg)
.jpg)
.jpg)





